概述
UNION子句将两个RETURN子句中的同名返回值进行首尾拼接。由于不对完整的返回结果进行去重,其效率高于UNION子句。
语法
...
RETURN <expression_A> as <alias1>, <expression_B> as <alias2>, ...
UNION ALL
...
RETURN <expression_C> as <alias1>, <expression_D> as <alias2>, ...
<expression_>是返回值表达式,要求为每个返回值定义别名- 两个RETURN子句中定义的别名数量和名称要一致,别名定义的顺序可以不一样
- UNION ALL将两个RETURN中的同名返回值进行拼接,即
- 第一个RETURN中的
<alias1>与第二个RETURN中的<alias1>拼接 - 第一个RETURN中的
<alias2>与第二个RETURN中的<alias2>拼接 - 依此类推
- 第一个RETURN中的
- 同名返回值的数据类型必须相同,即
<expression_A>和<expression_C>的数据类型必须相同<expression_B>和<expression_D>的数据类型必须相同- 依此类推
例如,将两个RETURN子句中的异源别名L1和L2分别进行拼接:
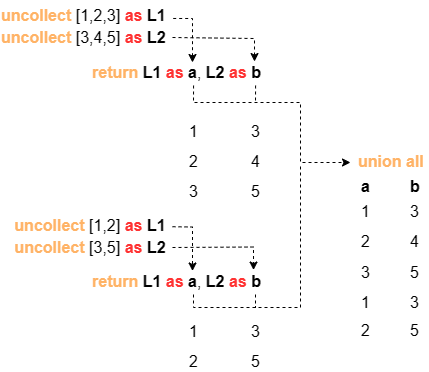
uncollect [1,2,3]) as L1
uncollect [3,4,5]) as L2
return L1 as a, L2 as b
union all
uncollect [1,2]) as L1
uncollect [3,5]) as L2
return L1 as a, L2 as b
示例
示例图集
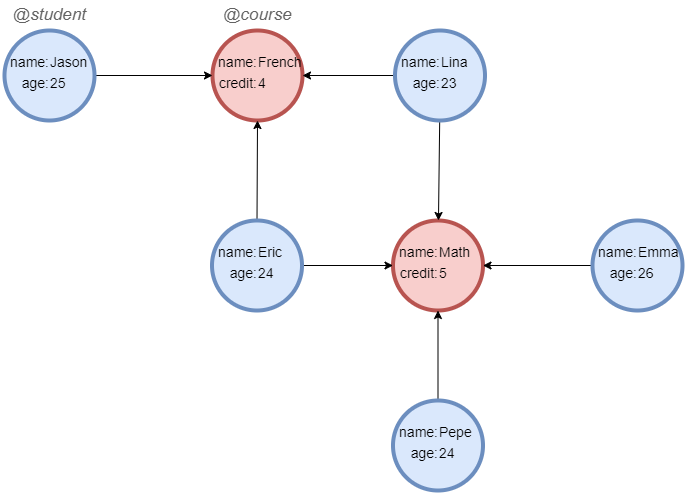
在一个空图集中,依次运行以下各行语句创建示例图集:
create().node_schema("student").node_schema("course")
create().node_property(@*, "name").node_property(@student, "age", int32).node_property(@course, "credit", int32)
insert().into(@student).nodes([{_id:"S001", _uuid:1, name:"Jason", age:25}, {_id:"S002", _uuid:2, name:"Lina", age:23}, {_id:"S003", _uuid:3, name:"Eric", age:24}, {_id:"S004", _uuid:4, name:"Emma", age:26}, {_id:"S005", _uuid:5, name:"Pepe", age:24}])
insert().into(@course).nodes([{_id:"C001", _uuid:6, name:"French", credit:4}, {_id:"C002", _uuid:7, name:"Math", credit:5}])
insert().into(@default).edges([{_uuid:1, _from_uuid:1, _to_uuid:6}, {_uuid:2, _from_uuid:2, _to_uuid:6}, {_uuid:3, _from_uuid:3, _to_uuid:6}, {_uuid:4, _from_uuid:2, _to_uuid:7}, {_uuid:5, _from_uuid:3, _to_uuid:7}, {_uuid:6, _from_uuid:4, _to_uuid:7}, {_uuid:7, _from_uuid:5, _to_uuid:7}])
一般用法
本例查找选择了法语课的24岁以下(含)学生,以及选择了数学课的24岁以上(含)学生,返回这些学生的name属性但不去重:
n({@course.name == "French"}).e().n({@student.age <= 24} as n) return n.name as a
union all
n({@course.name == "Math"}).e().n({@student.age >= 24} as n) return n.name as a
Lina
Eric
Pepe
Eric
Emma