本文介绍如何使用嬴图Manager、嬴图Transporter-Importer两种工具将图数据批量导入到图集中。
本文使用的图数据与准备图集中图一所示的图模型相匹配。
数据文件
把图模型中每个Schema的数据分别准备成一个CSV文件,即CUSTOMER.csv、MERCHANT.csv和TRANSACTION.csv。(点击可下载)
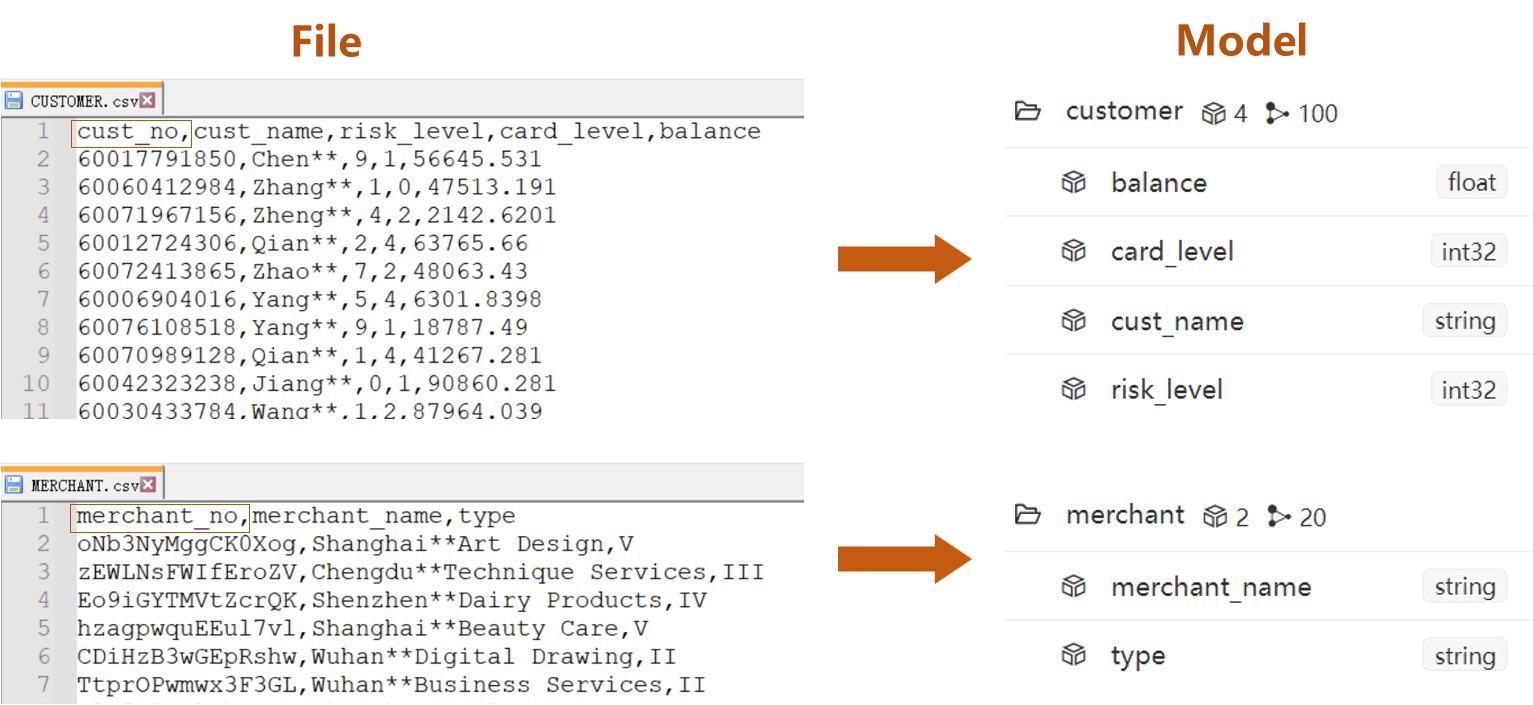
- 点文件CUSTOMER.csv中的
cust_no列、MERCHANT.csv中的merchant_no列代表点的系统属性_id - 其他列均为点的自定义属性
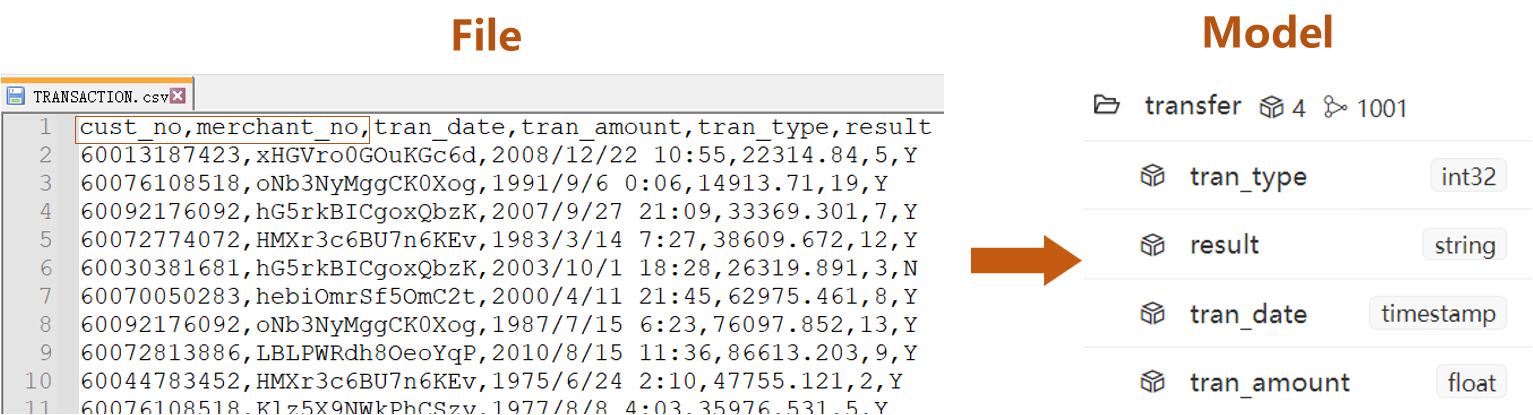
- 边文件TRANSACTION.csv中的
cust_no、merchant_no两列分别代表边的系统属性_from、_to - 其他列均为边的自定义属性
使用嬴图Manager导入
- 请确保先导入点再导入边
步骤分解(点)
以导入CUSTOMER.csv为例,导入分为以下五个步骤:
- 创建Loader
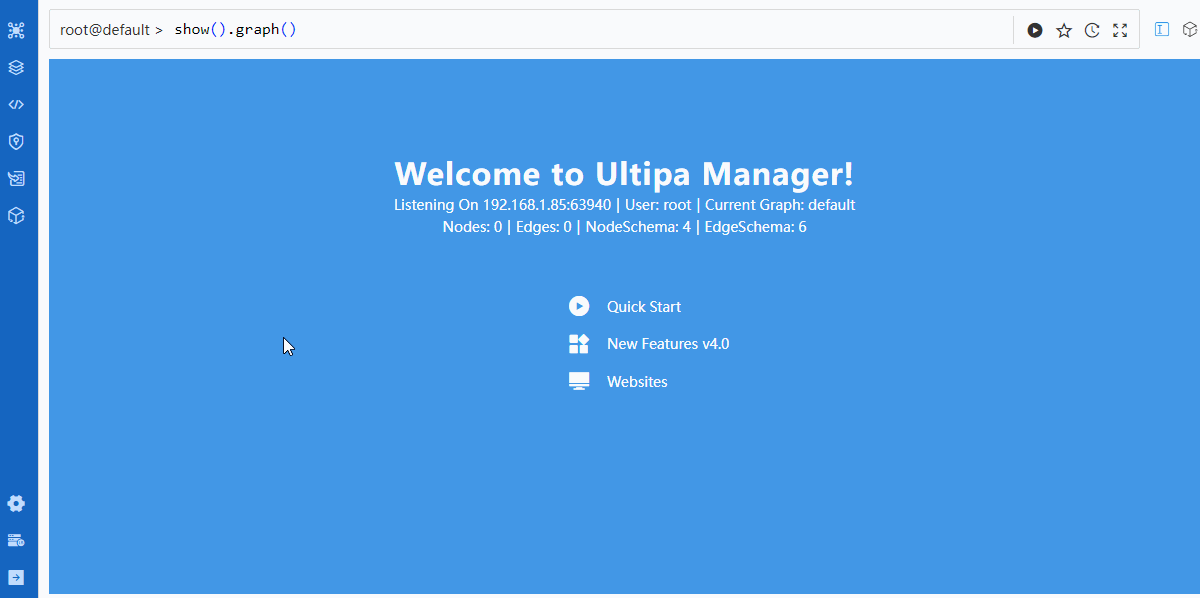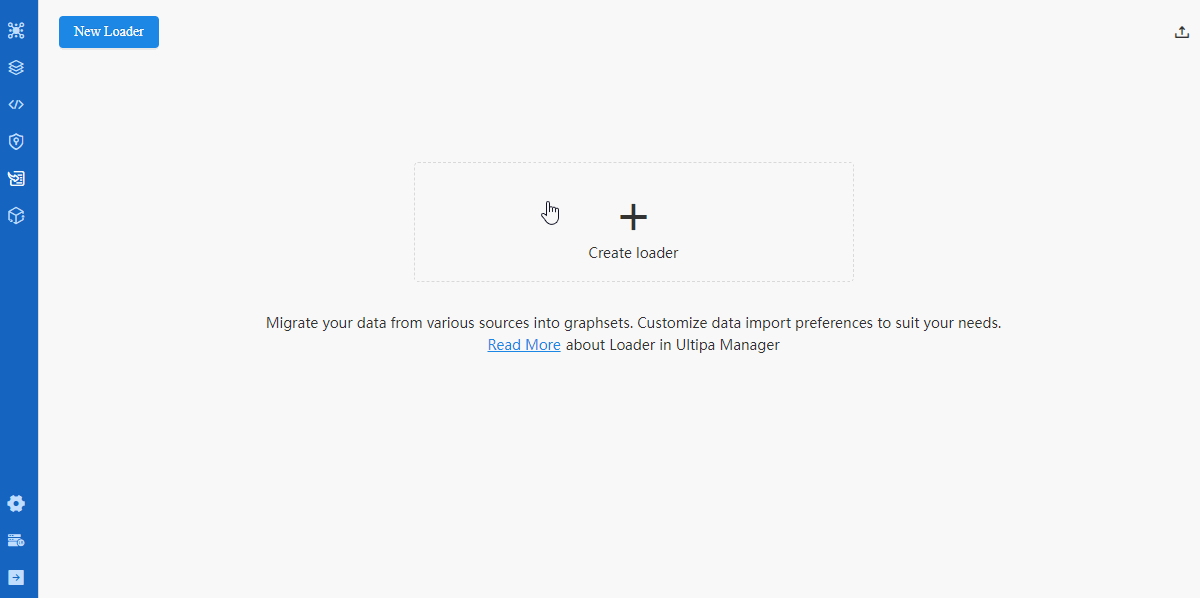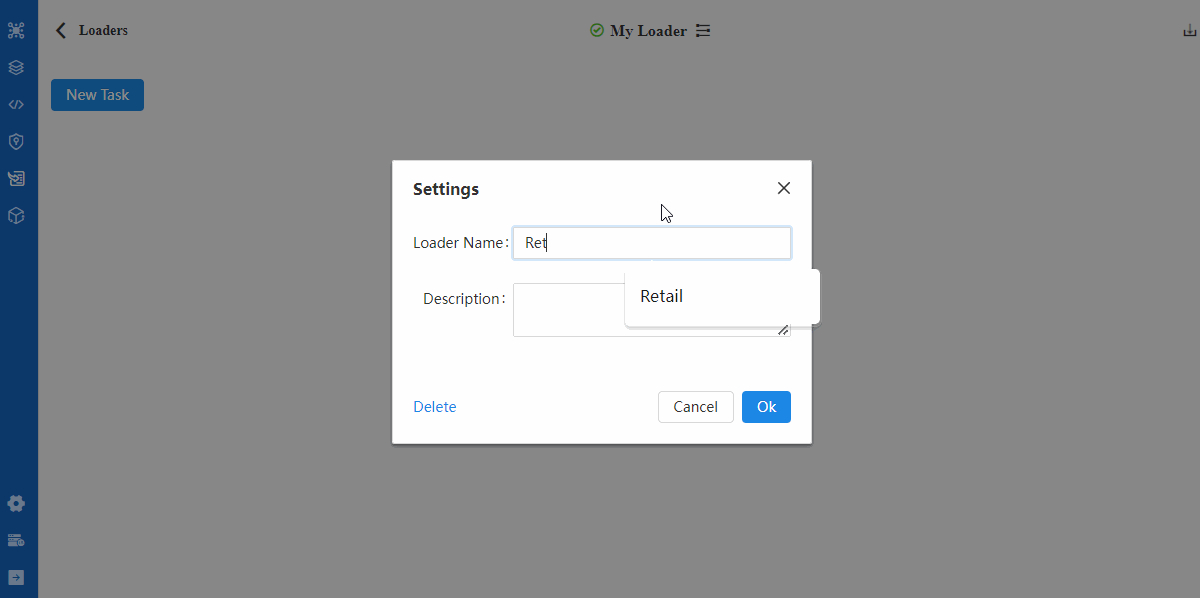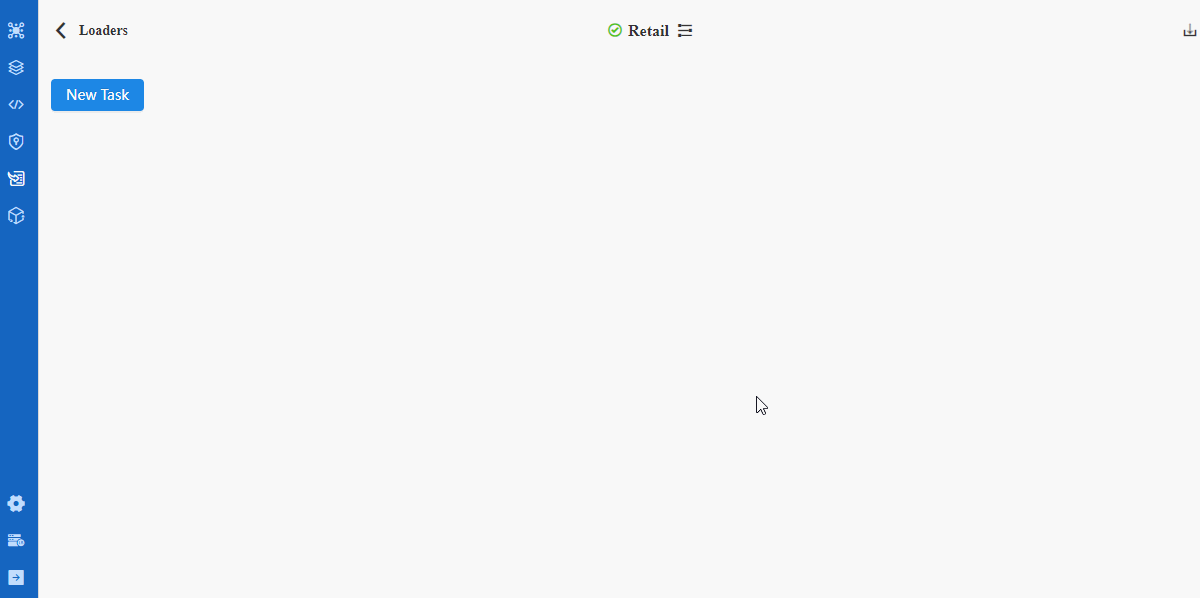
- 创建Task
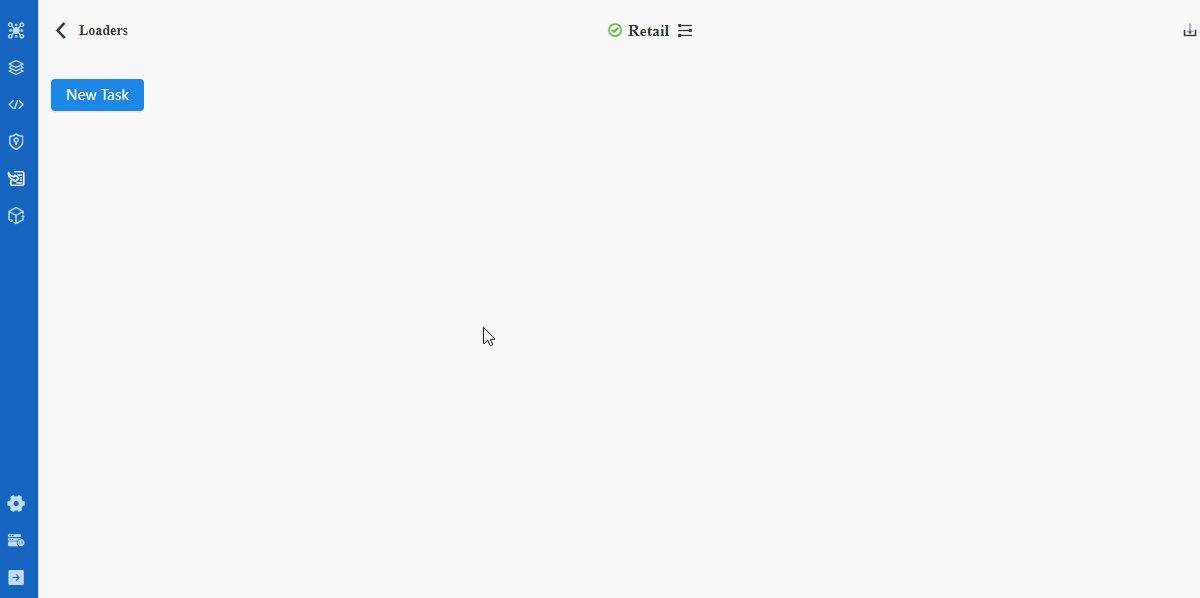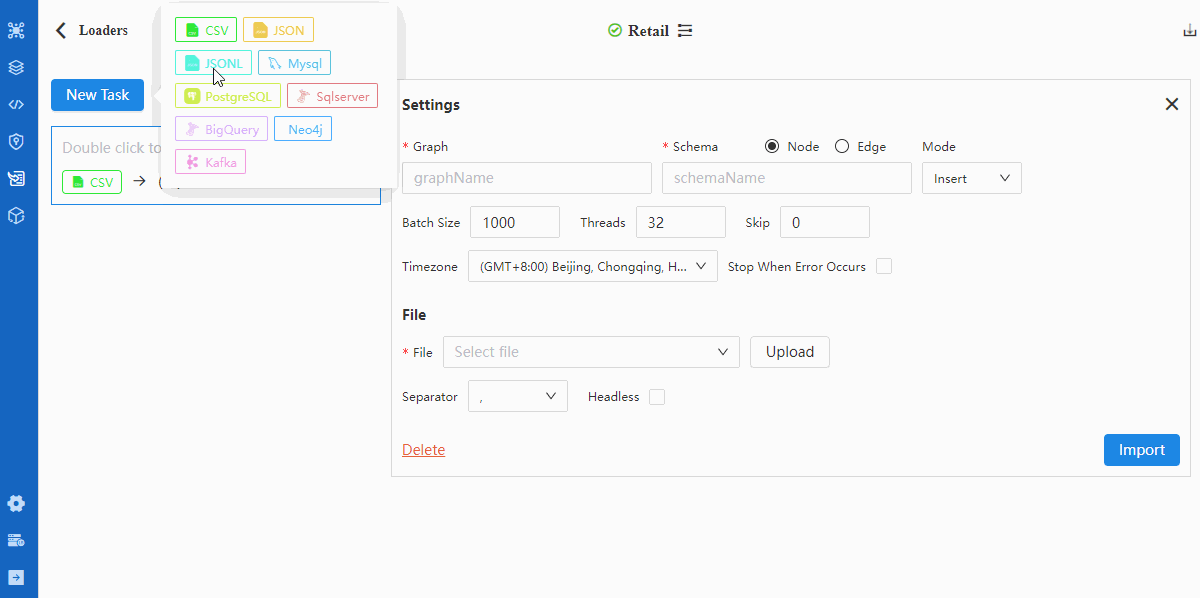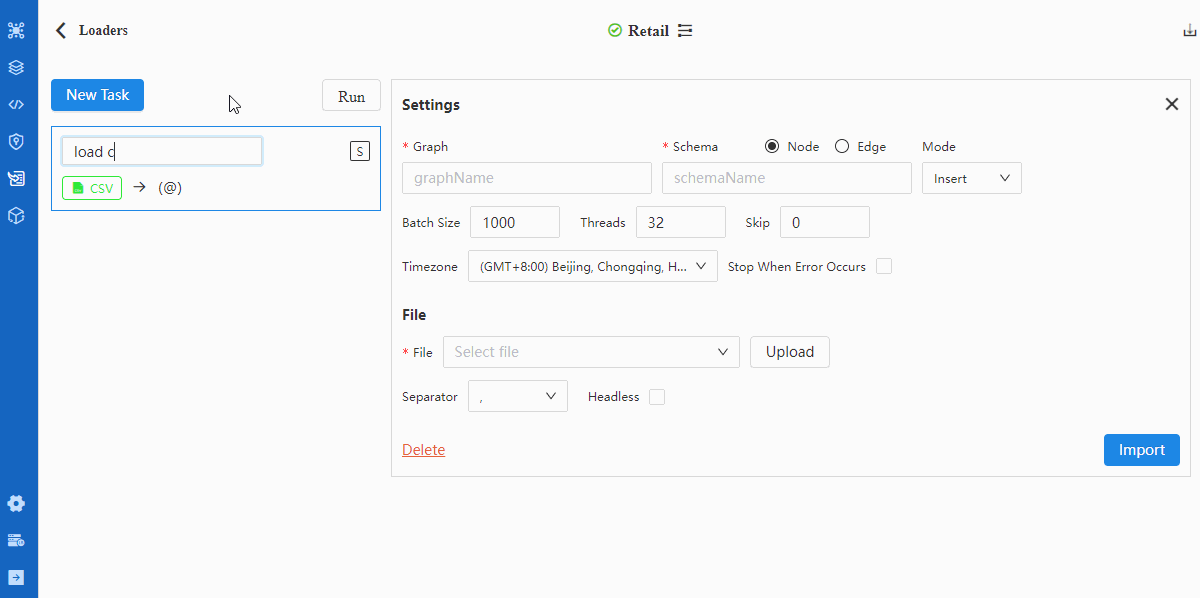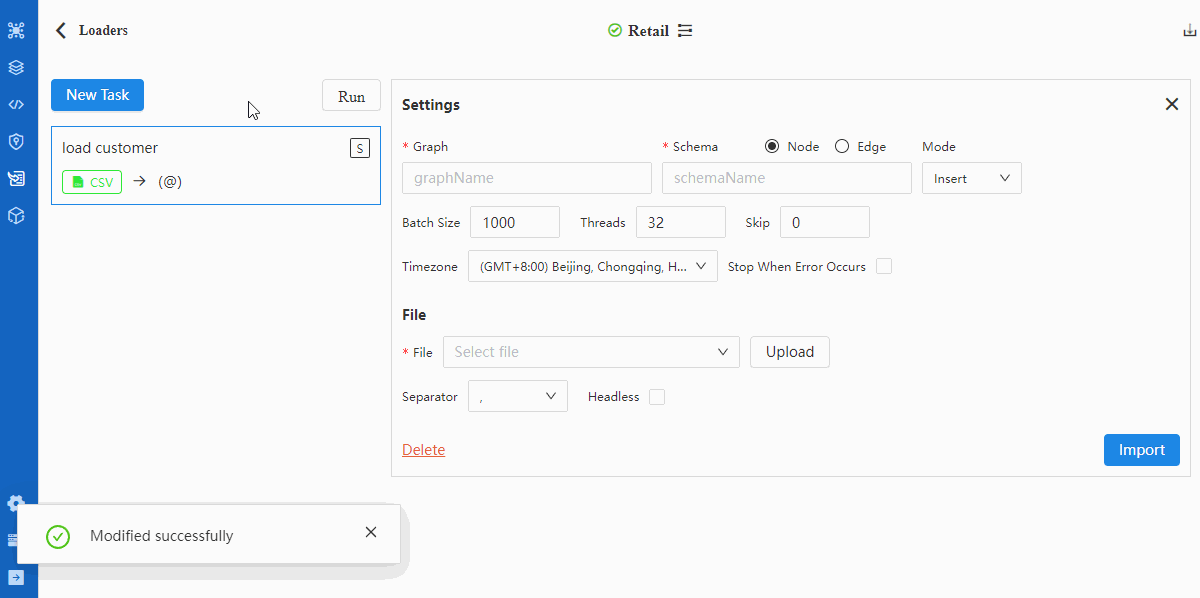
- 配置Settings
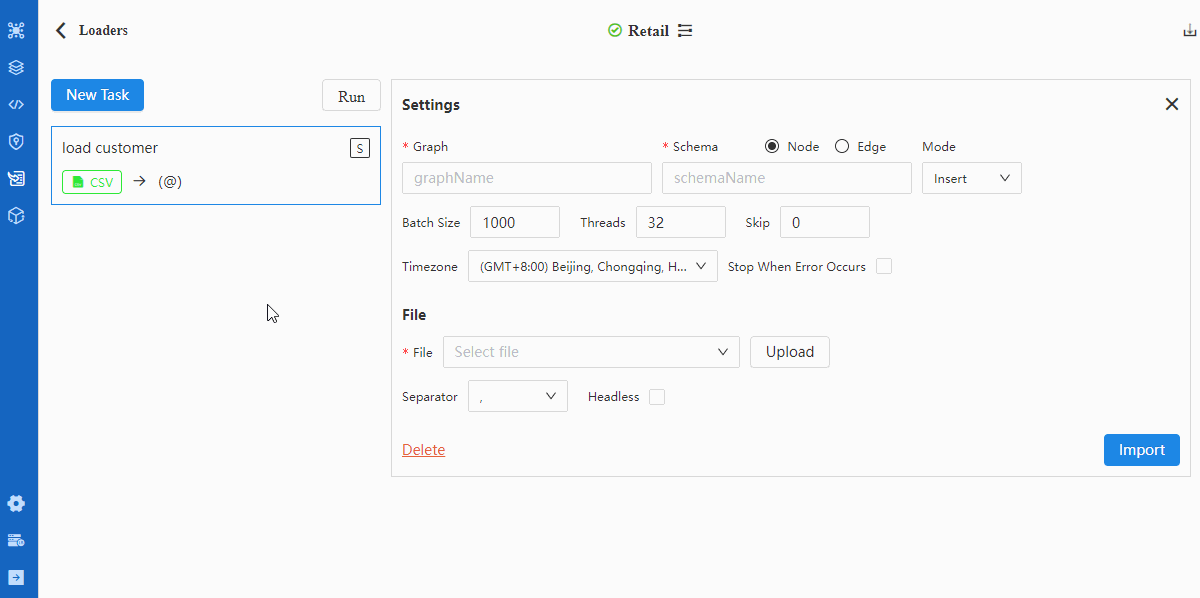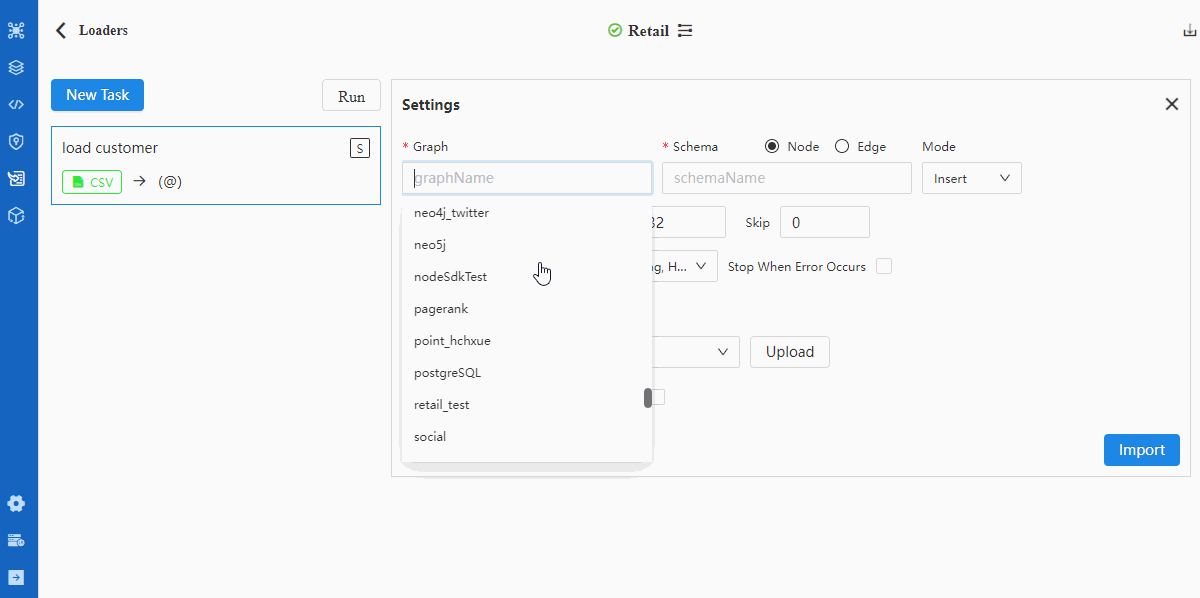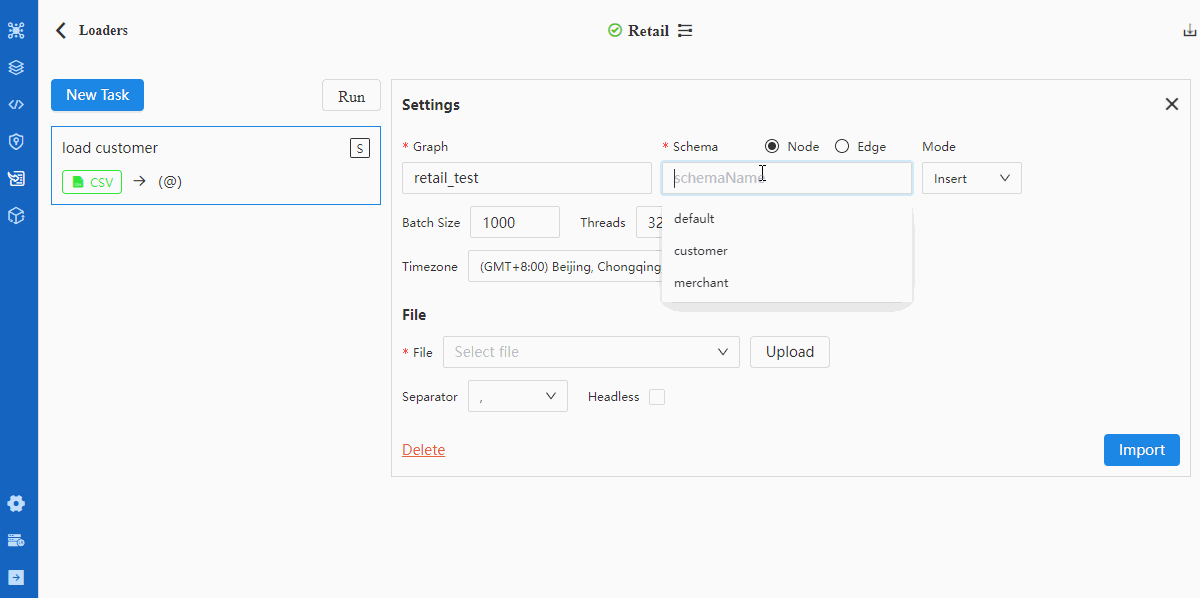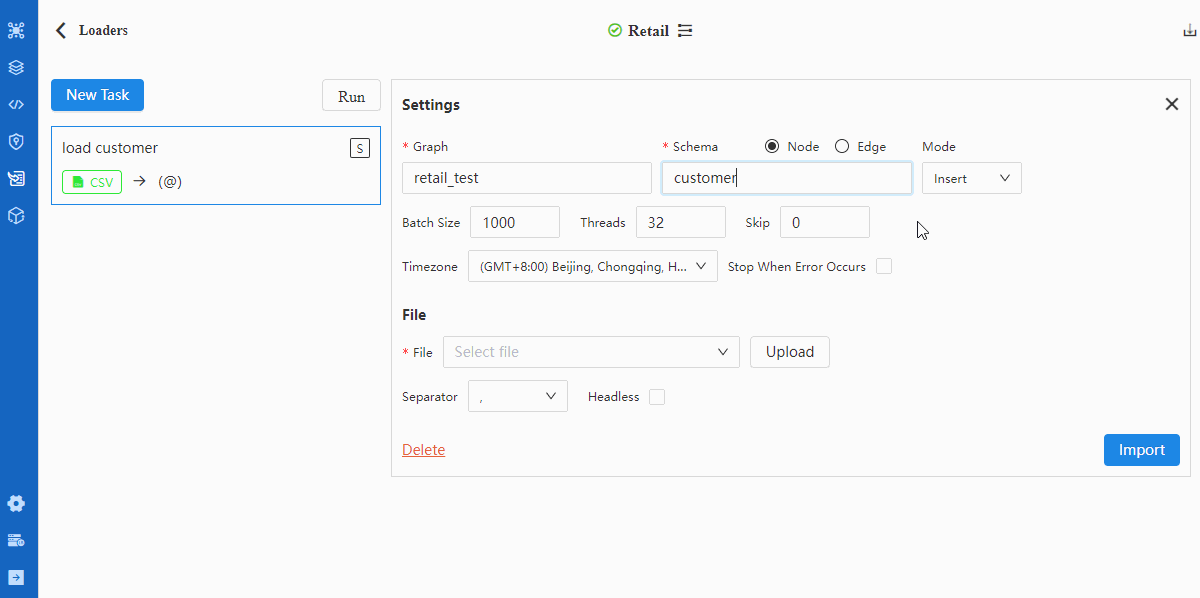
关于Settings中所有配置项的含义,请阅读入图
- 配置File
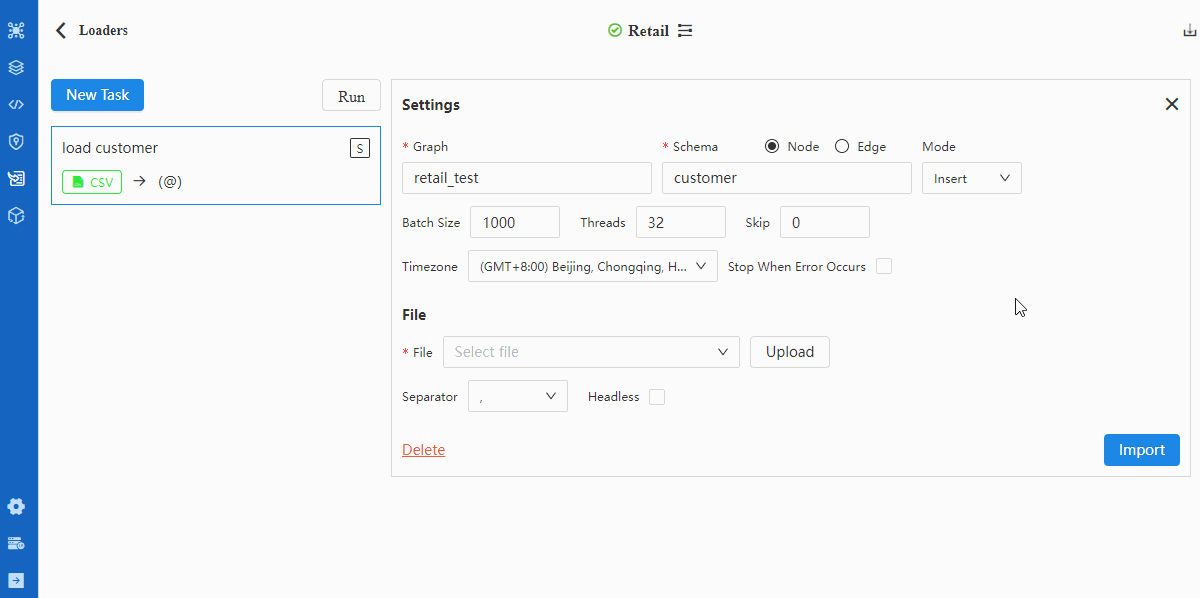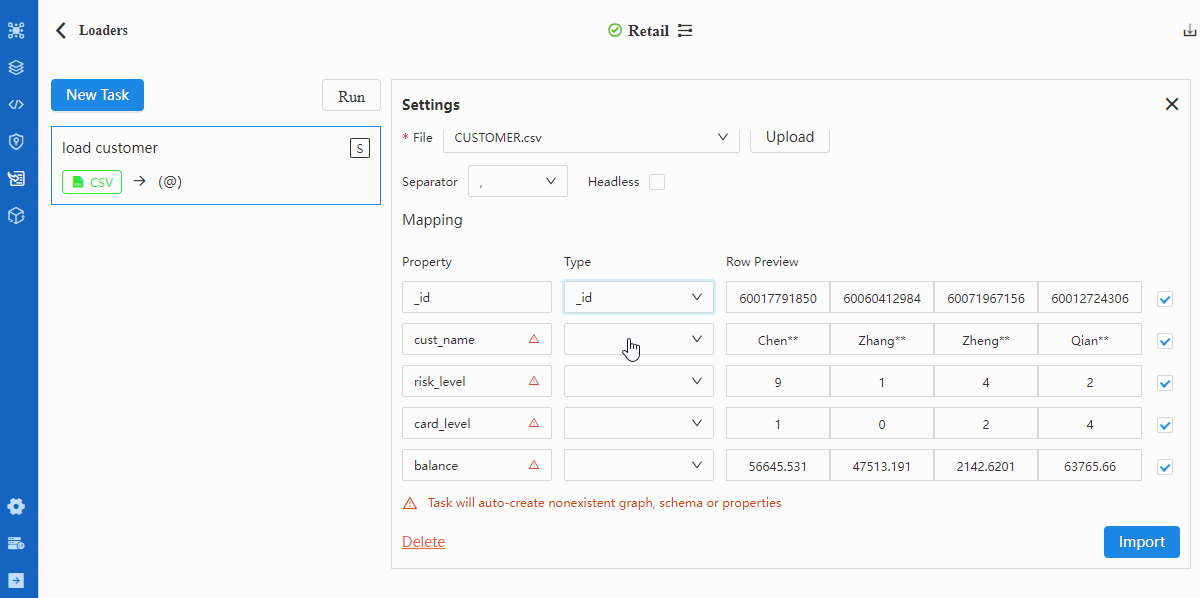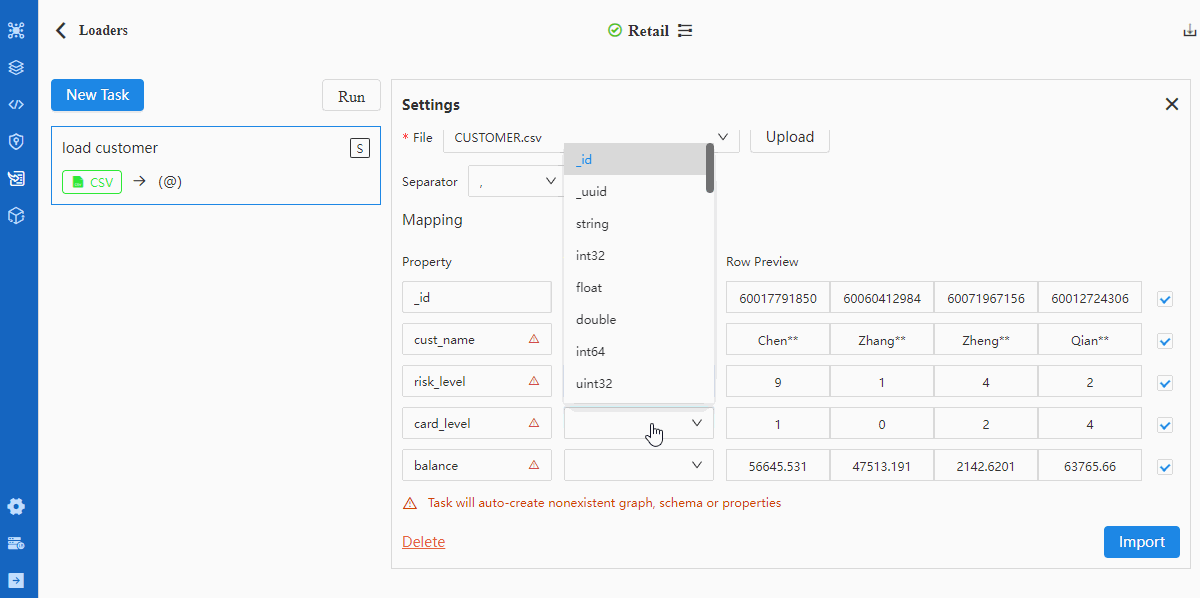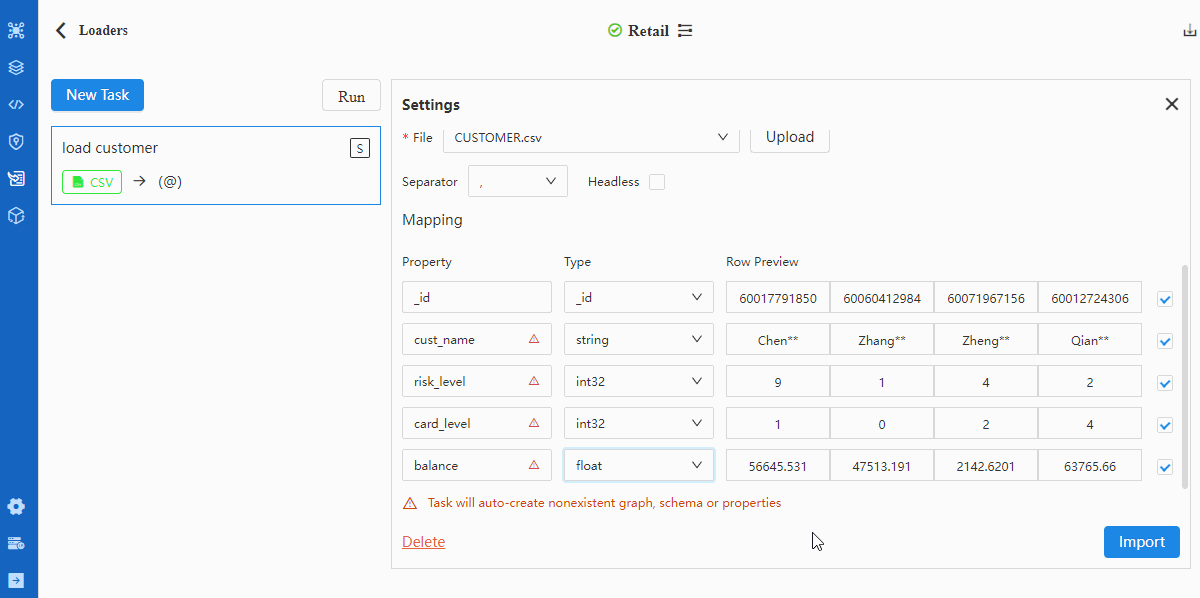
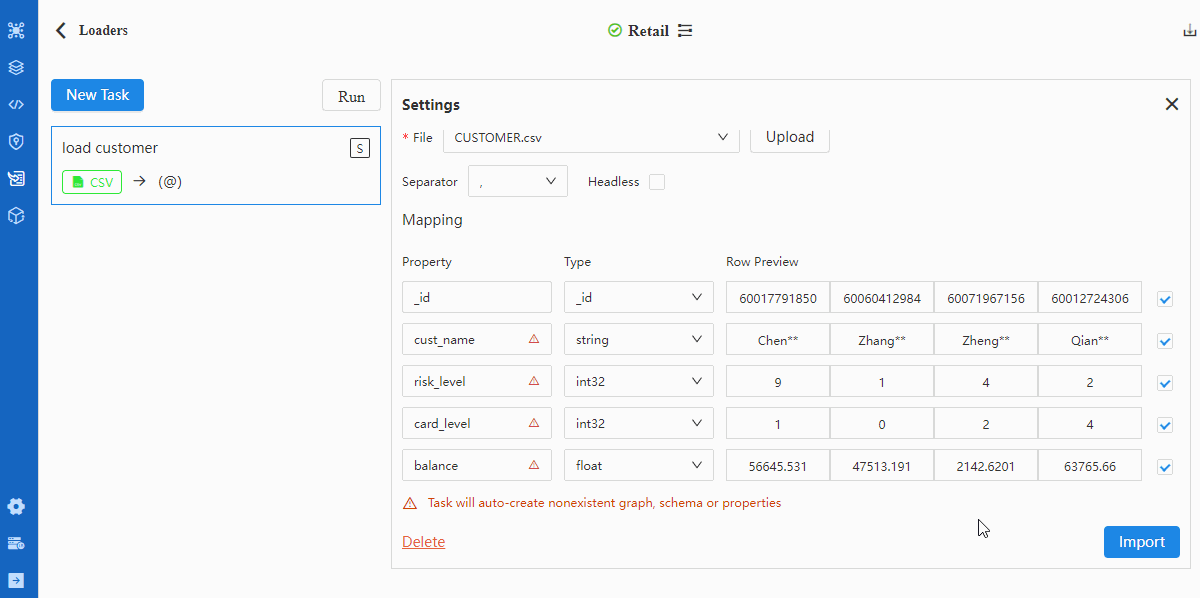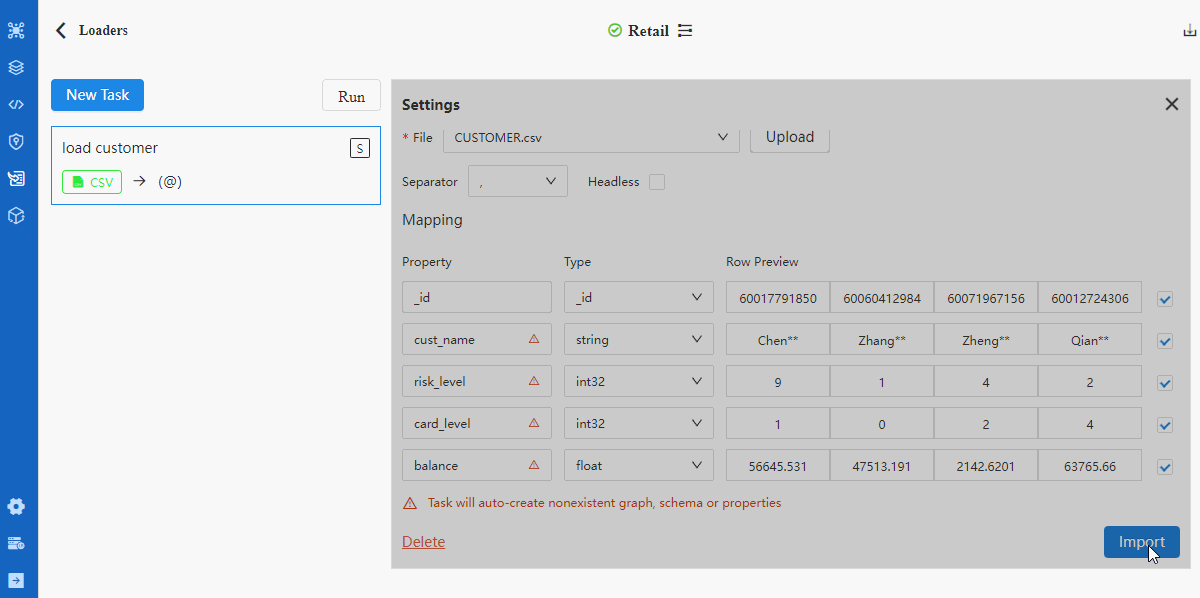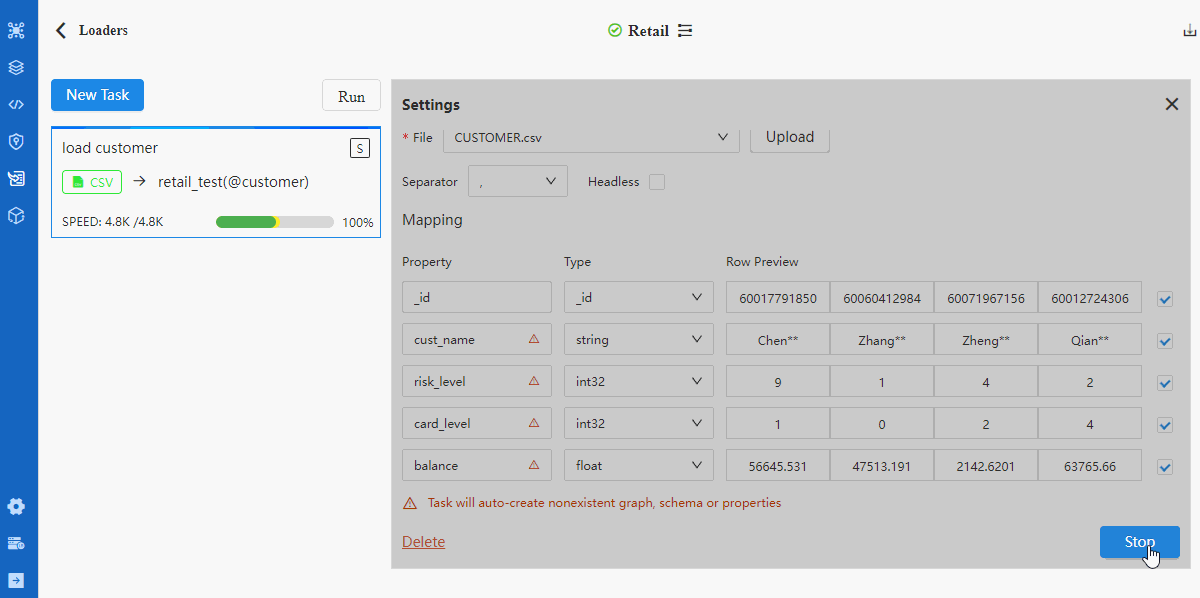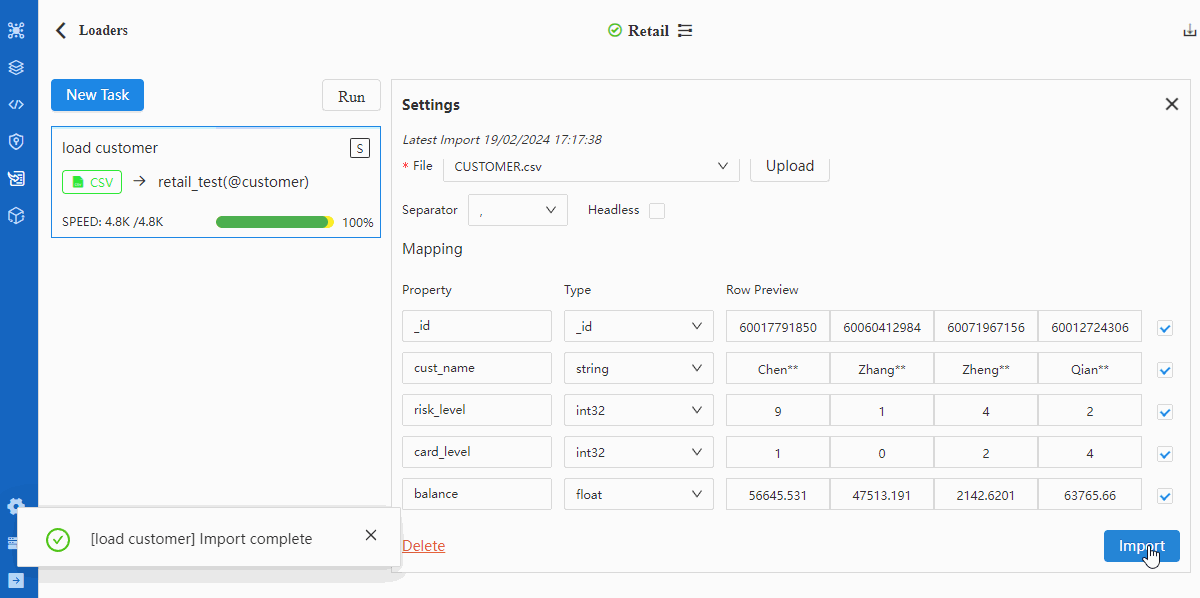
进行字段匹配时需注意:
- 表头Property中标记的红色三角△表示该表头所代表的属性在所选Schema中不存在;此时如果导入该表头的数据(勾选最右侧方格)将自动创建属性
- 若文件无表头,需勾选Headless项,此时Property显示内容为第一行数据,需依次修改为对应的属性名
关于File中所有配置项的含义,请阅读入图
本文所使用的数据文件均以英文逗号
,为列分隔符,且均含有表头;表头cust_no代表字段_id。
- 执行导入
重复步骤2~5导入MERCHANT.csv,注意在第3步中将Schema选为merchant,在第4步中将表头
merchant_no的Type选为_id。
整体演示(边)
重复步骤2~5导入TRASACTION.csv。注意在第3步中切换至“Edge”,并将Schema选为transfer;在第4步中将表头cust_no、merchant_no的Type选为_from、_to:
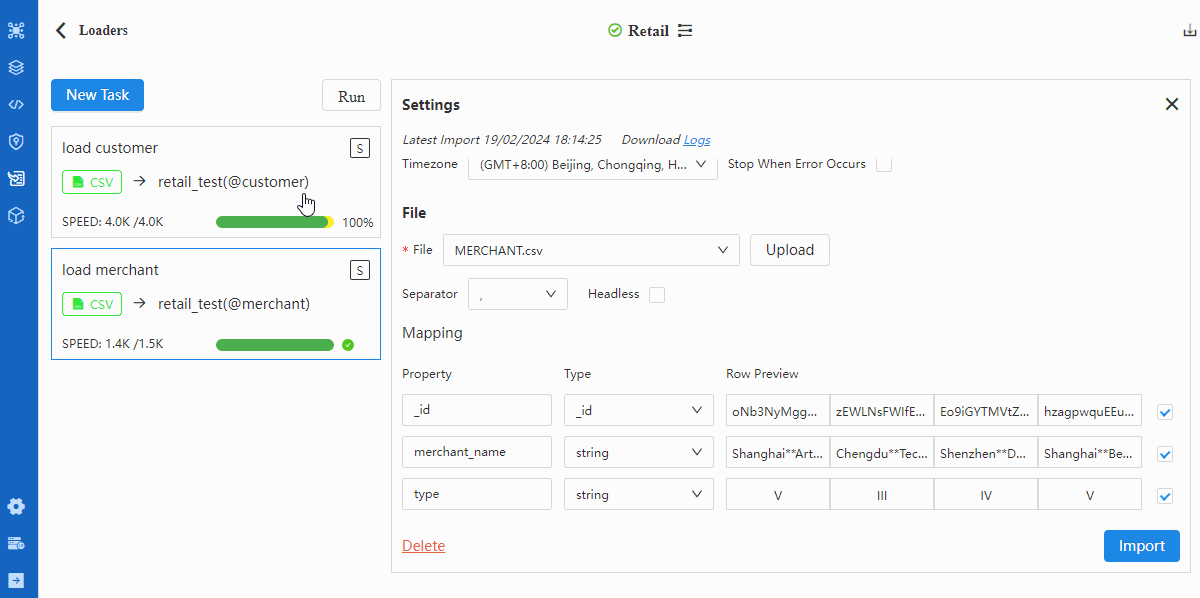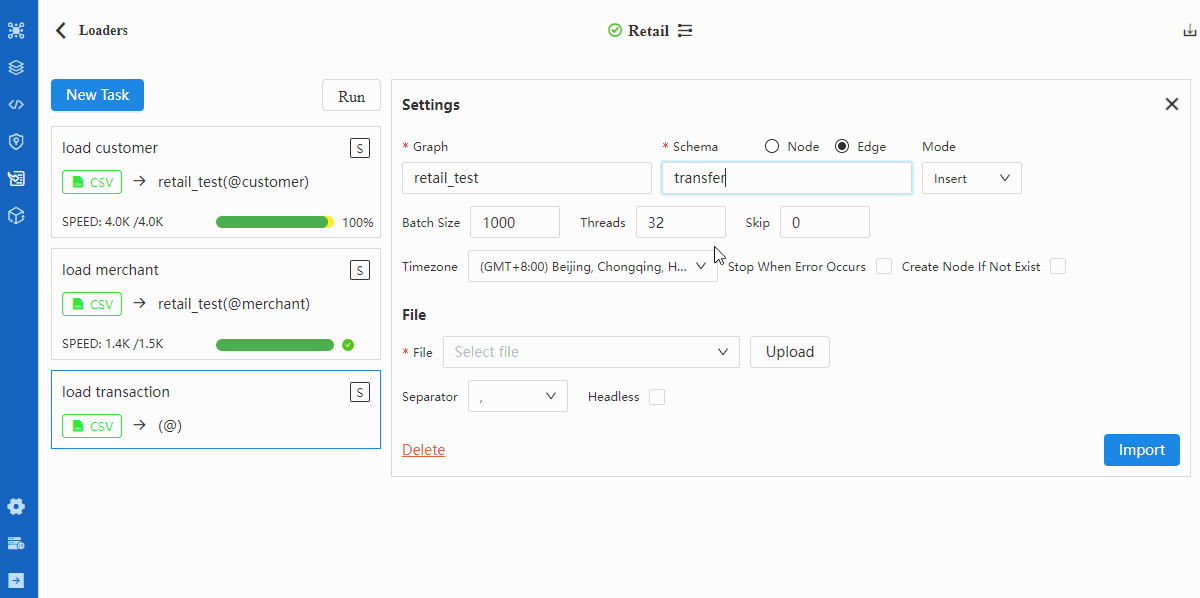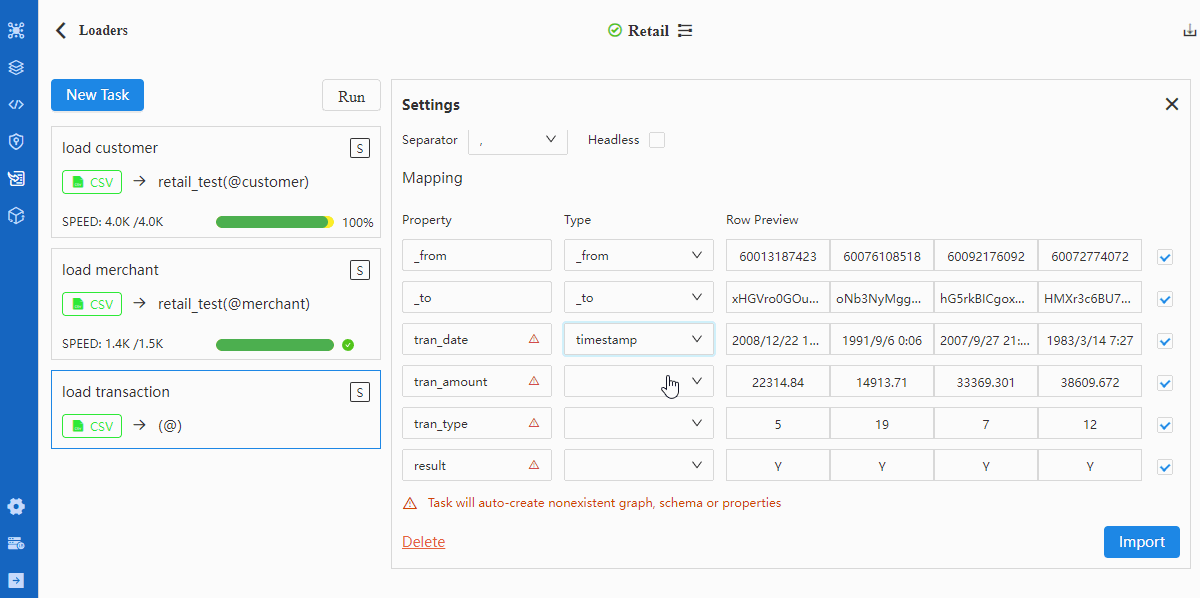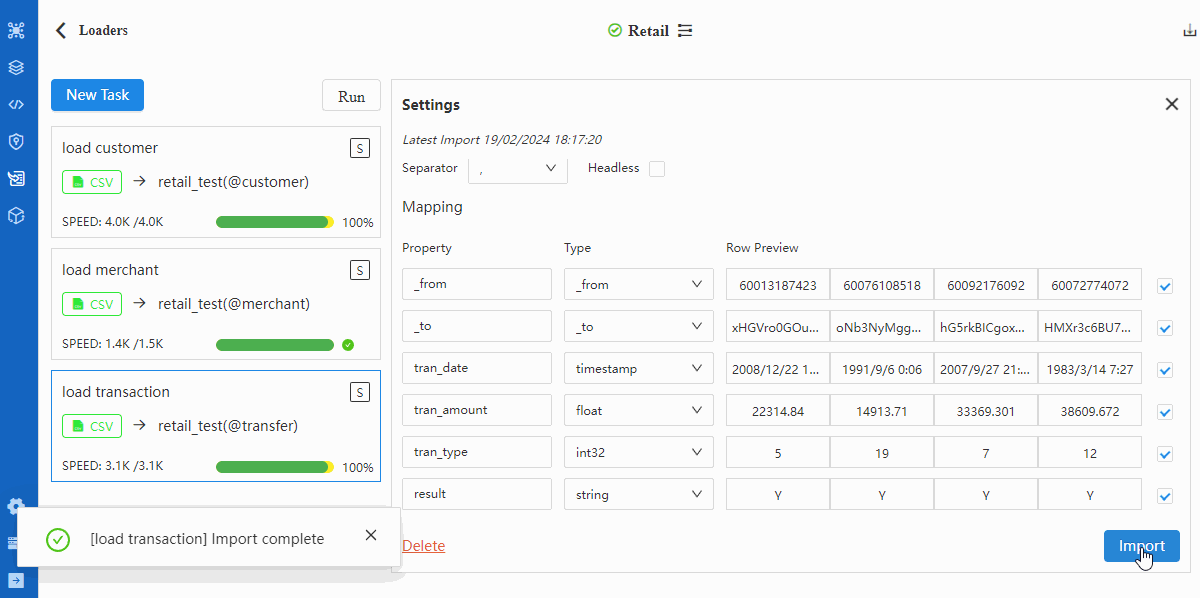
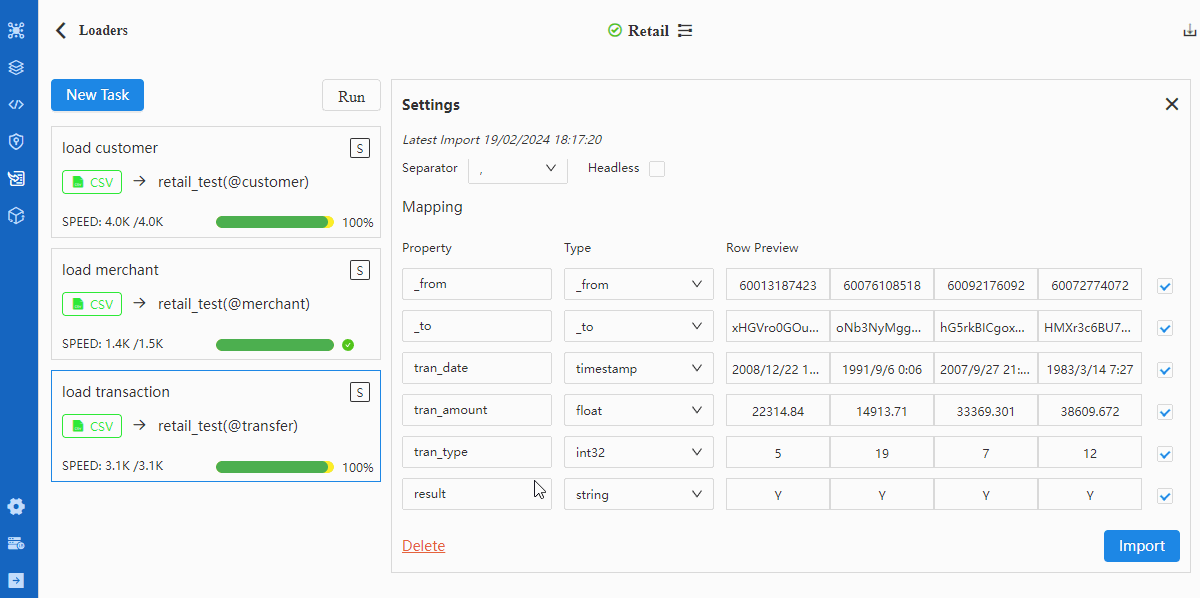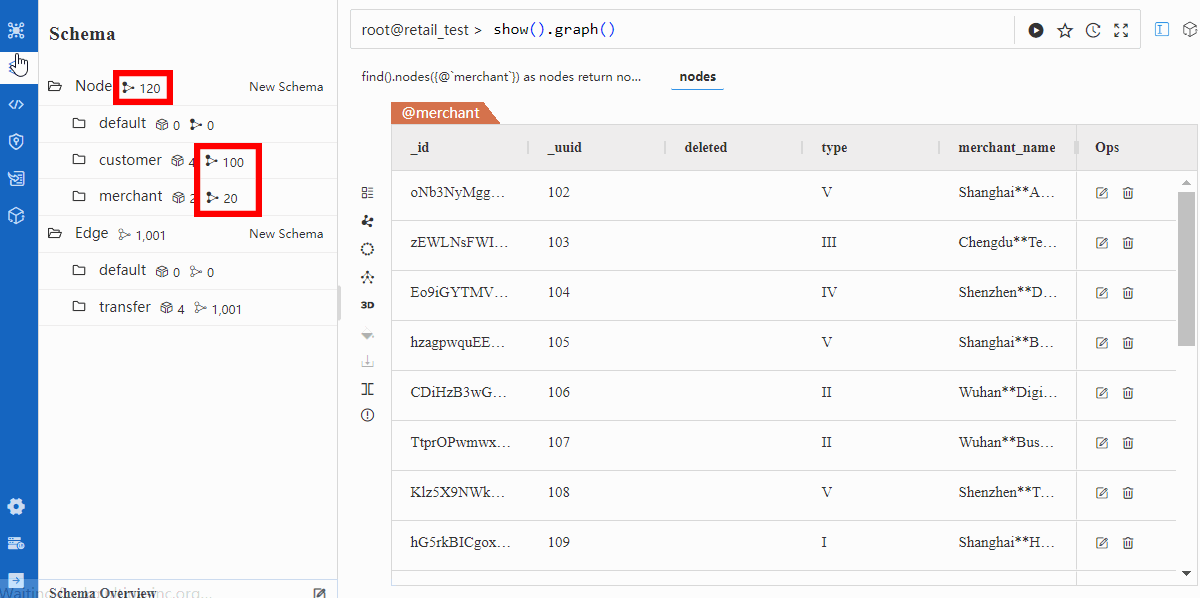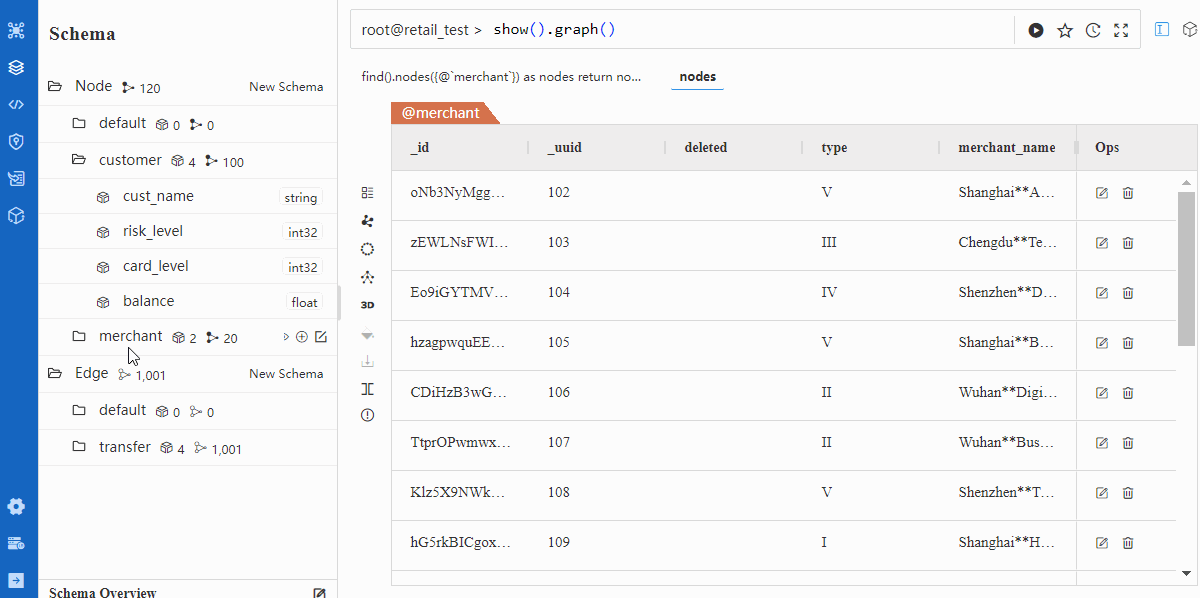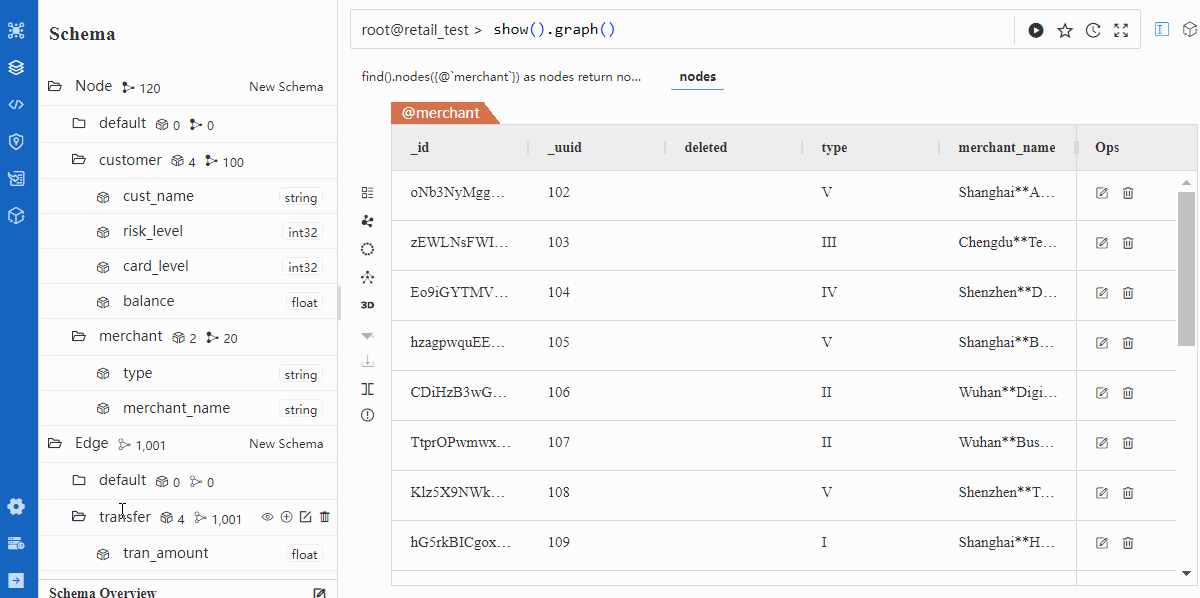
导入后验证
使用嬴图Transporter入图
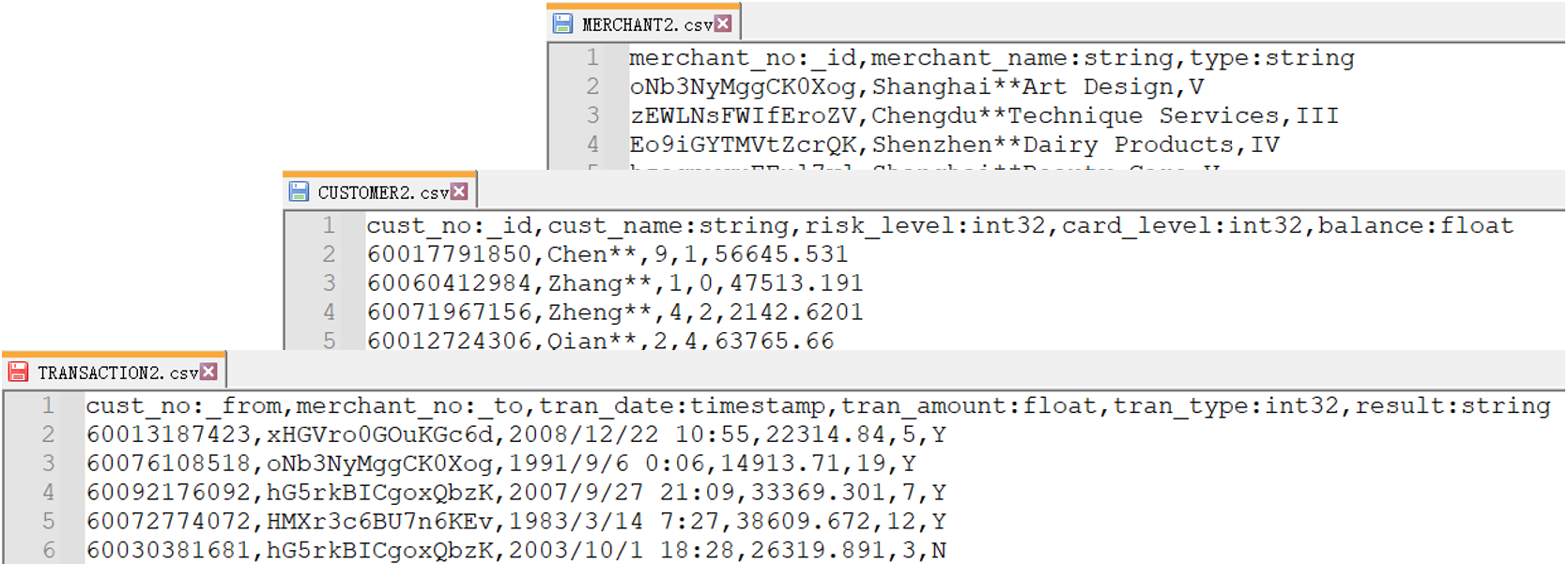
相比于嬴图Manager,通过嬴图Transporter-Importer进行的导入可从文件表头中识别数据类型,如:
通过嬴图Transporter-Importer进行导入分为两步:
- 准备YML文件
在一个YML文件中声明服务器连接、数据文件等信息。以下为YML文件的一部分:
nodeConfig:
- schema: "customer"
file: "./CUSTOMER2.csv"
- schema: "merchant"
file: "./MERCHANT2.csv"
edgeConfig:
- schema: "transfer"
file: "./TRANSACTION2.csv"
- 点击下载文件包YML_CSV,包含完整的YML文件以及修改表头后的数据文件
- 将文件包内的文件解压并存在至同一个目录下
- 对YML文件中的服务器相关信息根据实际情况进行修改
YML文件中各参数均有注释,更多介绍请阅读导入配置。
- 使用命令行工具运行嬴图Importer
将嬴图Transporter的导入工具ultipa-importer和之前解压得到的YML文件、数据文件放在同一个目录下,在该目录下打开命令行工具执行以下命令:
./ultipa-importer --config ./import_retail.yml
请根据您的操作系统选择命令行工具,如:Ubantu系统中右键打开 “用终端打开”,Windows系统中右键打开“更多”-“用Powershell打开”。
执行命令行时如果提示
bash: ./ultipa-importer: Permission denied则表示没有相关的执行权限,可执行chmod +x ultipa-importer获得权限后再执行ultipa-importer的命令。