✓ 文件回写 ✕ 属性回写 ✕ 直接返回 ✕ 流式返回 ✕ 统计值
概述
GraphSAGE训练算法用于训练GraphSAGE模型。训练过程是在完全无监督的情况下使用随机梯度下降和反向传播等技术实现的。
训练后的GraphSAGE模型可用于生成节点嵌入。这个归纳式的框架还能为新加入的节点生成嵌入,而不用重新训练模型。有关如何使用GraphSAGE模型进行此操作的详细信息,请参阅 GraphSAGE算法。
基本概念
GraphSAGE:参数学习
根据GraphSAGE的嵌入生成(前向传播)算法,训练模型时需要调整K个聚合器函数(表示为AGGREGATEk)和K个权重矩阵(表示为Wk)的参数。
损失函数的设计旨在鼓励图上相距较近的节点具有相似的嵌入表示,同时要求相距较远的节点的嵌入尽可能不同:
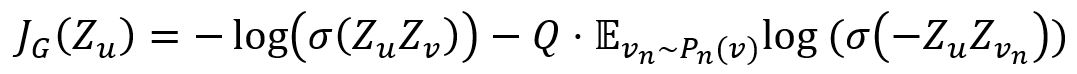
其中,
- v是在固定长度的随机游走中在u附近出现的节点。
- vn是一个负样本,Q是负样本的数量,Pn是负采样概率分布。
- σ是sigmoid函数。
- Z是由GraphSAGE模型生成的节点嵌入。
在特定的下游任务中使用节点嵌入的情况下,可根据任务目标使用其他的损失函数,比如交叉熵损失函数。
聚合器函数
聚合器函数(Aggregator Function)能将一组向量合并成一个向量,它用于生成GraphSAGE中的邻域向量。支持以下两种类型的聚合器。
1. 均值聚合器
均值聚合器(Mean Aggregator)直接取各向量对应元素的均值得到聚合向量。例如,向量[1,2]、[4,3]和[3,4]将被聚合成向量[2.667,3]。
使用均值聚合器时,GraphSAGE的嵌入生成算法直接产生节点第k轮迭代的嵌入表示:
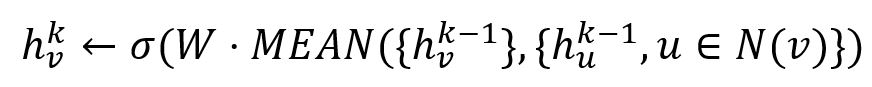
2. 池化聚合器
在池化聚合器(Pooling Aggregator)中,每个邻居的向量先单独通过一个全连接的神经网络;经过此转换之后,再对整个邻居集合执行元素级的最大池化操作:
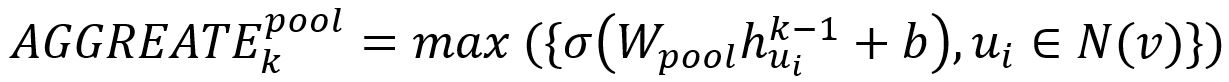
其中,max代表元素级的最大运算符,σ是一个非线性的激活函数。
特殊说明
- GraphSAGE训练算法忽略边的方向,按照无向边进行计算。
语法
- 命令:
algo(graph_sage_train) - 参数:
名称 |
类型 |
规范 |
默认 |
可选 |
描述 |
|---|---|---|---|---|---|
| dimension | int | ≥2 | 64 |
是 | 生成的节点嵌入向量的维度 |
| node_property_names | []<property> |
数值类型,需LTE | / | 否 | 构成节点特征向量的多个点属性 |
| edge_property_name | <property> |
数值类型,需LTE | / | 是 | 边权重所在的边属性;未设置时按照非加权图计算 |
| search_depth | int | ≥1 | 5 |
是 | 随机游走的深度 |
| sample_size | []int | / | [25, 10] |
是 | 列表中的元素依次是在第K层至第1层邻域的采样个数;列表长度就是采样邻域的层数 |
| learning_rate | float | [0, 1] | 0.1 |
是 | 每轮训练迭代的学习率 |
| epochs | int | ≥1 | 10 |
是 | 训练大循环的次数;每轮大循环前,重新进行邻域采样 |
| max_iterations | int | ≥1 | 10 |
是 | 每轮大循环的最大迭代次数;每轮迭代使用随机选择的一批节点的梯度更新权重 |
| tolerance | double | >0 | 1e-10 |
是 | 当两轮迭代的传播损失差值低于此收敛标准时,当前训练大循环结束 |
| aggregator | string | mean, pool |
mean |
是 | 使用的聚合器类型,mean代表均值聚合器,pool代表池化聚合器 |
| batch_size | int | ≥1 | 节点/线程数 | 是 | 每批包含的节点数量;这也是负采样的数量 |
示例
文件回写
| 配置项 | 回写内容 |
|---|---|
| model_name | 训练后的GraphSAGE模型 |
algo(graph_sage_train).params({
dimension: 10,
node_property_names: ['dbField','fField','uInt32','int32','age'],
edge_property_name: 'rank',
search_depth: 5,
sample_size: [25,10],
learning_rate: 0.05,
epochs: 8,
max_iterations: 10,
tolerance: 1e-10,
aggregator: 'mean',
batch_size: 100
}).write({
file:{
model_name: 'SAGE_model'
}
})
结果:文件SAGE_model.json;此模型可用于GraphSAGE算法生成节点嵌入