本文将介绍几种常用的图查询命令,展示如何用编写其UQL语句以及它们在嬴图Manager中的查询结果样式。
本文使用的图集:
对于没有嬴图服务器环境的用户:
- 点击代码框上的Run按钮,在弹窗中运行并查看当前UQL命令的查询结果
- 点击Copy按钮复制代码,并在嬴图Playground中运行(注意选择图集Quick Start)
基本查询
查找点
点的查找类似于在关系型数据库中对某张表进行查询。尝试理解下边的UQL语句:
find().nodes() as myFirstQuery
return myFirstQuery{*} limit 10
该语句的字面含义为:查找点,将它们作为myFirstQuery,返回myFirstQuery并限制10条记录。
以上的描述已经相当接近了,以下是更多的解释:
- 链式语句子句
find().nodes()发起点查询 - 这些点的别名myFirstQuery被后面的
return子句调用 - 点别名后紧跟着的
{*}携带了这些点的全部属性
所以,这句UQL的目的是找到10个不同的点并返回它们的全部属性。在嬴图Manager中的执行结果为:
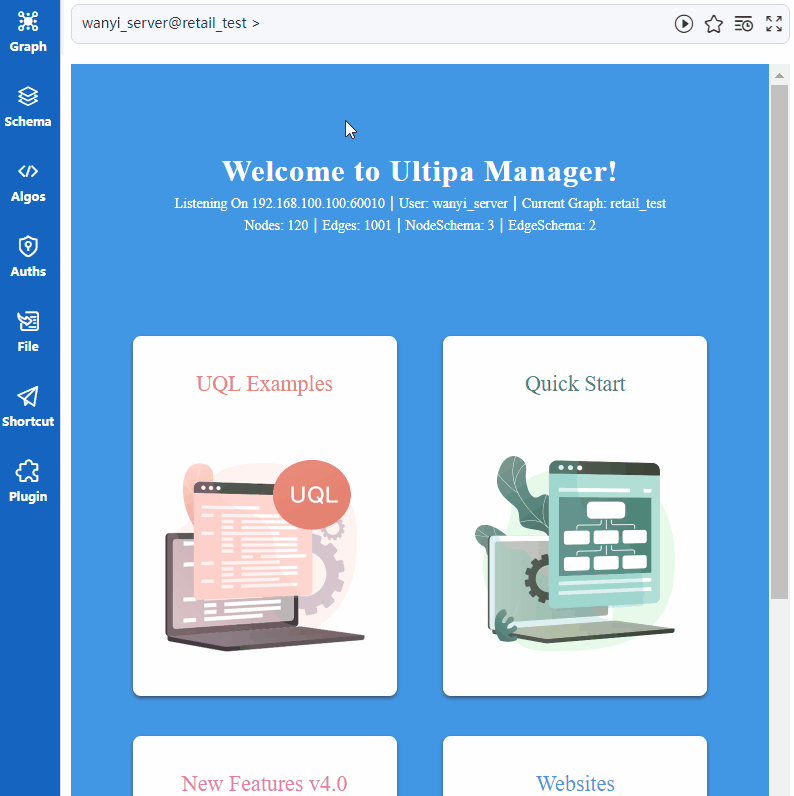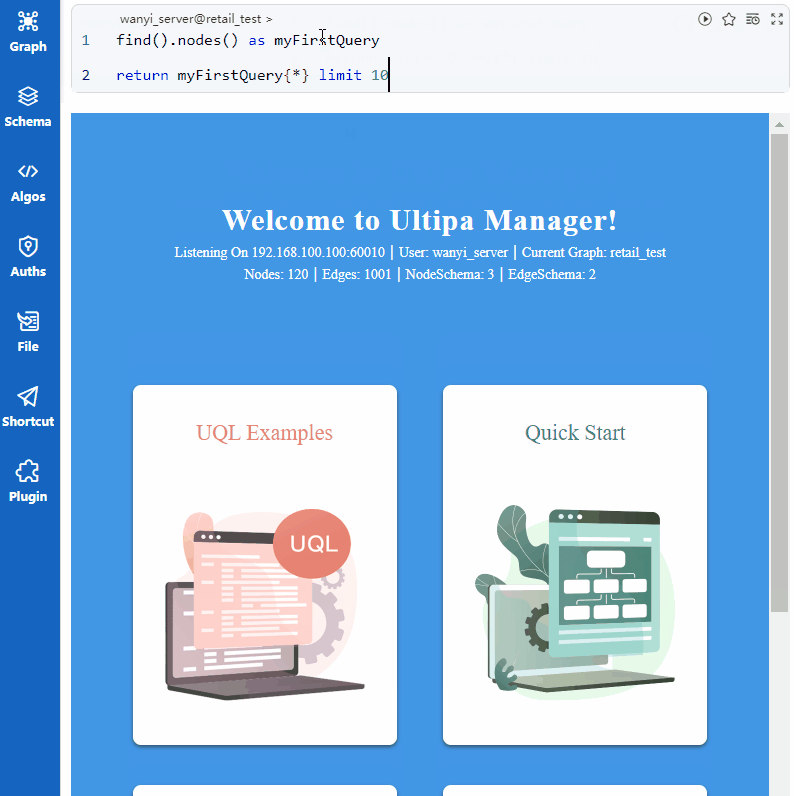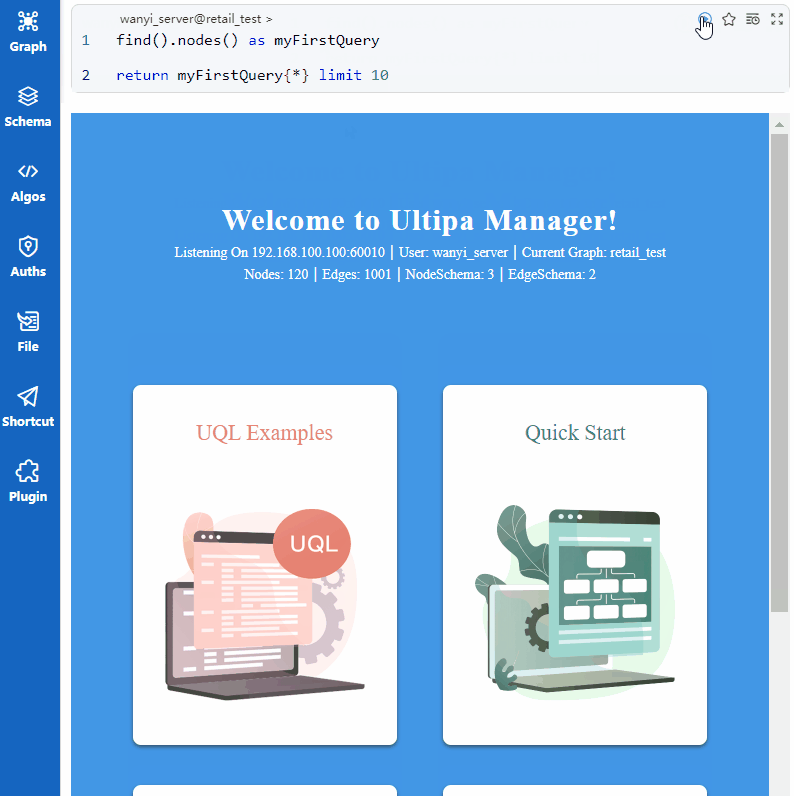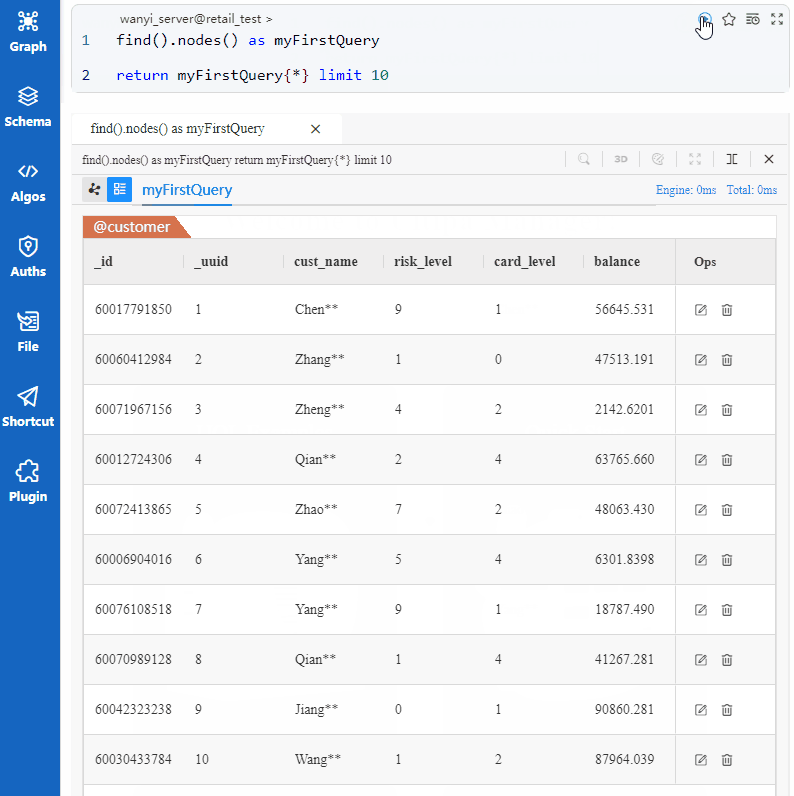
返回的10个点均属于Schema customer,这种结果取决于数据插入的先后顺序,同时也会受到并发计算的影响。
如果要查找某个特定Schema的点,比如merchant,可以在nodes()中添加描述:
find().nodes({@merchant}) as mySecondQuery
return mySecondQuery{*} limit 10
- 参数
nodes()中的花括号{}及其内容被称作过滤器(图数据中介绍的其他用来描述点的参数也如是)
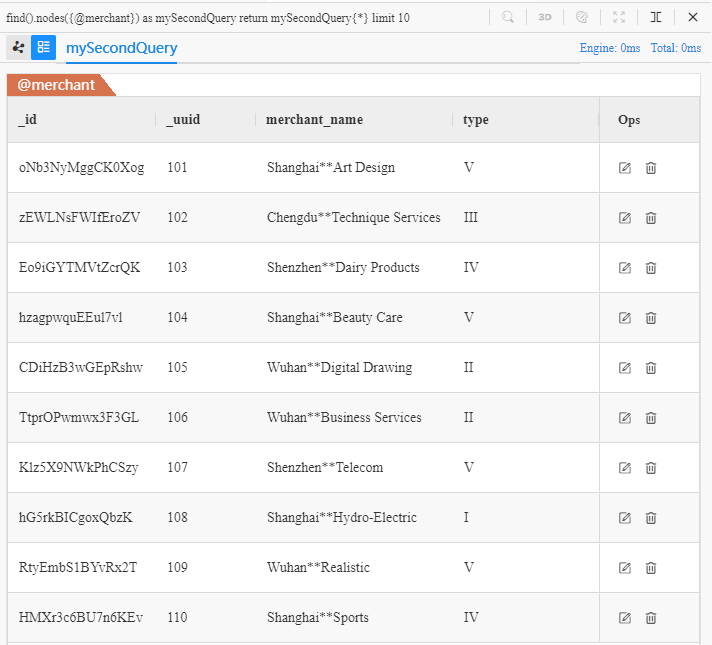
上面的UQL语句的执行结果如下:
查找边
在当前的图模型中,@customer节点通过@transfer边向@merchant节点进行转账:

边的查找与点极为类似,只需替换使用edges()传入边的过滤条件:
find().edges({_from == "60017791850"}) as payment
return payment{*} limit 10
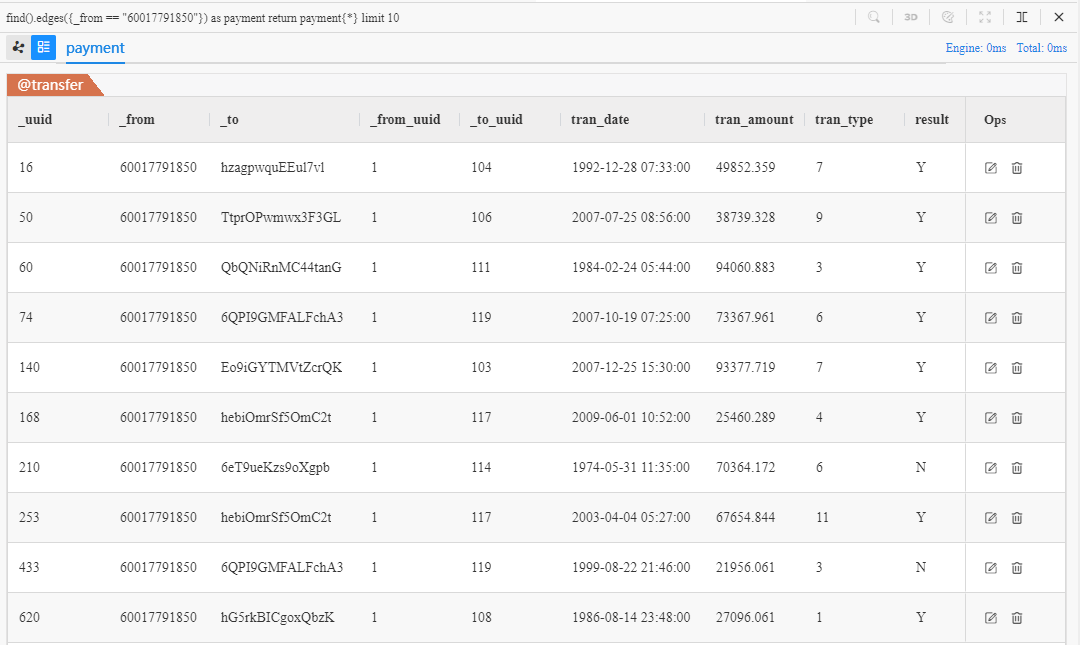
返回的10条payment全部由顾客Chen**(ID为60017791850)发起,payment的_id表示接收转账的商家ID。现在,用一个点查询语句调用这些商家的ID:
find().edges({_from == "60017791850"}) as payment
find().nodes({_id == payment._to}) as merchant
return merchant{*} limit 10
- 点别名后面紧跟着
._id表示调用这些点的属性_id
续写后的UQL语句返回10个接收了顾客Chen**(ID为60017791850)的转账的商家的所有属性:
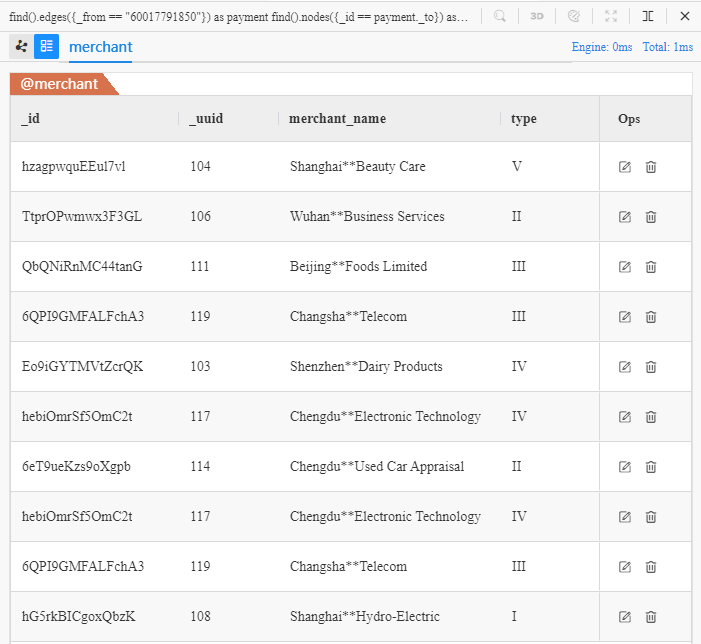
返回的10个商家中有两个商家重复出现了,即
_uuid为117和119的商家,他们各出现了两次,原因是这两个商家各收到两笔来自Chen**的付款。
这向我们展示了一个典型的复杂图(多边图)的例子,即两个节点之间有多条边存在。想要更好的观察这一现象,可以更换查询命令并用嬴图Manager的2D视图进行观察。
展开
spread().src({_id == "60017791850"}).depth(1) as transaction
return transaction{*} limit 10
该语句的字面意思:以ID为60017791850的点为源头进行展开,深度为1,返回10条记录的所有属性。
spread()命令发起了以点src()为源头的边查询,并以BFS方式进行搜索depth()参数限制该BFS搜索的最大深度- 别名transaction为找到的边的一步路径形式,即“起点-边-终点”
- 路径别名后面紧跟着的
{*}携带了路径中点、边的全部属性
所以这句UQL的目的是查找10笔由顾客Chen**发起的转账,返回顾客Chen**、所有转账边以及所有收款商家的全部属性:
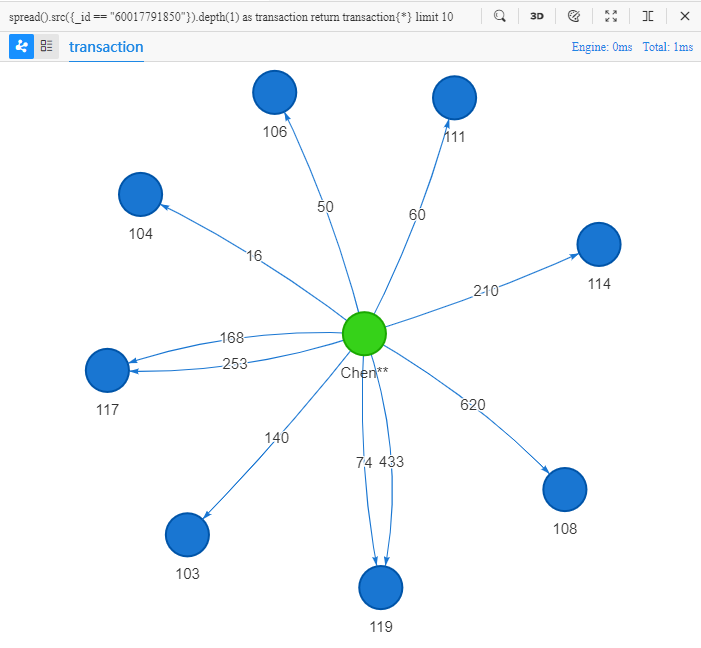
嬴图Manager将返回的路径自动显示在2D视图中,从图中能清楚的看到商家117和119与顾客Chen**之间的多笔转账。
如果要指定spread()命令所返回的路径终点的不重复数量,可以适当引入去重操作再进行返回。另一种思路是改用另一种查询命令,同样使用BFS的方式进行搜索,但搜索的目标是点,而非边。
K邻
khop().src({_id == "60017791850"}).depth(1) as merchant
return merchant{*} limit 10
该语句的字面意思:以ID为60017791850点为源头进行跳跃,深度为1,返回10条记录的所有属性。
khop()命令发起以src()为源头的点查询,并以BFS方式进行搜索- 别名merchant为找到的点
所以,这句UQL的目的是查找10个接收顾客Chen**转账的商家并返回商家的全部属性:
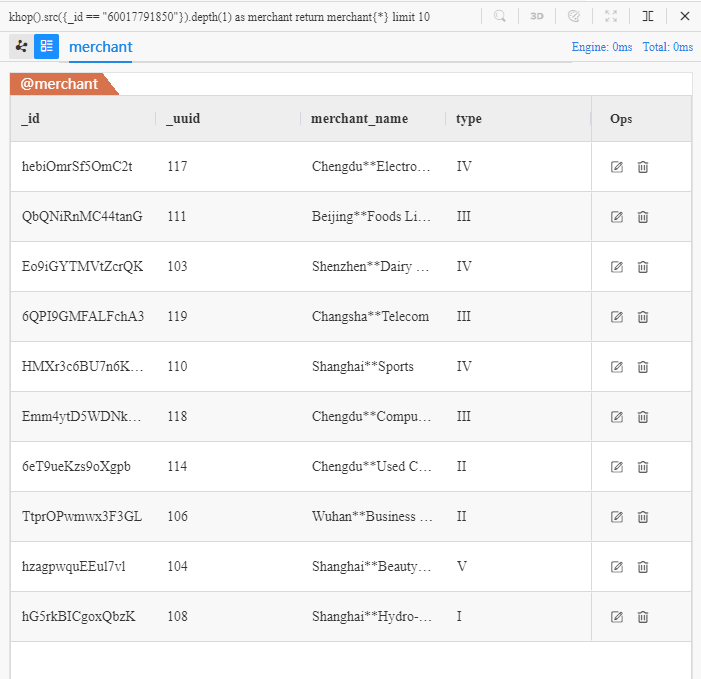
khop()命令找到了10个不同的收款商家,对比之前使用spread()命令找到的10笔付款中的8个收款商家,新发现了110和118两个商家。
模板的思维方式
模板查询是一种高级的图查询方法,通过使用n()、e()、nf()对路径中的每一个点、边进行精确描述(前文图数据中有提到)。
链路
n({_id == "60017791850"}).e().n() as transaction
return transaction{*} limit 10
该语句的字面意思:查找从ID为60017791850的点开始的一步路径,返回10条路径的所有属性:
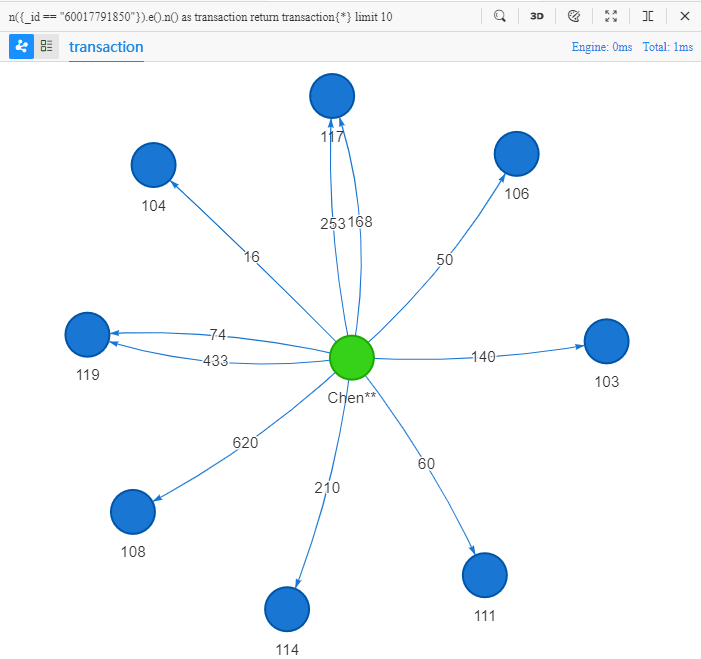
返回的结果和之前
spread()示例的结果完全一致,因为它们全都是在查找从顾客Chen**出发的一步转账路径。
现在考虑这样一种路径:从Chen**出发,经过三条边,最终到达某个商家:

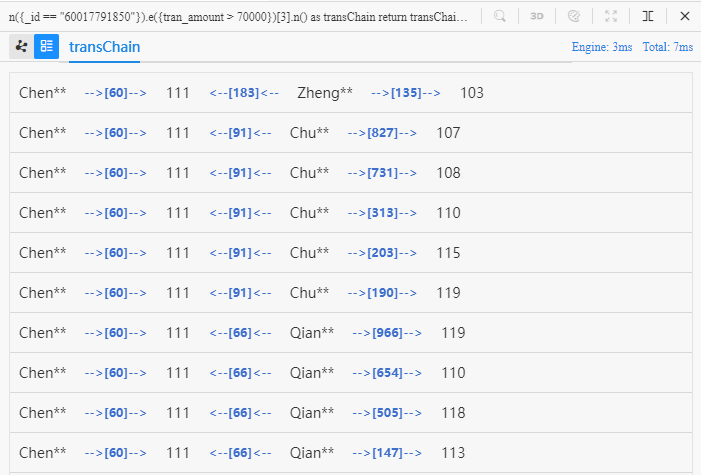
n({_id == "60017791850"}).e({tran_amount > 70000})[3].n() as transChain
return transChain{*} limit 10
e()后面紧跟着的[3]表示3条连续的边(作用类似于之前提到的depth())
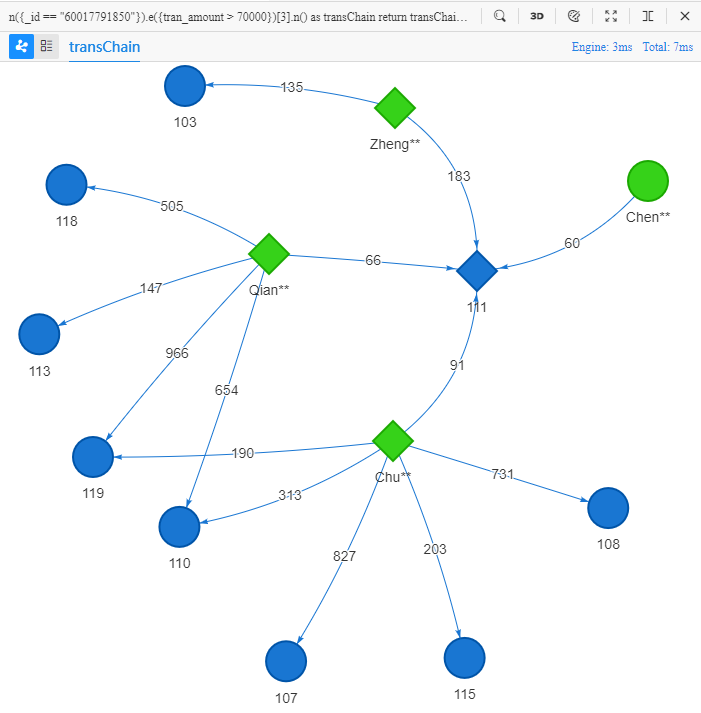
10条路径从Chen**出发,到达第二个节点(商家111)后兵分三路,再从Zheng**、Qian**、Chu**分散为10条路径、到达8个不同的商家。
图中所示的Chen**和Zheng**、Qian**、Chu**均购买过商家111的商品,在特定场景下可能意味着这4个顾客特征相似,因此便有理由将Zheng**、Qian**、Chu**光顾过的其他8个商家(路径终点)推荐给Chen**。这便是一种典型的商品、商家推荐模型。
当返回结果中有点、边重复出现时,嬴图Manager的2D视图不会对其进行重复渲染。例如上面查到的10条路径,每一条都以Chen**为起点,以“转账60”为第一条边,以“商家111”为第二个点,而2D视图中只渲染一个Chen**、一条“转账60”边、一个“商家111”。如需了解每一条路径的具体信息,可切换至列表视图:
环路
路径中不允许有边重复出现,但允许有重复的点,于是便有了环路。
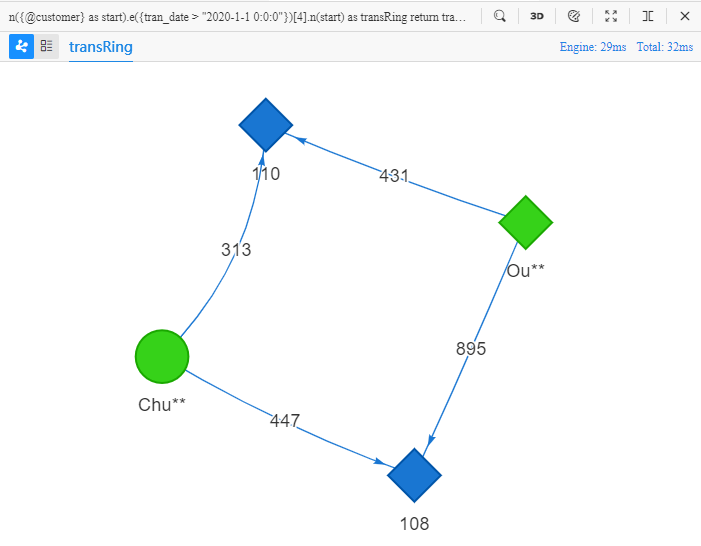
n({@customer} as start).e({tran_date > "2020-1-1 0:0:0"})[4].n(start) as transRing
return transRing{*} limit 10
- 最后一个
n()调用了的第一个n()的别名start,表示路径的首尾节点相同(即形成环路)
所以这句UQL的目的是查找10条从某个顾客出发的四步路径,并最终回到该顾客,要求每一步转账都晚于2020-1-1 0:0:0,返回这些路径中的所有点、边的全部属性:
切换到列表视图为:
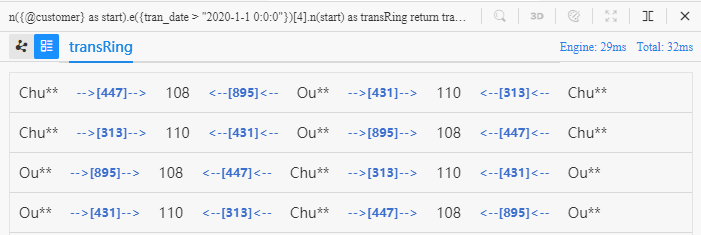
顾客Chu**、Ou**均从商家110、108处购买商品,这种结构在特定的场景下意味着Chu**和Ou**具有相似性。
最短路
n({_id == "60017791850"}).e()[:5].n(115) as transRange
return transRange{*} limit 1
- 中括号中的
:5也可写作1:5,表示边数为1~5,而非固定值 - 最后一个
n()中的数字115是过滤器{_uuid == 115}的简写形式
所以,这句UQL的目的是查找1条从Chen**出发、到达UUID为115的节点的路径,要求边数不超过5,返回这条路径中的所有点、边的全部属性:

返回的这条路径刚好有5条边。
对路径中的边数稍加修改,则可能完全改变查询的目标:
n({_id == "60017791850"}).e()[*:5].n(115) as transShortest
return transShortest{*} limit 1
- 在边数中添加星号
*后得到*:5,模板变成了边数不超过5的最短路径
所以,这句UQL的目的是查找1条从Chen**出发、到达UUID为115的节点的最短路径,要求边数不超过5,返回这条路径中的所有点、边的全部属性:
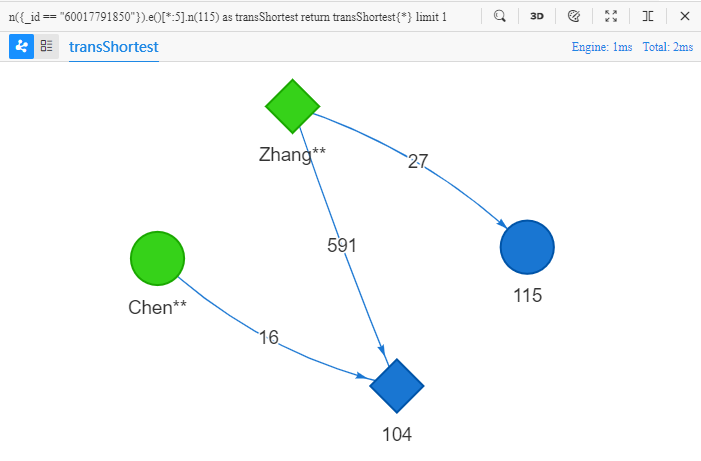
最短路径体现的是两点之间最直接的联系。一般情况下,路径越短,路径中数据的关联性就越大,路径就越值得被研究。也正因如此,真实世界中的某些实体会故意将自身隐藏在很长(20~30步)的数据链路末端。为了能挖掘出这类可疑实体,要求数据库拥有超深遍历的能力和快速响应的高性能。
常用运算
UQL查到点、边、路径以后,可以进行很多运算。这些运算是通过函数、子句进行的。运算的种类非常多,具体可参看UQL文档。在本节中仅挑选一些较常用的运算进行介绍。
去重
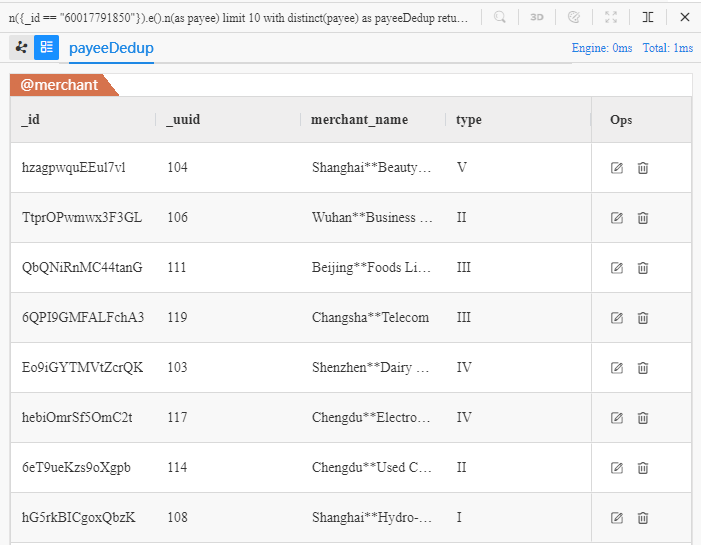
修改前面链路一节中的第一个例子,将10条路径的终点去重后再返回(8个商家):
n({_id == "60017791850"}).e().n(as payee) limit 10
with distinct payee as payeeDedup
return payeeDedup{*}
- 操作符
distinct对payee进行去重 - 去重操作写在
with子句中 - UQL语句按顺序执行,
limit 10位于with之前则先查找10条结果,再进行去重
计数
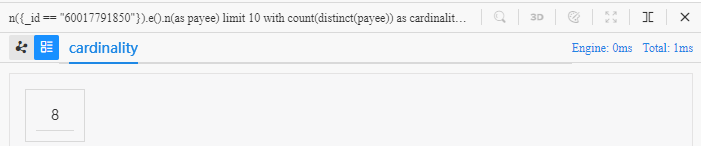
修改上面的示例,计算去重后的终点个数:
n({_id == "60017791850"}).e().n(as payee) limit 10
with count(distinct payee) as cardinality
return cardinality
- 函数
count()对distinct payee进行数量统计,count()和distinct经常这样套用在一起
排序
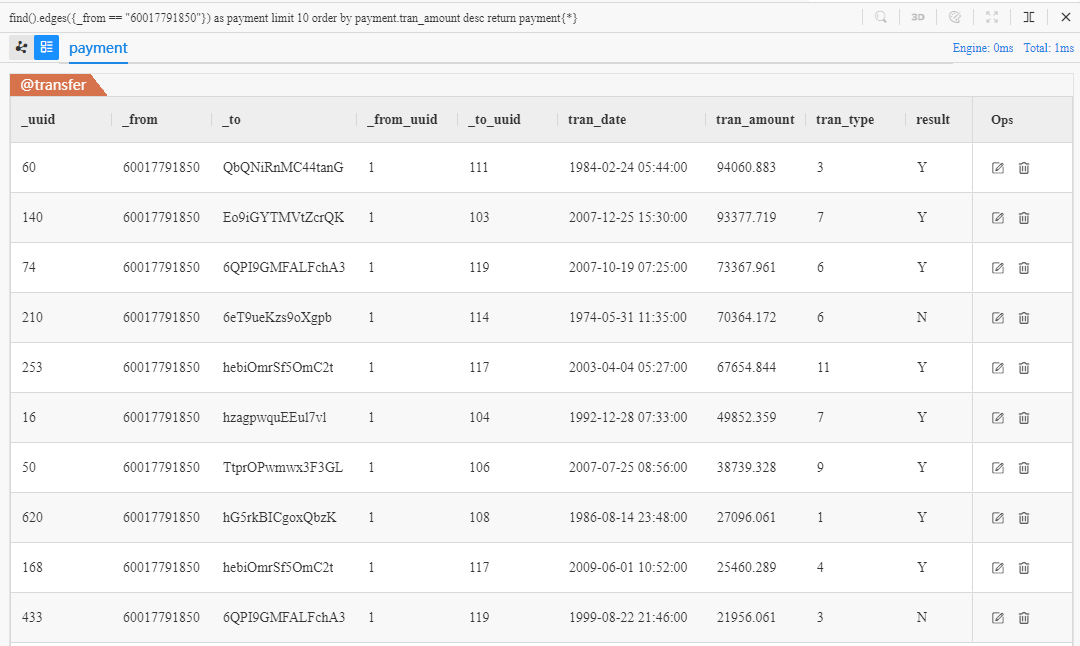
修改前面查找边一节中的第一个例子,将找到的边按转账金额降序排列后再返回:
find().edges({_from == "60017791850"}) as payment limit 10
order by payment.tran_amount desc
return payment{*}
- 子句关键词
order by对payment按照其属性tran_amount进行排序 - 位于子句
order by末尾的关键词desc表示降序
分组
修改前面链路一节中的第二个例子,将找到的三步路径按照路径中的第三个点进行分组,并统计每组中的路径数量:
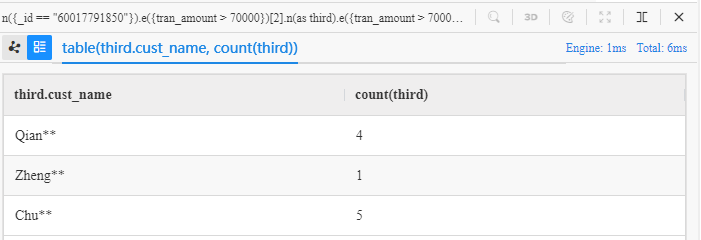
n({_id == "60017791850"}).e({tran_amount > 70000})[2].n(as third).e({tran_amount > 70000}).n() limit 10
group by third
return table(third.cust_name, count(third))
- 为了在模板中体现第三个点,将原先的结构
n().e()[3].n()改写为n().e()[2].n().e().n() - 子句关键词
group by对third进行分组 - 函数
count()对每组中的third进行数量统计 - 函数
table()将third.cust_name和count(third)合并到一个表格中,使结果一目了然