概述
WITH子句对别名代表的数据进行函数运算或笛卡尔积组合,并将结果传递给后面的子句。
语法
WITH <expression> as <alias>, <expression> as <alias>, ...
<expression>是别名运算表达式<alias>是为运算结果定义的别名,可省略
请留意:
- 输入到WITH子句的别名异源时,WITH会对异源别名按行进行笛卡尔积组合。
- 在WITH子句中对某个别名使用
dedup()函数去重时,会影响其同源别名的长度。
例如,以下语句中,别名n2和path同源,别名n1与它们异源:
- 第一个WITH子句对n2.color的去重操作会影响其同源数据流pnodes(path)的长度
- 第二个WITH子句对异源别名n1和list做笛卡尔积组合时,同样会影响list的同源别名color的长度
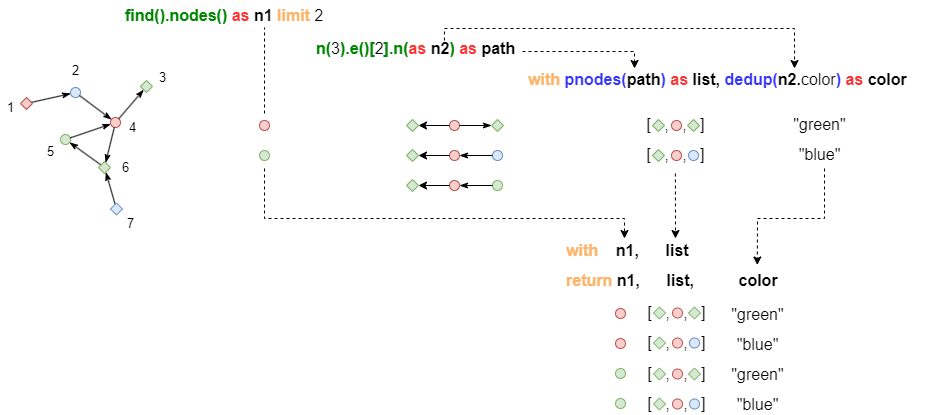
find().nodes() as n1 limit 2
n(3).e()[2].n(as n2) as path
with pnodes(path) as list, dedup(n2.color) as color
with n1, list
return n1, list, color
示例
示例图集
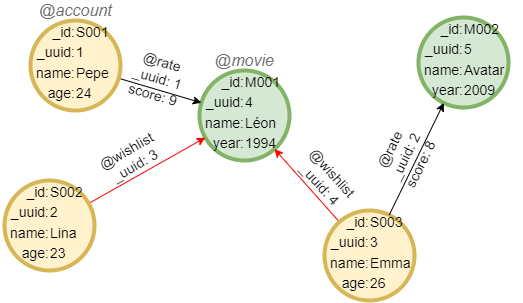
在一个空图集中,依次运行以下各行语句创建示例图集:
create().node_schema("account").node_schema("movie").edge_schema("rate").edge_schema("wishlist")
create().node_property(@*, "name").node_property(@account, "age", int32).node_property(@movie, "year", int32).edge_property(@rate, "score", int32)
insert().into(@account).nodes([{_id:"S001", _uuid:1, name:"Pepe", age:24}, {_id:"S002", _uuid:2, name:"Lina", age:23}, {_id:"S003", _uuid:3, name:"Emma", age:26}])
insert().into(@movie).nodes([{_id:"M001", _uuid:4, name:"Léon", year:1994}, {_id:"M002", _uuid:5, name:"Avatar", year:2009}])
insert().into(@rate).edges([{_uuid:1, _from_uuid:1, _to_uuid:4, score:9}, {_uuid:2, _from_uuid:3, _to_uuid:5, score:8}])
insert().into(@wishlist).edges([{_uuid:3, _from_uuid:2, _to_uuid:4}, {_uuid:4, _from_uuid:3, _to_uuid:4}])
函数运算
本例查找age属性值最小所有的@account点,返回他们的name属性:
find().nodes({@account}) as a
with min(a.age) as minAge
find().nodes({@account.age == minAge}) as b
return b.name
Lina
如果用以下按age属性值升序排列并限制返回一条数据的方法,可能无法得到所有年龄最小的@account点:
find().nodes({@account}) as a
order by a.age
return a.name limit 1
笛卡尔积组合
本例将@account点和@movie点配对组合,再查找“账号-[]-电影”1步路径,没有结果的组合返回null:
find().nodes({@account}) as a
find().nodes({@movie}) as b
with a, b
optional n(a).e().n(b) as p
return p{*}
Pepe --@rate--> Léon
null --null-- null
Lina --@wishlist--> Léon
null --null-- null
Emma --@wishlist--> Léon
Emma --@rate--> Avatar