传统意义上,图数据的存储结构有两类:相邻矩阵(Adjacency Matrix)和相邻链表(Adjacency List)。用相邻矩阵存储图数据的结果是会得到一个占用存储空间巨大但却相当稀疏的矩阵,这显然是一种非常低效的存储;相比而言,存储效率更高的相邻链表虽然在工业界中有着广泛的应用(例如Facebook社交图谱的底层技术架构代码Tao/Dragon采用的就是相邻链表的方式、Neo4j在处理超级节点时也采用这种双向链表的方式——也因此会遇到很大的性能挑战),但在遇到热点(一个顶点有极其多的邻边)时会产生超长链表,因而造成访问延迟高、无法实现并发操作等。因此,设计并实现更高效的图存储、图计算数据结构和架构是嬴图为整个数据库行业带来的最底层的创新与贡献。
图数据的存储结构必须同时满足以下几点:
- 高效的存储(读写都需要兼顾)
- 低延迟的访问(同上)
- 对并发的支持
首先,为满足前面几点要求,嬴图使用了基于C/C++中的动态向量数组设计并实现了向量计算引擎数据结构(Vector Computing),并针对传统图计算中核心数据结构仅单线程、单任务处理的特征,嬴图借助下列技术手段来支持单写-多读(single-writer-multiple-reader)甚至是支持多写多读的高并发工作方式:
- 版本号记录(Versioning)
- 读-拷贝-更新(RCU,Read-Copy-Update)
- 开放式寻址(Open-Addressing)
为了实现真正意义上的可扩展、高并发,嬴图解决了如下问题:
- 无阻塞或无锁式设计(Non-blocking and Lock-Free)
- 精细颗粒度的访问控制(Fine-granularity Access Control)
由于此二者都和并发访问控制高度相关,对此嬴图的工作重点是达到以下目标:
- 核心区域(访问控制):
- 区域足够小
- 执行时间足够短
- 通用数据访问:
- 避免不必要的访问(Unnecessary)
- 避免无意识的访问(Unintentional)
- 并发控制:
- 使用精细颗粒度的锁实现,例如lock-striping(条纹锁)
- 采用推测式上锁机制,例如交易过程中的合并锁机制(Transactional Lock Elision)
另一方面,在水平(横向)可扩展的图数据库架构设计中,还需要充分兼顾数据分片与并发访问控制,在嬴图v4.x版本中支持大规模水平分布式部署模式,并兼容高性能HTAP核心架构(可理解为多个 HTAP集群通过NameServer的级联模式)。目前该套架构(Grid Architecture)已经在多家大型商业银行生产系统部署上线,并成功支持超过千亿规模的生产环境海量数据的实时化处理(如下图所示)。
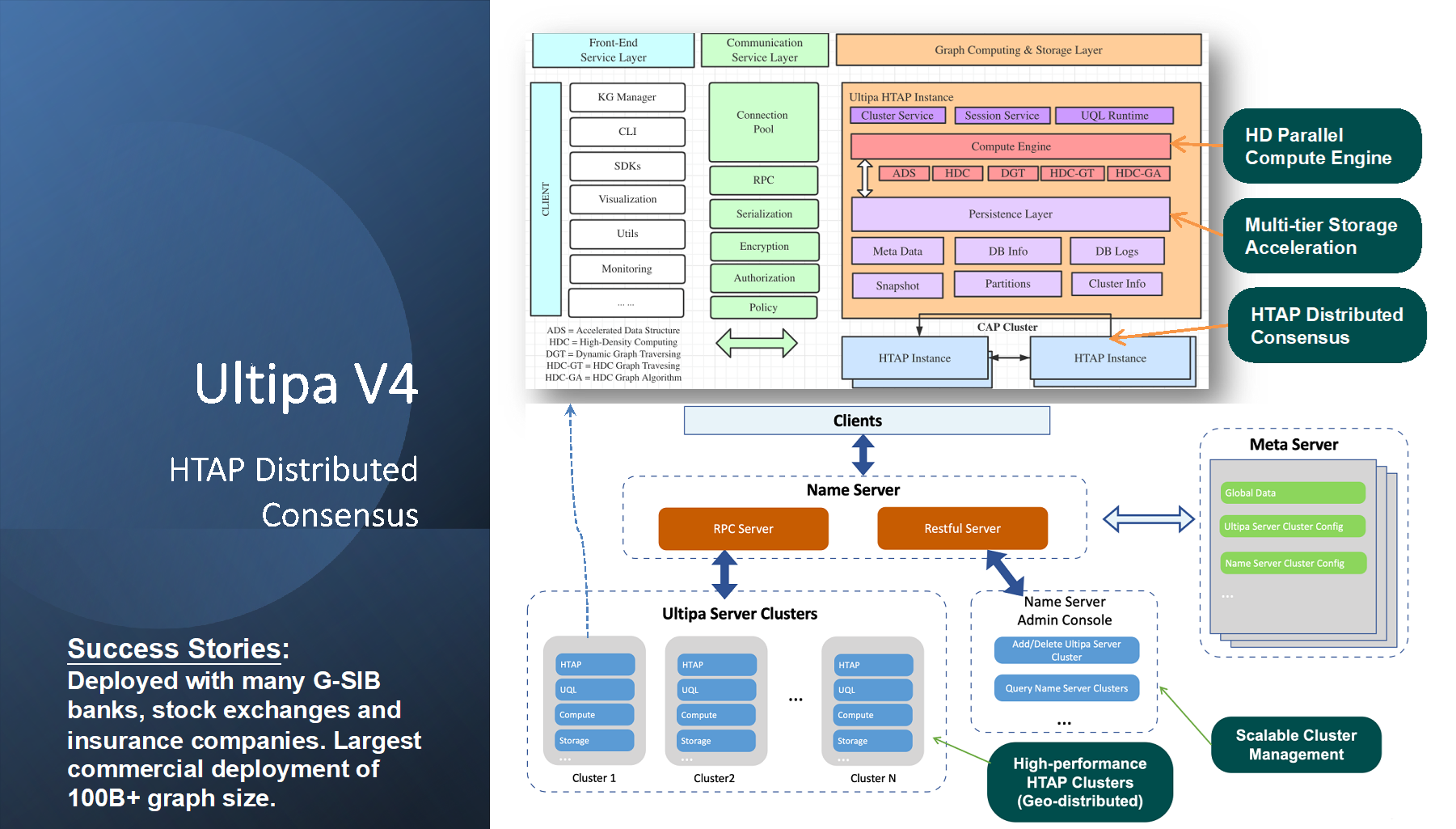
大规模水平分布式系统架构(Grid + HTAP)