概述
FOR语句展开一个列表,并相应地扩展中间结果表。
<for statement> ::=
"FOR" <binding variable> "IN" <list value expression> [ <ordinality or offset> ]
<ordinality or offset> ::=
"WITH" { "ORDINALITY" | "OFFSET" } <binding variable>
详情
<ordinality or offset>定义的变量可以用来表示元素在列表中的位置:ORDINALITY提供基于1的索引,即1、2、3……OFFSET提供基于0的索引,即0、1、2……
<ordinality or offset>中绑定的变量与紧跟FOR的绑定变量名称必须不同。
展开一个简单列表
FOR item IN [1,1,2,3,null]
RETURN item
结果:
| item |
|---|
| 1 |
| 1 |
| 2 |
| 3 |
null |
FOR item IN [[1,2], [2,3,5]]
RETURN item
结果:
| item |
|---|
| [1,2] |
| [2,3,5] |
展开一个变量
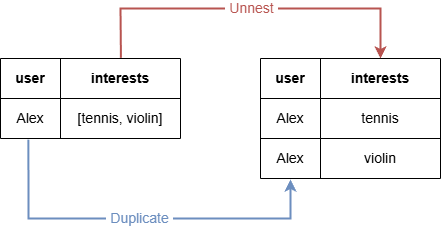
LET user = "Alex"
LET interests = ["tennis", "violin"]
FOR interest IN interests
RETURN user, interest
结果:
| user | interest |
|---|---|
| Alex | tennis |
| Alex | violin |
此查询中,FOR语句将工作表interests列中的列表展开为两条记录。由此,user列中对应的记录也复制为两条。
展开一个组变量
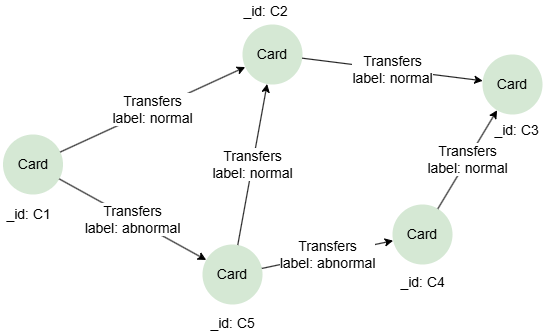
CREATE GRAPH myGraph {
NODE Card (),
EDGE Transfers ()-[{label string}]->()
} PARTITION BY HASH(Crc32) SHARDS [1]
INSERT (c1:Card {_id: 'C1'}),
(c2:Card {_id: 'C2'}),
(c3:Card {_id: 'C3'}),
(c4:Card {_id: 'C4'}),
(c5:Card {_id: 'C5'}),
(c1)-[:Transfers {label: 'normal'}]->(c2),
(c1)-[:Transfers {label: 'abnormal'}]->(c5),
(c5)-[:Transfers {label: 'normal'}]->(c2),
(c5)-[:Transfers {label: 'abnormal'}]->(c4),
(c2)-[:Transfers {label: 'normal'}]->(c3),
(c4)-[:Transfers {label: 'normal'}]->(c3)
获取C1和C3间的一条最短路径,并返回路径中边属性label的值:
MATCH SHORTEST 1 ({_id: "C1"})-[trans:Transfers]-{1,6}({_id: "C3"})
FOR tran IN trans
RETURN tran.label
结果:
| tran.label |
|---|
| normal |
| normal |
本查询中,带量词路径中声明的trans是一个组变量,代表路径中的边组成的列表,使用FOR可将其展开,以便单独引用每条边。
WITH ORDINALITY
将列表中处于偶数位置的元素收集到新列表中:
FOR item in ["a", "b", "c", "d"] WITH ORDINALITY index // index从1开始
FILTER index %2 = 0
RETURN collect_list(item)
结果:
| collect_list(item) |
|---|
| ["b","d"] |
WITH OFFSET
返回列表中的第二个元素:
FOR item in ["a", "b", "c", "d"] WITH OFFSET index // index从0开始
FILTER index = 1
RETURN item
结果:
| item |
|---|
| b |