概述
Node2Vec是一种半监督(Semi-supervised)算法,旨在学习图中节点的特征,同时有效地保留它们的邻域信息。它引入了一种灵活的搜索策略,可以探索节点的BFS和DFS邻域。此外,它还将Skip-gram模型扩展到图中,用于训练节点嵌入。Node2Vec由斯坦福大学的A. Grover 和J. Leskovec在2016年开发。
- A. Grover, J. Leskovec, node2vec: Scalable Feature Learning for Networks (2016)
基本概念
节点相似性
Node2Vec学习将节点映射到低维向量空间,同时确保在网络中相似的节点在向量空间中具有接近的嵌入。
网络中的节点经常表现两种相似性:
1. 同质性
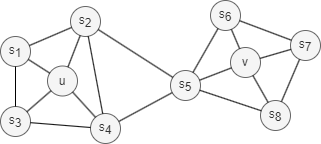
同质性(Homophily)在网络中是指具有相似属性、特征或行为的节点更有可能相互连接在一起,或者属于同一个或相似的社区(上图中的节点u和s1属于同一社区)。
例如,在社交网络中,具有类似背景、兴趣或观点的个体更有可能建立连接。
2. 结构等效性
在网络中,结构等效性(Structural Equivalence)是指根据节点在网络内的“结构角色”(Structural Role)而被视为等效的概念。结构等效的节点具有类似的连接模式和与其他节点的关系(即局部拓扑结构),即使它们特征不同(上图中的节点u和v都在各自的社区中充当枢纽的角色)。
例如,在社交网络中,结构等效的个体可能在其社交群体中占据类似的位置。
与同质性不同的是,结构等效性不强调连接性;节点可能在网络中相距较远,但仍有相同的结构角色。
在讨论结构等效性时,有两个要点:首先,在实际网络中实现完全的结构等效是不常见的,因此我们更关注评估“结构相似性”(Structural Similarity)。其次,随着分析范围扩大,两个节点之间的结构相似性程度往往会降低。
搜索策略
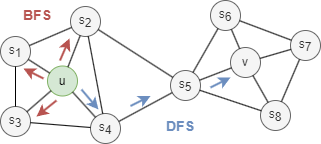
通常来说,有两种极端的搜索策略来生成包含k个节点的邻域集合NS:
- 广度优先搜索(BFS):NS仅包含与起始节点直接相邻的节点。例如,在上图中,如果k = 3,NS(u) = {s1, s2, s3}。
- 深度优先搜索(DFS):NS 包括距离起始节点逐渐远的节点。例如,在上图中,如果k = 3,NS(u) = {s4, s5, v}。
BFS和DFS策略在生成反映节点之间同质性或结构等效性的嵌入时起关键作用:
- 通过BFS抽样的邻域生成的嵌入与结构等效性密切相关。通过限制搜索范围在附近的节点,BFS 能获取起始节点邻域的微观视图,这通常足以描述其局部拓扑。
- 通过DFS抽样的邻域生成的嵌入与同质性密切相关。通过远离起始节点,DFS能获得其邻域的宏观视图,这对于推断社区中节点之间依赖关系是至关重要的。
Node2Vec框架
1. Node2Vec游走
Node2Vec使用带有返回参数(Return)p和远近参数(In-out)q的有偏随机游走。
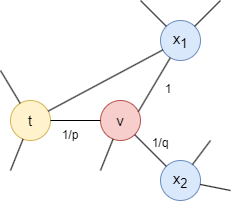
考虑刚刚经过边(t,v)现在到达节点v的随机游走,游走的下一步由从v出发的所有边(v,x)的转移概率决定,这些概率与边的权重成正比(非加权图中所有边的权重为1)。边(v,x)的权重会根据节点t和x间的最短距离dtx被p和q所调整:
- 如果dtx = 0,将边的权重乘以
1/p。在上图中,dtt = 0。参数p影响返回到刚刚离开的节点的可能性。当p< 1时,更有可能回退一步;当p> 1时反之。 - 如果dtx = 1,边的权重保持不变。在上图中,dtx1 = 1。
- 如果dtx = 2,将边的权重乘以
1/q。在上图中,dtx2 = 2。参数q决定随机游走是朝近处移动(q> 1)还是朝远处移动(q< 1)。
请注意,dtx一定是{0, 1, 2}中的一个。
通过这两个参数,Node2Vec提供了一种在随机游走期间权衡探索(Exploration)和开发(Exploitation)的方式,从而能够产生从同质性到结构等效性的一系列表示。
2. 节点嵌入
从随机游走获取的节点序列会作为输入进入Skip-gram模型。Node2Vec基于预测误差使用SGD来调整模型参数,并且通过负采样(Negative Sampling)和二次采样(Subsampling)等技术进行优化。
特殊说明
- Node2Vec的结果与边的方向无关。
示例图集
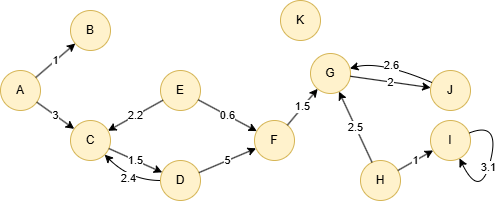
创建示例图集:
// 在空图集中逐行运行以下语句
create().edge_property(@default, "score", float)
insert().into(@default).nodes([{_id:"A"},{_id:"B"},{_id:"C"},{_id:"D"},{_id:"E"},{_id:"F"},{_id:"G"},{_id:"H"},{_id:"I"},{_id:"J"},{_id:"K"}])
insert().into(@default).edges([{_from:"A", _to:"B", score:1}, {_from:"A", _to:"C", score:3}, {_from:"C", _to:"D", score:1.5}, {_from:"D", _to:"C", score:2.4}, {_from:"D", _to:"F", score:5}, {_from:"E", _to:"C", score:2.2}, {_from:"E", _to:"F", score:0.6}, {_from:"F", _to:"G", score:1.5}, {_from:"G", _to:"J", score:2}, {_from:"H", _to:"G", score:2.5}, {_from:"H", _to:"I", score:1}, {_from:"I", _to:"I", score:3.1}, {_from:"J", _to:"G", score:2.6}])
创建HDC图集
将当前图集全部加载到HDC服务器hdc-server-1上,并命名为 hdc_node2vec:
CALL hdc.graph.create("hdc-server-1", "hdc_node2vec", {
nodes: {"*": ["*"]},
edges: {"*": ["*"]},
direction: "undirected",
load_id: true,
update: "static",
query: "query",
default: false
})
hdc.graph.create("hdc_node2vec", {
nodes: {"*": ["*"]},
edges: {"*": ["*"]},
direction: "undirected",
load_id: true,
update: "static",
query: "query",
default: false
}).to("hdc-server-1")
参数
算法名:node2vec
参数名 |
类型 |
规范 |
默认值 |
可选 |
描述 |
|---|---|---|---|---|---|
ids |
[]_id |
/ | / | 是 | 通过_id指定随机游走的起点;若未设置则计算所有点 |
uuids |
[]_uuid |
/ | / | 是 | 通过_uuid指定随机游走的起点;若未设置则计算所有点 |
walk_length |
Integer | ≥1 | 1 |
是 | 每次游走的深度,即访问的节点数量 |
walk_num |
Integer | ≥1 | 1 |
是 | 从每个指定节点开始的游走次数 |
p |
Float | >0 | 1 |
是 | 返回参数;数值越大,回走概率越小 |
q |
Float | >0 | 1 |
是 | 远近参数;数值大于1时,倾向于在同级游走,否则倾向于向远处游走 |
edge_schema_property |
[]"<@schema.?><property>" |
/ | / | 是 | 作为权重的数值类型边属性,权重值为所有指定属性值的总和;不包含指定属性的边将被忽略 |
window_size |
Integer | ≥1 | / | 否 | 上下文最大长度 |
dimension |
Integer | ≥2 | / | 否 | 嵌入向量的维度 |
loop_num |
Integer | ≥1 | / | 否 | 训练迭代轮数 |
learning_rate |
Float | (0,1) | / | 否 | 模型训练的初始学习率,在每轮训练迭代后逐渐减少,直至达到min_learning_rate |
min_learning_rate |
Float | (0,learning_rate) |
/ | 否 | 学习率的最低阈值,在训练过程中逐渐减少 |
neg_num |
Integer | ≥1 | 5 |
是 | 每个正样本生成的负样本数量,建议设置在1到10之间 |
resolution |
Integer | ≥1 | 1 |
是 | 用于提高负采样效率的参数;数值越高,越能更好地接近原始噪声分布;建议设置为10、100等 |
sub_sample_alpha |
Float | / | 0.001 |
是 | 影响高频节点下采样概率的因子;数值越高,采样概率越大;设置为≤0时,不应用二次采样 |
min_frequency |
Integer | / | / | 否 | 训练“语料库”中出现次数低于该阈值的点将从“词汇表”中排除,并在嵌入训练中被忽略;设置为≤0时,保留所有点 |
return_id_uuid |
String | uuid, id, both |
uuid |
是 | 在结果中使用_uuid、_id或同时使用两者来表示点 |
limit |
Integer | ≥-1 | -1 |
是 | 限制返回的结果数;-1返回所有结果 |
文件回写
CALL algo.node2vec.write("hdc_node2vec", {
params: {
return_id_uuid: "id",
walk_length: 10,
walk_num: 20,
p: 0.5,
q: 1000,
window_size: 5,
dimension: 5,
loop_number: 10,
learning_rate: 0.01,
min_learning_rate: 0.0001,
neg_number: 9,
resolution: 100,
sub_sample_alpha: 0.001,
min_frequency: 3
},
return_params: {
file: {
filename: "embeddings"
}
}
})
algo(node2vec).params({
projection: "hdc_node2vec",
return_id_uuid: "id",
walk_length: 10,
walk_num: 20,
p: 0.5,
q: 1000,
window_size: 5,
dimension: 5,
loop_number: 10,
learning_rate: 0.01,
min_learning_rate: 0.0001,
neg_number: 9,
resolution: 100,
sub_sample_alpha: 0.001,
min_frequency: 3
}).write({
file:{
filename: 'embeddings'
}
})
_id,embedding_result
J,0.0800537,0.0883881,-0.0766052,-0.0655609,0.0273315,
D,0.0604218,0.0188171,0.00422668,-0.0720703,0.0443695,
F,-0.0871277,0.0249908,-0.0150269,-0.0191437,-0.0663147,
H,-0.0376434,0.0515869,0.0605072,0.0593811,0.0319489,
B,0.030896,-0.0760529,-0.0819153,0.0993927,0.0760254,
A,0.0618011,-0.0120789,0.0803131,-0.0098999,0.0146942,
E,-0.00298462,-0.0596649,0.0262451,-0.0267487,-0.0765076,
K,0.0950836,0.0875854,-0.0219025,-0.0045227,0.0101837,
C,-0.0727539,-0.0801422,0.091095,0.00126038,-0.0516479,
I,-0.0608429,-0.0615295,0.0339386,0.00402832,0.0266205,
G,-0.0842712,-0.0761566,-0.0026001,0.0228729,0.0509949,
数据库回写
将结果中的embedding_result值写入指定点属性。该属性类型为float[]。
CALL algo.node2vec.write("hdc_node2vec", {
params: {
return_id_uuid: "id",
walk_length: 10,
walk_num: 20,
p: 0.5,
q: 1000,
window_size: 5,
dimension: 5,
loop_number: 10,
learning_rate: 0.01,
min_learning_rate: 0.0001,
neg_number: 9,
resolution: 100,
sub_sample_alpha: 0.001,
min_frequency: 3
},
return_params: {
db: {
property: "vector"
}
}
})
algo(node2vec).params({
projection: "hdc_node2vec",
return_id_uuid: "id",
walk_length: 10,
walk_num: 20,
p: 0.5,
q: 1000,
window_size: 5,
dimension: 5,
loop_number: 10,
learning_rate: 0.01,
min_learning_rate: 0.0001,
neg_number: 9,
resolution: 100,
sub_sample_alpha: 0.001,
min_frequency: 3
}).write({
db: {
property: "vector"
}
})
完整返回
CALL algo.node2vec("hdc_node2vec", {
params: {
return_id_uuid: "id",
walk_length: 10,
walk_num: 20,
p: 0.5,
q: 1000,
window_size: 5,
dimension: 4,
loop_number: 10,
learning_rate: 0.01,
min_learning_rate: 0.0001,
neg_number: 9,
resolution: 100,
sub_sample_alpha: 0.001,
min_frequency: 3
},
return_params: {}
}) YIELD embeddings
RETURN embeddings
exec{
algo(node2vec).params({
return_id_uuid: "id",
walk_length: 10,
walk_num: 20,
p: 0.5,
q: 1000,
window_size: 5,
dimension: 4,
loop_number: 10,
learning_rate: 0.01,
min_learning_rate: 0.0001,
neg_number: 9,
resolution: 100,
sub_sample_alpha: 0.001,
min_frequency: 3
}) as embeddings
return embeddings
} on hdc_node2vec
结果:
_id |
embedding_result |
|---|---|
| J | [0.100067138671875,0.11048507690429688,-0.09575653076171875,-0.08195114135742188] |
| D | [0.0341644287109375,0.07552719116210938,0.02352142333984375,0.005283355712890625] |
| F | [-0.090087890625,0.055461883544921875,-0.10890960693359375,0.031238555908203125] |
| H | [-0.0187835693359375,-0.023929595947265625,-0.08289337158203125,-0.047054290771484375] |
| B | [0.064483642578125,0.07563400268554688,0.07422637939453125,0.039936065673828125] |
| A | [0.0386199951171875,-0.09506607055664063,-0.10239410400390625,0.12424087524414063] |
| E | [0.09503173828125,0.07725143432617188,-0.01509857177734375,0.10039138793945313] |
| K | [-0.0123748779296875,0.018367767333984375,-0.00373077392578125,-0.07458114624023438] |
| C | [0.032806396484375,-0.033435821533203125,-0.09563446044921875,0.11885452270507813] |
| I | [0.1094818115234375,-0.027378082275390625,-0.00565338134765625,0.012729644775390625] |
| G | [-0.0909423828125,-0.10017776489257813,0.11386871337890625,0.001575469970703125] |
流式返回
CALL algo.node2vec("hdc_node2vec", {
params: {
return_id_uuid: "id",
walk_length: 10,
walk_num: 20,
p: 0.5,
q: 1000,
window_size: 5,
dimension: 5,
loop_number: 10,
learning_rate: 0.01,
min_learning_rate: 0.0001,
neg_number: 9,
resolution: 100,
sub_sample_alpha: 0.001,
min_frequency: 3
},
return_params: {
stream: {}
}
}) YIELD embeddings
RETURN embeddings
exec{
algo(node2vec).params({
return_id_uuid: "id",
walk_length: 10,
walk_num: 20,
p: 0.5,
q: 1000,
window_size: 5,
dimension: 5,
loop_number: 10,
learning_rate: 0.01,
min_learning_rate: 0.0001,
neg_number: 9,
resolution: 100,
sub_sample_alpha: 0.001,
min_frequency: 3
}) as embeddings
return embeddings
} on hdc_node2vec
结果:
_id |
embedding_result |
|---|---|
| J | [0.08005370944738388,0.08838806301355362,-0.07660522311925888,-0.06556091457605362,0.02733154222369194] |
| D | [0.06042175367474556,0.01881713792681694,0.0042266845703125,-0.07207031548023224,0.04436950758099556] |
| F | [-0.087127685546875,0.02499084547162056,-0.015026855282485485,-0.01914367638528347,-0.066314697265625] |
| H | [-0.0376434326171875,0.05158691480755806,0.06050720065832138,0.05938110500574112,0.03194885328412056] |
| B | [0.03089599683880806,-0.07605285942554474,-0.08191528171300888,0.09939269721508026,0.07602538913488388] |
| A | [0.06180114671587944,-0.01207885704934597,0.08031310886144638,-0.009899902157485485,0.0146942138671875] |
| E | [-0.0029846192337572575,-0.05966491624712944,0.0262451171875,-0.0267486572265625,-0.076507568359375] |
| K | [0.09508361667394638,0.08758544921875,-0.02190246619284153,-0.0045227049849927425,0.01018371619284153] |
| C | [-0.07275390625,-0.08014221489429474,0.091094970703125,0.0012603759532794356,-0.05164794996380806] |
| I | [-0.06084289401769638,-0.06152953952550888,0.03393859788775444,0.0040283203125,0.02662048302590847] |
| G | [-0.08427123725414276,-0.0761566162109375,-0.0026000975631177425,0.0228729248046875,0.050994873046875] |