概述
UNCOLLECT子句将一个列表中的元素展开,每个元素单独占一行,同时其同源数据相应复制为多行。展开后的数据流长度等于原数据流内各行列表展开后的长度之和。
语法
UNCOLLECT <expression> as <alias>, <expression> as <alias>, ...
<expression>是要展开的列表<alias>是为展开结果定义的别名,不可省略
同时展开多个列表数据流时,同行的列表展开的最终行数以该行内元素数量最多的列表为准,不足的以null填补。
举例:将path(共2行)中的点收集到a1(共2行)后,展开a1得到a2(共6行),与此同时,与a1同源的path中的数据行相应地被复制,也变成6行:
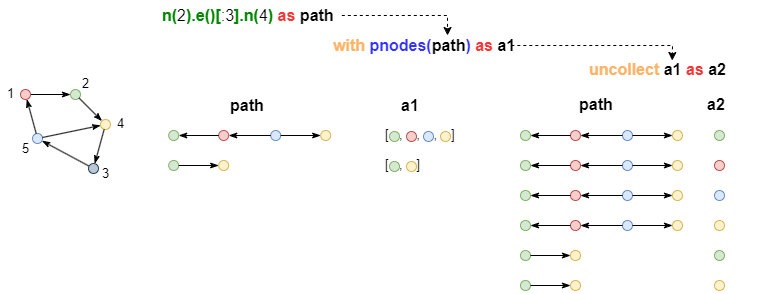
n(2).e()[:3].n(4) as path
with pnodes(path) as a1
uncollect a1 as a2
return path, a2
举例:同时展开列表数据流s1和s2,由于行内的列表长度不相同,故s2中第一行的[1,2]需用null填补,s1中第二行的["d","e"]需用null填补:
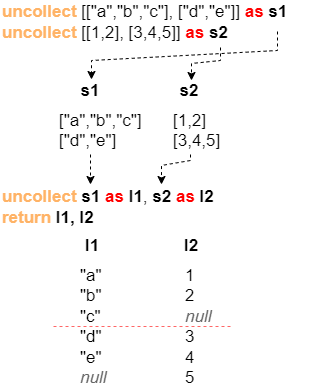
uncollect [["a","b","c"],["d","e"]] as s1
uncollect [[1,2],[3,4,5]] as s2
uncollect s1 as l1, s2 as l2
return l1, l2
示例
示例图集
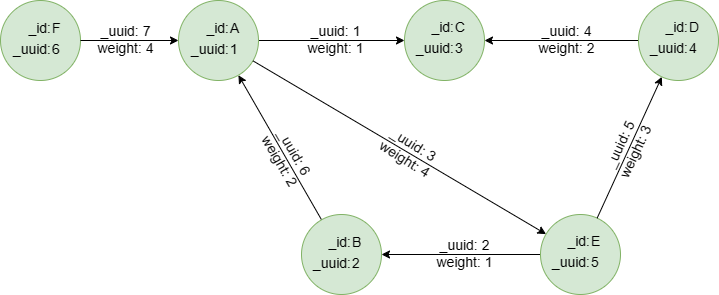
在一个空图集中,依次运行以下各行语句创建示例图集:
create().edge_property(@default, "weight", int32)
insert().into(@default).nodes([{_id:"A", _uuid:1}, {_id:"B", _uuid:2}, {_id:"C", _uuid:3}, {_id:"D", _uuid:4}, {_id:"E", _uuid:5}, {_id:"F", _uuid:6}])
insert().into(@default).edges([{_uuid:1, _from_uuid:1, _to_uuid:3, weight:1}, {_uuid:2, _from_uuid:5, _to_uuid:2 , weight:1}, {_uuid:3, _from_uuid:1, _to_uuid:5 , weight:4}, {_uuid:4, _from_uuid:4, _to_uuid:3 , weight:2}, {_uuid:5, _from_uuid:5, _to_uuid:4 , weight:3}, {_uuid:6, _from_uuid:2, _to_uuid:1 , weight:2}, {_uuid:7, _from_uuid:6, _to_uuid:1 , weight:4}])
一般用法
本例查找从A到D的2步路径,将路径上的点去重后返回它们的全部信息:
n({_id == "A"}).e()[2].n({_id == "D"}) as p
uncollect pnodes(p) as a
with dedup(a) as b
return b{*}
| _id | _uuid |
|-----|-------|
| A | 1 |
| C | 3 |
| D | 4 |
| E | 5 |