概述
当链式子句调用一个别名或多个同源别名时,子句的执行次数等于别名所代表的数据所包含的数据条目数。每次执行使用一条数据,系统会根据实际情况进行优化。对于查询子句,子句每次执行可被视为一次子查询。
然而,如果链式子句调用多个异源别名,子句的执行次数取决于数据条目数最少的别名。
一般情况
示例:n包含4条数据,删除子句执行4次,每次删除1个点。

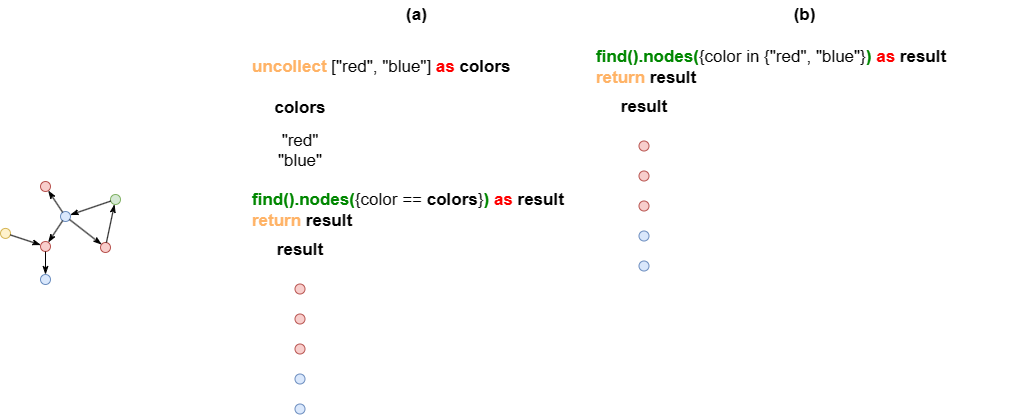
示例:这两个语句的结果相同,但执行方式不同。
- (a):
find().nodes()子句调用别名colors,它包含2条数据,因此子句执行2次。 - (b):
find().nodes()子句没有调用别名,子句只执行1次。
CALL子句
CALL子句用于对每条数据单独进行处理。
示例:CALL子句单独处理users的每条数据。假设users包含N个点,CALL子句就会执行N次;CALL子句每次执行时,其中的路径查询子句和SKIP子句分别执行1次。
find().nodes({@user}) as users
call {
with users
n(users).e()[:2].n() as paths
skip 2
return paths
}
return paths
BATCH子句
BATCH子句将一个数据分成多批分别进行处理,以节省内存占用。
示例:users中的(最多)5000个点被分成50批,每批100个点。每批中的点被自动收集在一起并传入路径查询子句,该子句执行50次。
find().nodes({@user.age_level == 4}) limit 5000 as users
BATCH 100
n(users).e().n({@ad} as ads)
GROUP BY ads.cate
RETURN table(ads.cate, count(ads.cate))
LIMIT和limit()
LIMIT子句限制一个别名包含的数据条数。limit()方法则用于链式子句,它限制子句每次执行返回的数据条数。
示例:这两个语句中的find().nodes()子句都执行2次,但它们的结果不同。
- (a):
limit(2)方法限制每次子查询返回至多2个点。 - (b):
LIMIT子句限制result返回至多2个点。
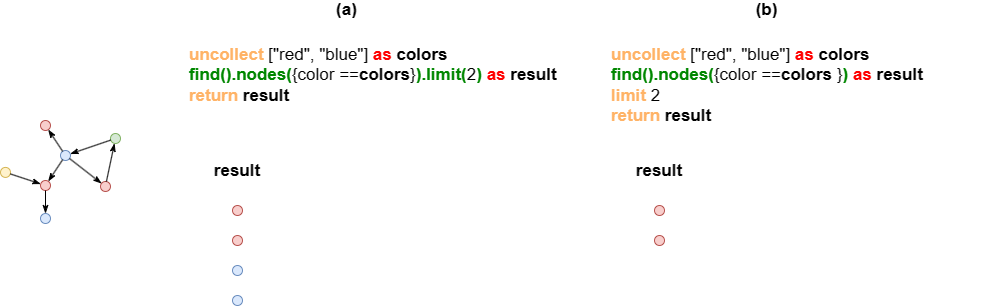
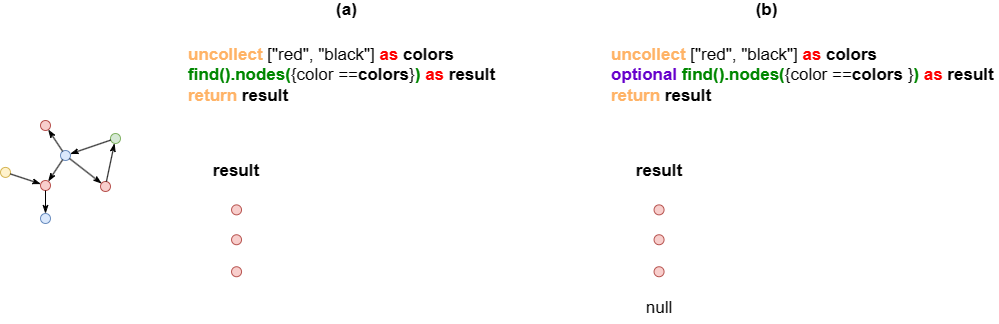
OPTIONAL前缀
OPTIONAL前缀保证每次子句执行都有返回值。如果子查询无结果,返回null。
示例:这两个语句中的find().nodes()子句都执行2次,但它们的结果不同。
- (a):子句第2次执行时没有返回结果。
- (b):子句第2次执行时没有返回null。