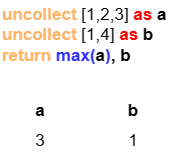概述
一个UQL语句通常包含多个子句,它们将从数据库获取或自行构建的数据按顺序进行传递和处理。别名通常用于命名和代表数据,以便后续子句调用数据。
一个数据可以包含多个条目。为了便于说明,我们将其视为包含多个数据行,每行包含一个数据条目。当子句(尤其是链式子句)调用别名时,将逐行执行相应的查询或计算。
同源数据
由同一子句产生的数据是同源的,流入子句的数据与子句产生的数据也是同源的。同源数据的特点是数据行数相等,并且同一行有对应关系。这种同源特性也延申到从一个数据提取出的信息。
示例:tail、path和length是同源的,它们都包含5行数据。
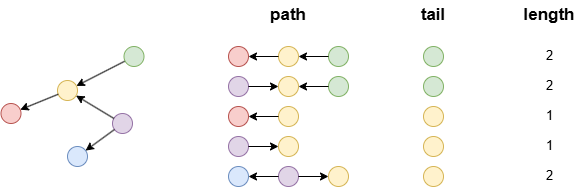
n().e()[:2].n(as tail).limit(5) as path
with length(path) as length
return path, tail, length
示例:n、n.score1、n.score2和mean是同源的,它们都包含4行数据。
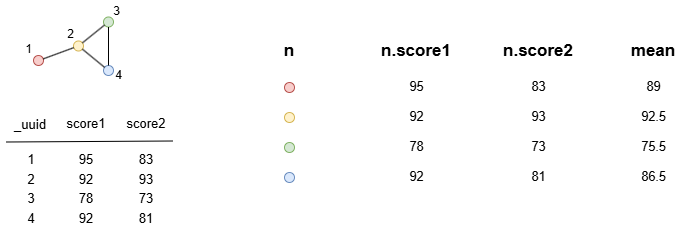
find().nodes() as n
return (n.score1 + n.score2) / 2 as mean
聚合
使用聚合函数会使数据只剩一行,其余行被丢弃,此时同源数据也会被影响。聚合后,所有同源数据剩余的一行通常没有对应关系。
示例:n和n.score1同源,原本包含4行数据;当n.score1在RETURN子句中被聚合并产生minS1后,n也只剩1行。

find().nodes() as n
return n, min(n.score1) as minS1
去重
对数据进行去重通常会使数据行变少,此时同源数据也会被影响。所有同源数据剩余的数据行仍保有对应关系。
在RETURN子句中进行去重时,情况却有所不同,此时同源数据不受影响。因此,数据行之间的对应关系可能丢失。
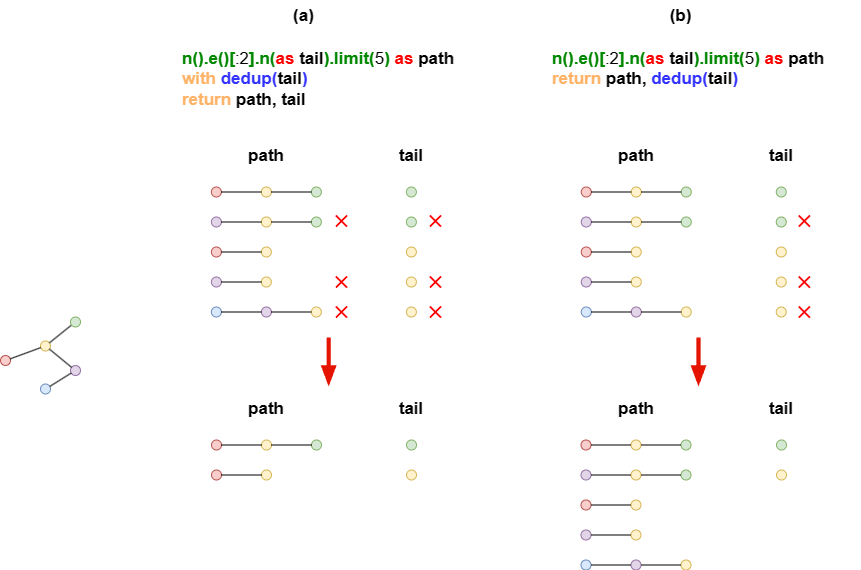
示例:tail和path同源,原本包含5行数据。
- (a):在
WITH子句中对tail进行去重,path中相应的数据行也被丢弃。 - (b):在
RETURN子句中对tail进行去重,path不受影响。
异源数据
由完全独立的不同子句产生的数据是异源的。异源数据通常数据行数不等,同一行数据也没有对应关系。
当异源数据流入同一子句时,它们通常会被自动裁剪至所有数据的最小长度,以确保它们可以被逐行处理。然而,此规则有两个特例:
WITH子句会对异源数据执行笛卡尔乘积处理。RETURN子句不对异源数据进行长度对齐裁剪,除非它们共同用于某些计算,或者包含聚合函数,
示例:n1和n2是异源的,数据行数不等;它们被共同用于路径查询子句,因此n2的第三行被丢弃,以保证n1和n2行数相等。
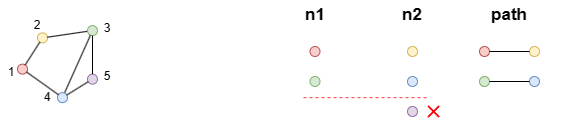
find().nodes({_uuid in [1, 3]}) as n1
find().nodes({_uuid in [2, 4, 5]}) as n2
n(n1).e().n(n2) as path
return path
WITH子句
示例:a和c同源,包含3行数据,它们与包含2行数据的b异源;WITH子句对c和b执行笛卡尔乘积,最后c和b都包含6行数据。
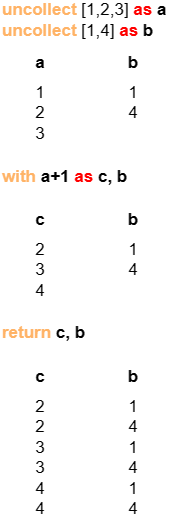
RETURN子句
示例:包含3行数据的a与包含2行数据的b异源。
- (a):
RETURN子句单独对b进行计算,不影响a,最后a返回3行数据,b+1返回2行数据。 - (b):
RETURN子句计算c时需要对a和b进行长度对齐裁剪,因此c只包含2行数据;单独返回的a和b不受影响。
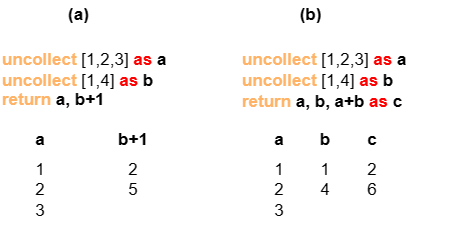
示例:RETURN子句对a进行聚合,造成b也只剩1行数据。