概述
函数collect()将一个别名的非null行放入一个列表。聚合后该别名及其所有同源别名只保留一行数据,其余行舍弃。
参数:collect(<alias>)
<alias>:别名(除TABLE外的所有类型)
返回值:
- 收集别名代表的数据行的信息组成的列表(list类型)
- 对于NODE、EDGE和PATH类型的别名,取点和/或边的信息
一般用法
示例图集:
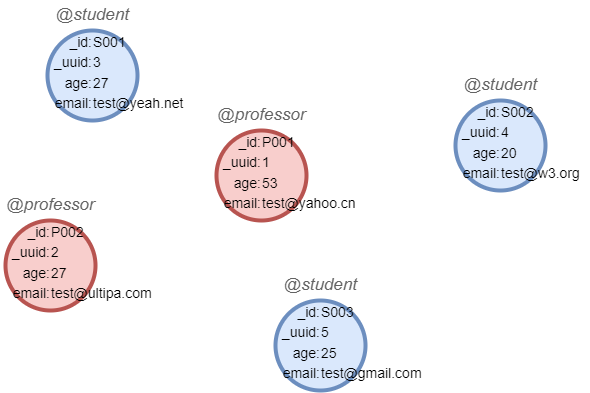
在一个空图集中,依次运行以下各行语句创建示例图集:
create().node_schema("professor").node_schema("student")
create().node_property(@*, "age", int32).node_property(@*, "email", string)
insert().into(@professor).nodes([{_id:"P001",_uuid:1,age:53,email:"test@yahoo.cn"},{_id:"P002",_uuid:2,age:27,email:"test@ultipa.com"}])
insert().into(@student).nodes([{_id:"S001",_uuid:3,age:27,email:"test@yeah.net"},{_id:"S002",_uuid:4,age:20,email:"test@w3.org"},{_id:"S003",_uuid:5,age:25,email:"test@gmail.com"}])
本例获取所有节点的age属性值列表:
find().nodes() as n
return collect(n.age)
[53,27,20,27,25]
本例获取所有@professor点信息的列表:
find().nodes({@professor}) as n
return collect(n)
[
{"id":"P001","uuid":"1","schema":"professor","values":{"age":"53","email":"test@yahoo.cn"}},
{"id":"P002","uuid":"2","schema":"professor","values":{"age":"27","email":"test@ultipa.com"}}
]