本文将根据前几节创建的零售场景模型,解释如何用UQL进行图查询和计算。
查询的一般思路
查询结果的可视化可以极大地增进用户对数据的理解。但人们常常会问:“表数据不是很好理解吗?” 事实上,表对于展示元数据(如点、边)查询结果而言相对经济有效,因为他们也不会展示更多除自身属性信息之外的信息,然而对于展示如路径查询、子图查询等高维多模型的数据查询结果来说,表显然不是最优解。
点查询
让我们首先通过一个简单的元数据查询,尝试理解下边的 UQL 语句:
find().nodes() as myFirstQuery
return myFirstQuery{*} limit 10
英文的字面含义:查找点,作为 myFirstQuery,返回 myFirstQuery,限制10。
以上的描述已经相当接近了,以下是更多的解释:
as的作用是为前一句 UQL 语句的执行结果定义一个别名,可以在接下来的 UQL 语句需要引用前边的执行结果时使用。- 点和边后边紧接的
{*}表明该别名代表的点和边的全部属性
UQL 可以被理解为: 找到 10 个点,返回全部属性,Manager 的执行结果为:
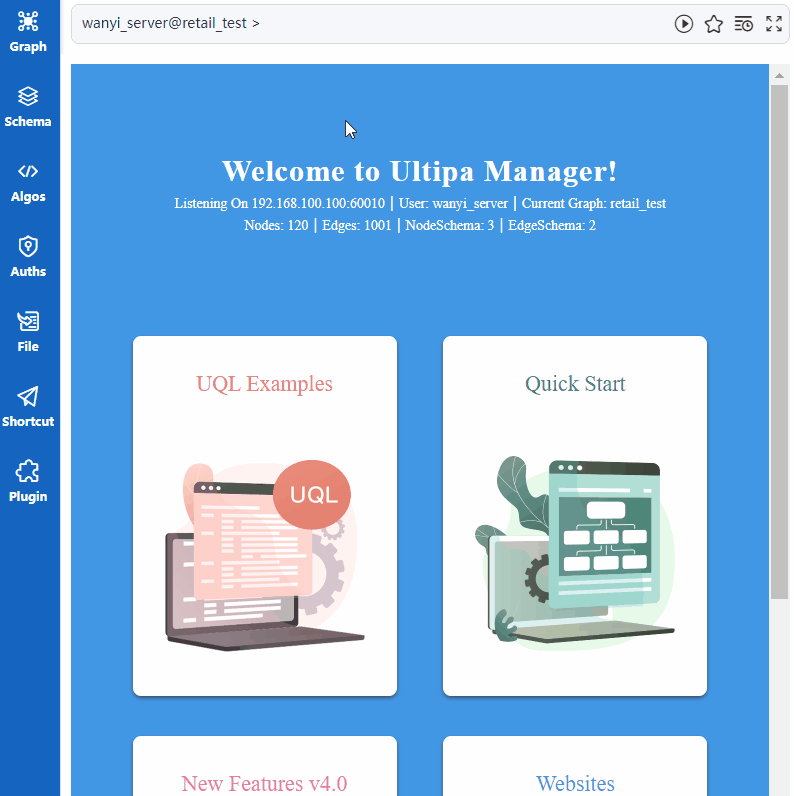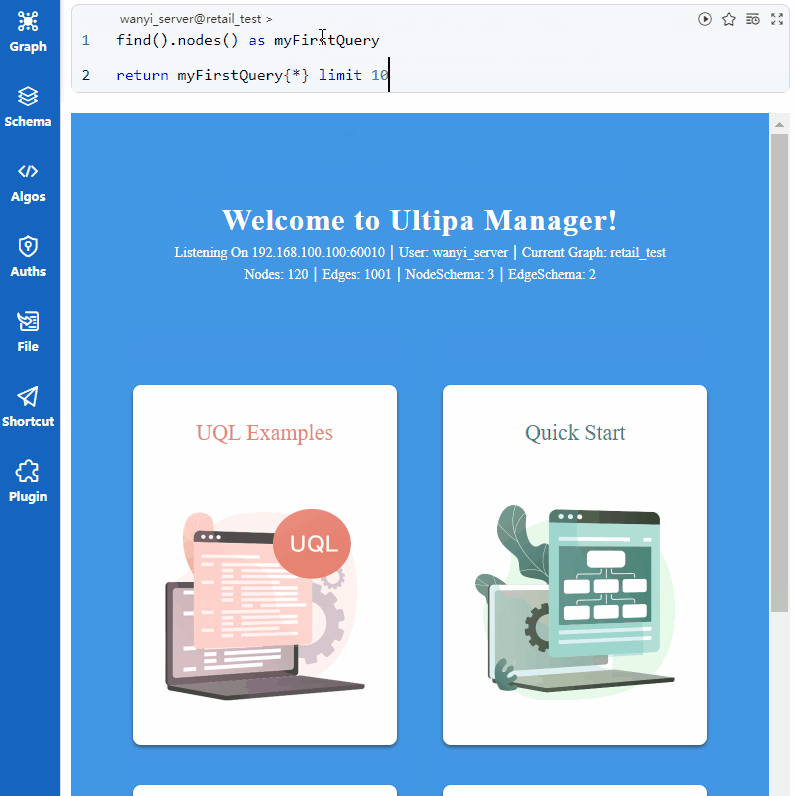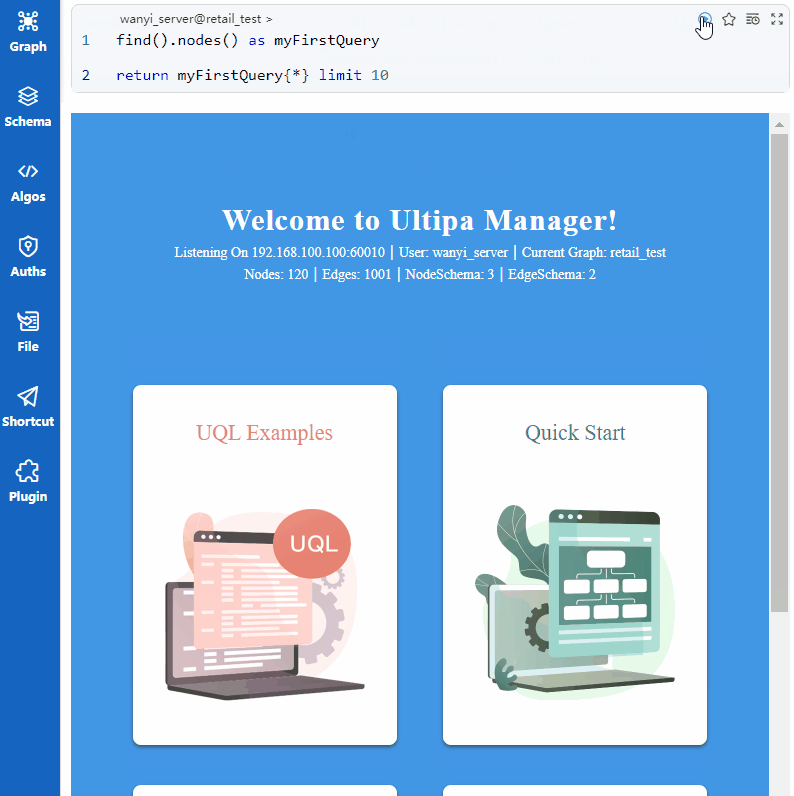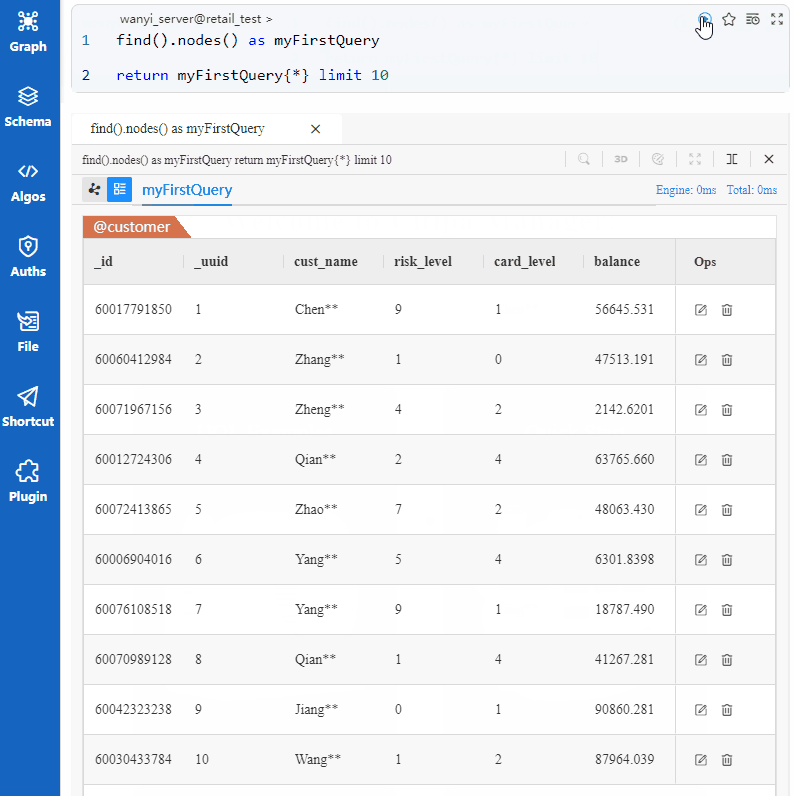
这个UQL 语句找到了 10 个@customer类型的点. 也可以通过调整筛选条件查找@merchant类型的点:
find().nodes({@merchant}) as mySecondQuery
return mySecondQuery{*} limit 10
- 在UQL语法中,
@紧跟着一个 schema 名称的表达代表该 schema 下全部的点或边。
上面的 UQL 语句可理解为:查找 10 个@merchant节点,返回它们的全部属性。在 Manager 中运行该语句可得到以下结果:
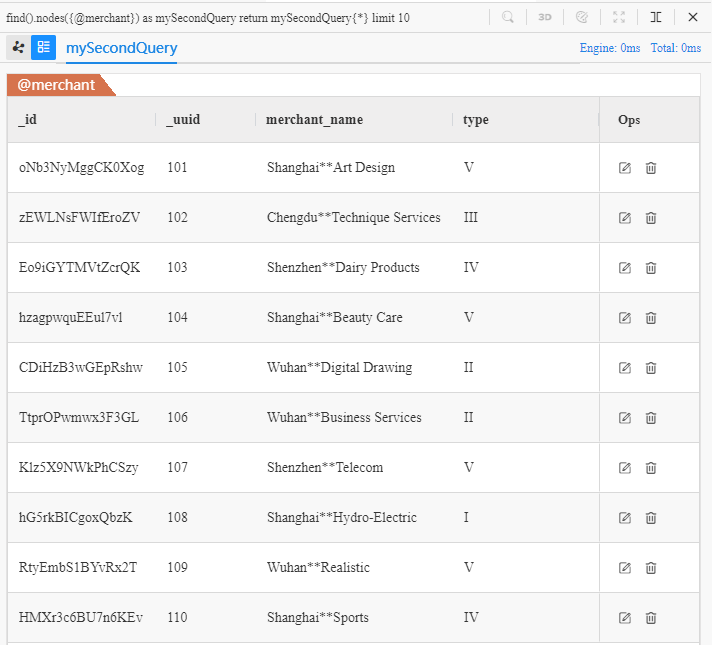
以上两句虽然分别找到了@customer、@merchant两种节点,但这两个查询结果之间可以说是毫无关联,因为在零售场景中,@customer节点是通过@transfer边向@merchant节点进行转账的:

想要让查到的@customer和@merchant有关联,需要把@transfer边也考虑进来。
边查询
尝试理解以下 UQL 语句的含义:
find().edges({_from == "60017791850"}) as payment
return payment{*} limit 10
- 本次为边查询,指定了边的起点
_from是 ID 为 60017791850 的节点。
上面的 UQL 语句可理解为:查找 10 条由 Chen**(ID 为 60017791850)发起的付款记录,返回全部属性。在 Manager 中运行该语句可得到以下结果:
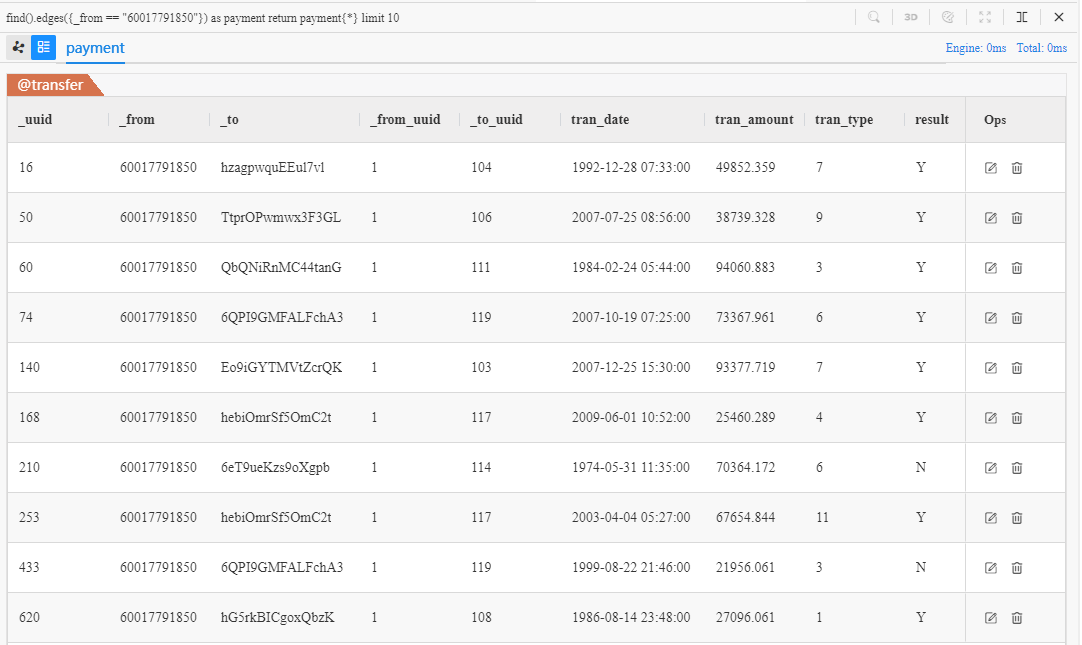
上面结果中,边的系统属性_to即为接收 Chen** 的付款的商户的 ID。改写该 UQL 语句可以进一步查询这些商户的详细信息:
find().edges({_from == "60017791850"}) as payment
find().nodes({_id == payment._to}) as merchant
return merchant{*} limit 10
- 在 UQL 语法中,别名后面紧跟着英文句号
.以及属性名称的写法表示该别名所代表的点、边的某个属性。
上面的 UQL 语句可理解为:查找 10 条由 Chen**(ID 为 60017791850)发起的付款记录,并查找接收付款的商户,返回全部属性。在 Manager 中运行该语句可得到以下结果:
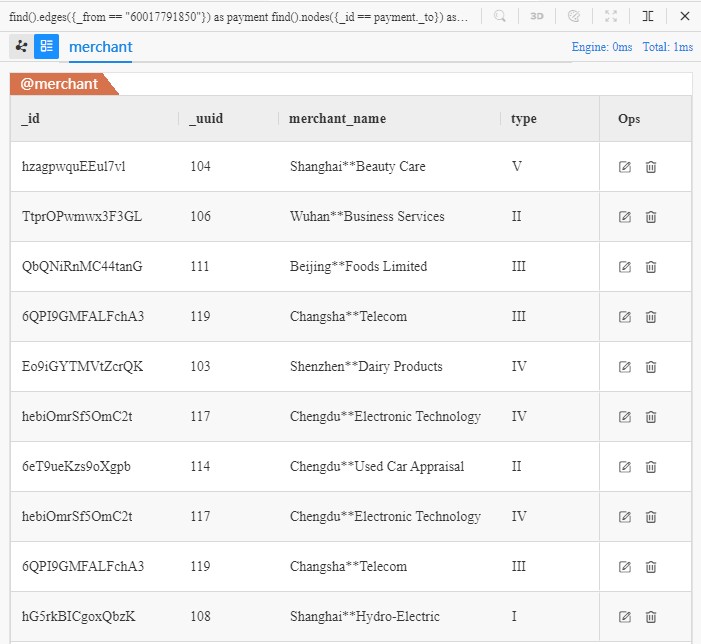
以上就是接收 10 笔付款的商户的详细信息,但仔细观察列表可以发现这 10 条数据中有两个商户重复出现了:UUID(与点的 ID 相对应,是另一种系统属性)为 117 和 119 的商户各出现了两次,原因是这两个商户各收到两笔来自 Chen** 的付款。
想要更好的观察这一现象,需要更换 UQL 命令。
展开
尝试理解以下 UQL 语句的含义:
spread().src({_id == "60017791850"}).depth(1) as transaction
return transaction{*} limit 10
英文字面意思:展开,源头的 ID 为 60017791850,深度为 1,返回所有信息,限制 10。
spread()命令可以从源头节点src()向外探寻边,从边达到新的节点后可以继续向外探寻边;depth()限制了从src()向外探寻的最远距离(边数);- 该命令返回的是 “点-边-点” 形式的一步路径,路径的别名后面紧跟着
{*}时,表示路径中所有点、边的全部属性。
上面的 UQL 语句可理解为:查找 10 条 Chen** 向商户付款的转账路径,返回这些路径中的所有点、边的全部属性。在 Manager 中运行该语句可得到以下结果:
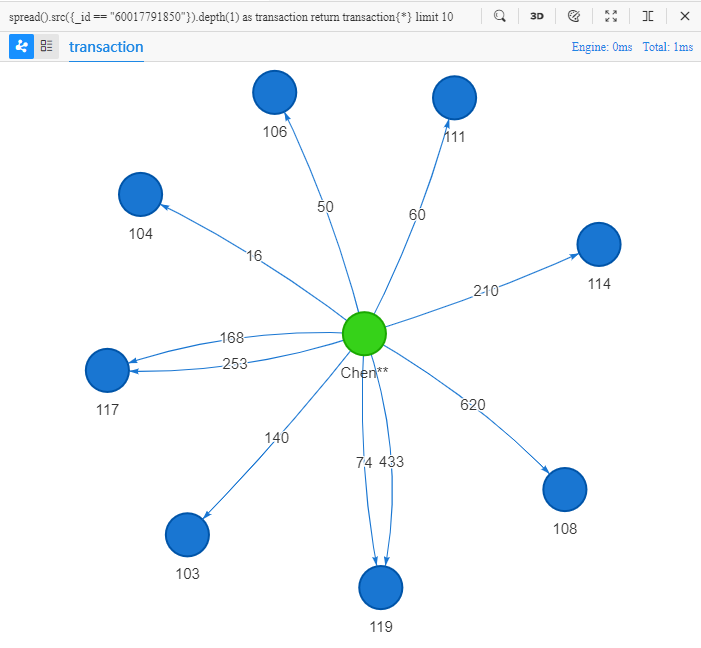
由于返回的是路径,可以在 Manager 中查看这些路径的 2D 视图,并能清楚的看到 117 和 119 这两个商户和 Chen** 之间的收付款关系。
spread()命令返回的是 10 笔不同的转账路径,而不是 10 个不同的收款商户。如果需要查询接收 Chen** 付款的 10 个不同的商户,需要再换一种 UQL 命令。
K邻
尝试理解以下 UQL 语句的含义:
khop().src({_id == "60017791850"}).depth(1) as merchant
return merchant{*} limit 10
英文字面意思:k跳,源头的 ID 为 60017791850,深度为 1,返回所有信息,限制 10。
khop()命令可以从源头节点src()向外(经过一条边)探寻点,从新的节点继续向外探寻点;- 该命令返回的是点。
上面的 UQL 语句可理解为:查找 10 个接收 Chen** 的付款的商户,返回全部属性。在 Manager 中运行该语句可得到以下结果:
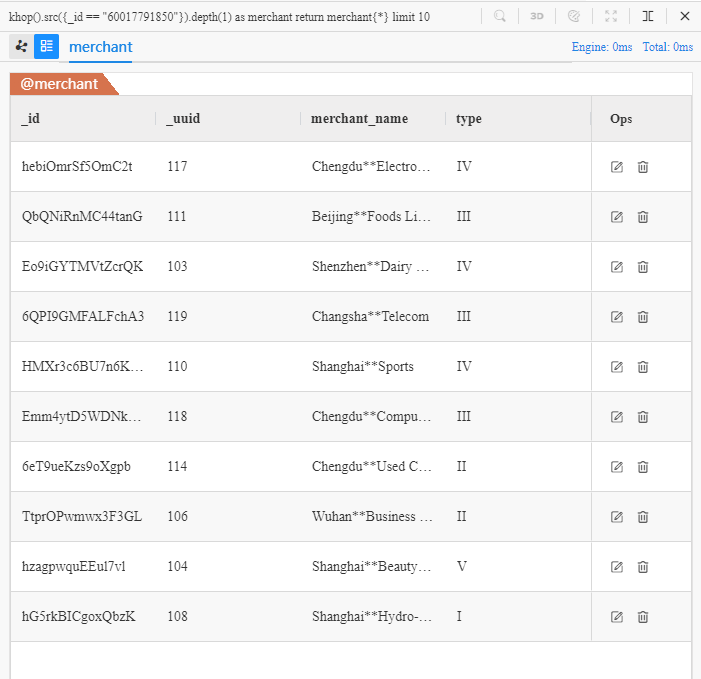
khop()命令找到了 10 个不同的收款商户,对比之前使用spread()命令找到的 10 笔付款中的 8 个收款商户,新发现的两个商户 ID 分别为 110 和 118。
模板的思维方式
前面介绍的spread()命令能够返回在展开过程中的诸多一步路径,事实上路径可以有很多步,也就是形式可以为 “点-边-点-边...-点”,有几条边(不能重复)就称为几步路径。
UQL 语法中的模板能够对路径中的每一个点、边进行精确描述,并返回查询到的整条路径。在模板命令中,n()代表一个点,e()代表一条边,e()[]代表形式为 “边-点-边-点...-边” 的片段。
链路
尝试理解以下 UQL 语句的含义:
n({_id == "60017791850"}).e().n() as transaction
return transaction{*} limit 10
英文字面意思:起点的 ID 为 60017791850,经过一条边,到达一个点,返回所有信息,限制 10。
上面的 UQL 语句可理解为:查找 10 条 Chen** 向商户付款的一步转账路径,返回这些路径中的所有点、边的全部属性。在 Manager 中运行该语句可得到以下结果:
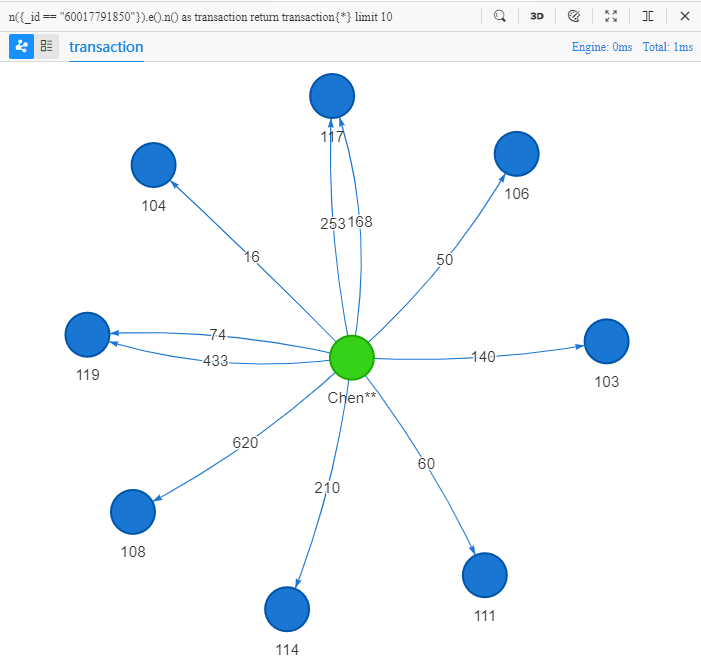
对比可发现,模板给出的结果和之前spread()命令的结果完全一致,模板完美的实现了前面spread()命令的功能。
现在考虑从 Chen** 出发、依次经过三条@transfer边、到达某个@merchant点的路径:

尝试理解以下 UQL 语句的含义:
n({_id == "60017791850"}).e({tran_amount > 70000})[3].n() as transChain
return transChain{*} limit 10
e()[3]中的三条边都要求满足转账金额大于 70000。
上面的 UQL 语句可理解为:查找 10 条从 Chen** 出发的三步转账路径,要求每一步转账的金额都大于 70000,返回这些路径中的所有点、边的全部属性。在 Manager 中运行该语句可得到以下结果:
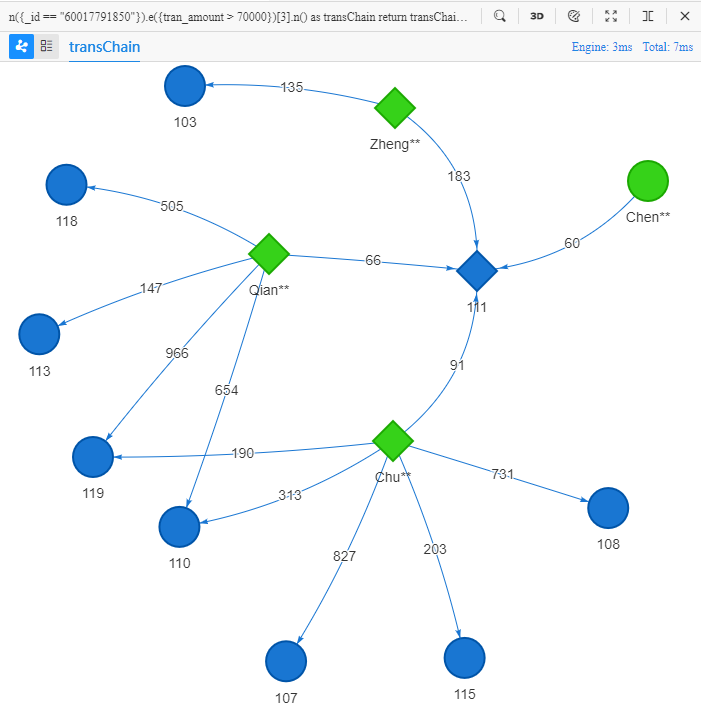
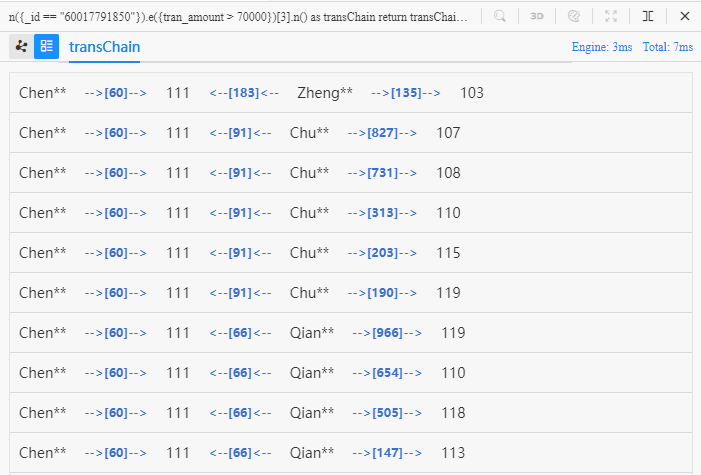
观察上图所示的从 Chen** 出发的这 10 条三步路径,它们从第二步@transfer边开始就兵分三路了,分别到达了 Zheng**、Qian**、Chu** 这三个客户,接下来的第三步@transfer边又有不同程度的发散,最终到达了 8 个不同的商户。
在零售场景中,链路查询可以帮助进行商品商户推荐、目标客户查找等。例如 Chen** 和 Zheng**、Qian**、Chu** 均购买过同一个商户的商品,如果给定更多的条件,我们就有可能从 Zheng**、Qian**、Chu** 所光顾过的其他 8 个商户中选出适合推荐给 Chen** 的商户。
Manager 的 2D 视图在显示路径时,不会重复渲染路径中重复出现的点、边。例如上面查到的 10 条路径,每一条都以 Chen** 为起点,以 “60” 为第一条边,以 “111” 为第二个点,而 2D 视图中只渲染一个 Chen**、一条 “60” 边、一个 “111” 商户。如需了解每一条路径的具体信息,可以切换至列表视图:
环路
尝试理解以下 UQL 语句的含义:
n({@customer} as start).e({tran_date > "2020-1-1 0:0:0"})[4].n(start) as transRing
return transRing{*} limit 10
英文字面意思:以一个@customer为起点,经过四条边,边上的 tran_date 晚于 2020-1-1 0:0:0,最后回到起点,返回所有信息,限制 10。
- 模板中某个
n()的别名被后面的n()直接引用时,表示这些n()是同一个点,即路径在此处形成环路。
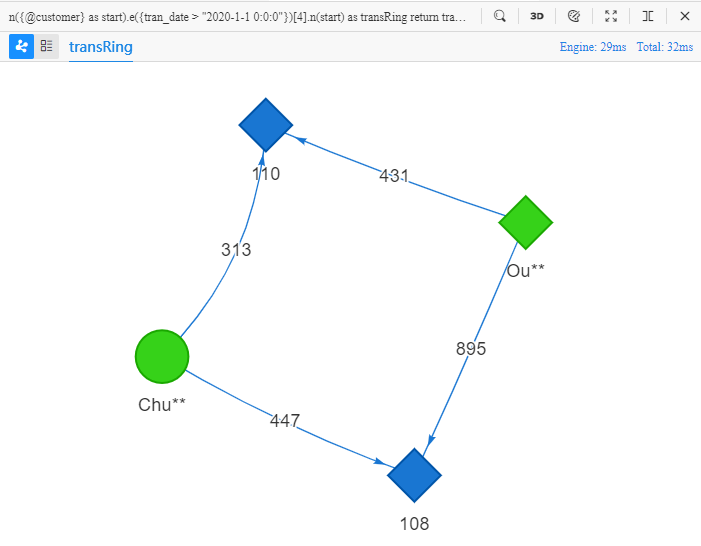
上面的 UQL 语句可理解为:查找 10 条从@customer出发的四步转账路径,要求每一步转账都发生在 2020-1-1 0:0:0 以后,并且最终回到路径起点,返回这些路径中的所有点、边的全部属性。在 Manager 中运行该语句可得到以下结果:
切换到列表视图为:
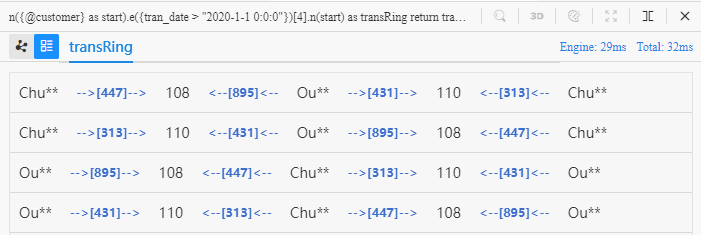
在本文所讨论的零售场景中环路均含有偶数条边,环路中的@customer、@merchant点是交替出现的,这种特性为一些相似性分析提供了借鉴依据,比如上面的四步环路中,Chu**、Ou** 都曾向 110、108 这两个商户购买商品,他们可能存在相似性,如果给定更多的限制条件,这种相似性便能逐渐清晰。
最短路
尝试理解以下 UQL 语句的含义:
n({_id == "60017791850"}).e()[:5].n(115) as transRange
return transRange{*} limit 1
:5表示e()[]中的边数不固定,但不超过 5;n()中直接填写数字时,表示将该点的 UUID 即为这个数字。
上面的 UQL 语句可理解为:查找 1 条从 Chen** 出发的不超过五步的转账路径,到达 UUID 为 115 的节点,返回这条路径中的所有点、边的全部属性。在 Manager 中运行该语句可得到以下结果:
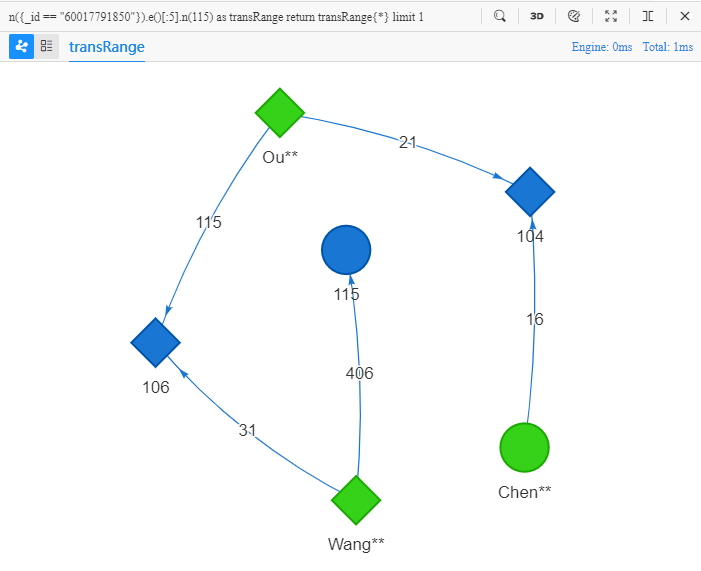
如果需要查询两个点之间的最短路径,可以对上面的 UQL 语句稍作修改:
n({_id == "60017791850"}).e()[*:5].n(115) as transShortest
return transShortest{*} limit 1
*:5表示e()[]中的边数是所有可能情况中的最小值,且不超过 5。
上面的 UQL 语句可理解为:查找 1 条从 Chen** 出发的不超过五步的、最短的转账路径,到达 UUID 为 115 的节点,返回这条路径中的所有点、边的全部属性。在 Manager 中运行该语句可得到以下结果:
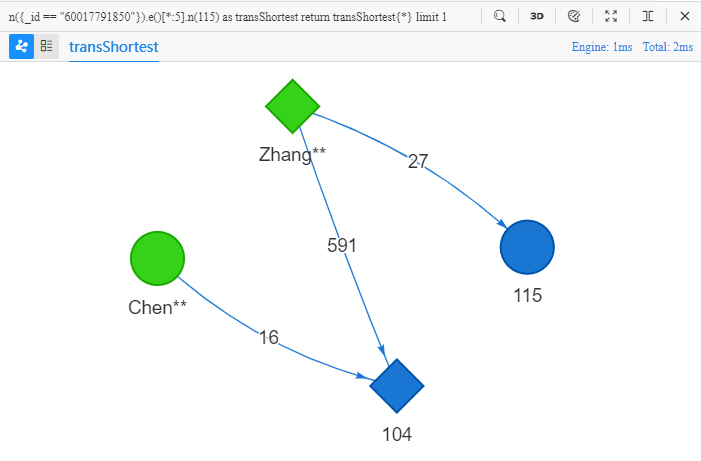
最短路径体现的是两点之间最直接的联系。一般情况下,路径越短,路径中的数据的关联性和价值也就越大。但也正是这个原因,真实世界中的某些行为会故意隐藏在很长(20~30步)的数据链路之中,意图躲过数据分析,不被发现。对这些复杂情况的处理则要求数据库拥有超深遍历的能力和快速响应的高性能。
常用运算
UQL 查到点、边、路径以后,可以进行很多运算。这些运算是通过函数、子句进行的。运算的种类非常多,具体可参看文档《Ultipa GQL-UQL》。在本节中仅挑选一些较常用的运算进行介绍。
去重
上一节中模板的第一个例子查找了 10 条 Chen** 向商户付款的一步转账路径。这 10 条路径中不重复的商户只有 8 个,现在修改原语句,返回这 8 个商户:
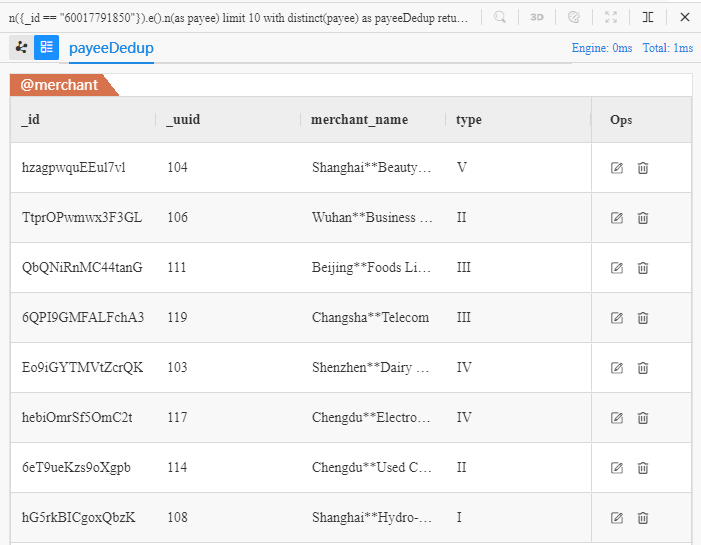
n({_id == "60017791850"}).e().n(as payee) limit 10
with distinct(payee) as payeeDedup
return payeeDedup{*}
distinct()函数可以对一列查询结果进行去重;- 函数运算需要写在子句中,如
with子句; limit 10位于distinct()之前时,先查找 10 条结果再进行去重,位于distinct()之后则是先去重再返回 10 条去重后的结果。
在 Manager 中运行该语句可得到以下结果:
计数
对于长度未知的数据列,可以使用聚合函数来统计数据列的长度:
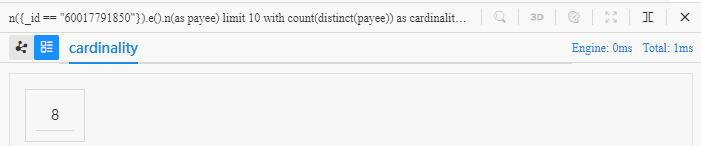
n({_id == "60017791850"}).e().n(as payee) limit 10
with count(distinct(payee)) as cardinality
return cardinality
count()函数可以对一列查询结果进行数量统计。
在 Manager 中运行该语句可得到以下结果:
排序
将之前的边查询的结果根据转账金额进行排序,要求降序排列:
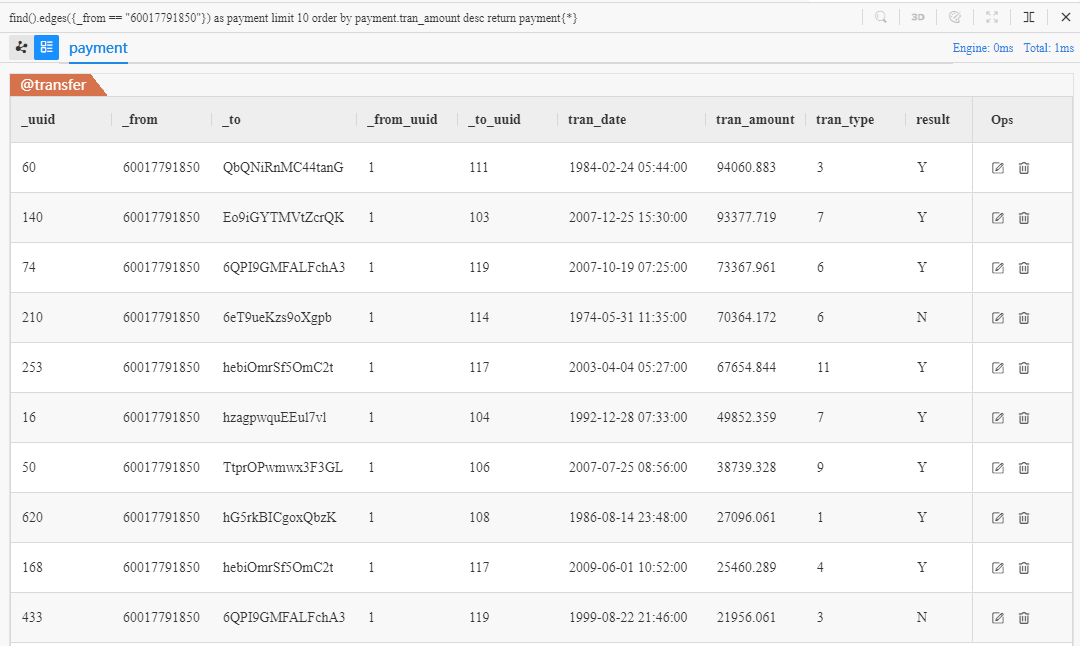
find().edges({_from == "60017791850"}) as payment limit 10
order by payment.tran_amount desc
return payment{*}
order by子句可以对一列查询结果进行排序,其后为排序依据,desc表示按降序排列。
在 Manager 中运行该语句可得到以下结果:
分组
将之前的三步转账路径的查询结果根据路径中的第三个点进行分组,统计每组的路径数量:
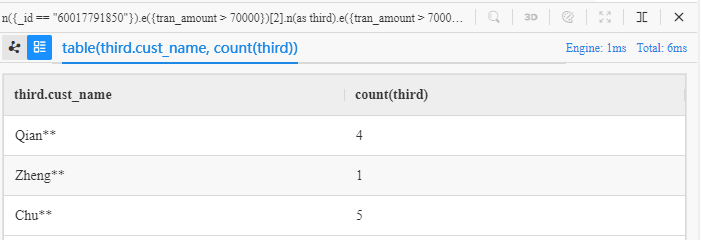
n({_id == "60017791850"}).e({tran_amount > 70000})[2].n(as third).e({tran_amount > 70000}).n() limit 10
group by third
return table(third.cust_name, count(third))
- 为了给路径中第三个点分定义别名,需要将其从原先的
e()[3]分解为e()[2].n().e(); group by子句可以对一列查询结果进行分组,其后为分组依据;table()函数可以将多个数据列合并到一个表格中,使结果更加一目了然。
在 Manager 中运行该语句可得到以下结果: