概述
由于原始Skip-gram模型的计算量非常高,因此几乎无法应用到实际场景中。
矩阵和的大小取决于词汇量的大小(例如,)和嵌入维度(例如,),其中每个矩阵通常包含数百万个权重(例如,百万)! 因此,Skip-gram的神经网络变得非常庞大,需要大量的训练样本来调整这些权重。
另外,在每个反向传播步骤中,矩阵的所有输出向量都会被更新,但其中的绝大多数的向量与目标词和上下文词都没有关系。鉴于的尺寸巨大,梯度下降过程将非常缓慢。
还有一个显著的成本来自于Softmax函数,该函数归一化分母的计算涉及到词汇表中的所有单词。
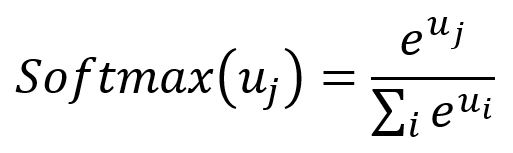
T. Mikolov和其他研究人员引入了一些Skip-gram模型的优化技术,包括二次采样(Subsampling)和负采样(Negative Sampling)。这些方法不仅加速了训练过程,还提高了嵌入向量的质量。
- T. Mikolov, I. Sutskever, K. Chen, G. Corrado, J. Dean, Distributed Representations of Words and Phrases and their Compositionality (2013)
- X. Rong, word2vec Parameter Learning Explained (2016)
二次采样
在语料库中,有些词会频繁出现,如"the"、"and"、"is"等。这些高频词会带来一些问题:
- 它们的语义价值有限。例如,模型更多地受益于"France"和"Paris"的共现,而不是"France"和"the"频繁共现的情况。
- 会存在过多包含这些词的训练样本,超过了训练相应向量所需的数量。
二次采样(Subsampling)方法就用于解决这个问题:对于训练集中的每个单词,设定一定的机会将其丢弃,而不常见的单词较少被丢弃。
首先,通过下式计算保留一个单词的概率:
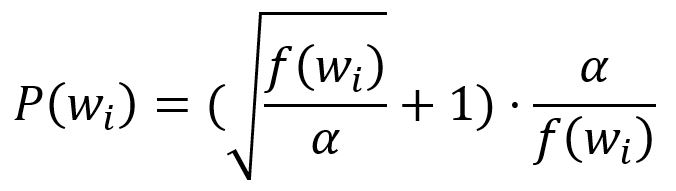
其中,表示第个单词出现的频率,是影响概率分布的因子,默认大小为。
接着,生成一个大小介于和之间的随机数。如果小于这个数,则丢弃这个单词。
例如,如果,当时,,这意味着频率为或更低的单词将完全被保留。对于高频词汇,比如,有。
如果,那么频率为或更低的单词将百分之百被保留。对于相同的高频词汇,此时有。
因此,较大的会增加高频词被二次采样的概率。
举个例子,在训练句子"Graph is a good way to visualize data"中,如果单词"a"被丢弃,那么这个句子的采样结果将不会包含以"a"作为目标词或上下文词的样本。
负采样
在负采样(Negative Sampling)方法中,每当对目标词进行采样获得一个上下文词作为正样本时,同时选择个单词作为负样本。
我们讨论原始Skip-gram模型时使用了一个简单的语料库,这个语料库包含一个由10个单词组成的词汇表:graph、is、a、good、way、to、visualize、data、very和at。举例来说,当使用滑动窗口生成正样本(target, content): (is, a)时,我们同时选择个负样本单词graph、data和at。
| 目标词 | 上下文词 | 期待的输出 | |
|---|---|---|---|
| is | 正样本 | a | 1 |
| 负样本 | graph | 0 | |
| data | 0 | ||
| at | 0 |
使用负采样后,模型的训练目标从预测目标词的上下文词转变为一个二分类任务。在这个设置中,正例单词的输出期望为,而负例单词的输出期望为;其他无关的单词将被忽略。
因此,在反向传播过程中,模型只更新与正例和负例单词相关联的输出向量,以提高模型的分类性能。
考虑一个情景,其中,。当应用参数的负采样时,矩阵中只有个权重需要更新,这相当于没有应用负采样时需要更新的百万个权重的!
我们的实验表明,在小型训练数据集中,值在的范围内即可;而对于大型数据集,值可以更小,大约。(Mikolov 等)
选择负样本单词需要一个概率分布,其基本原则是优先考虑语料库中的高频词汇。然而,如果选择完全基于词频,可能导致高频词被过度表示而低频词被忽视。为了取得平衡,通常使用将词频提升幂次的经验分布:
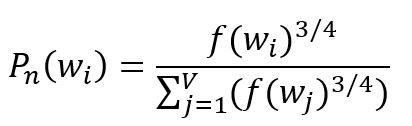
其中,表示第个单词的频率,的下标表示"噪音"的概念,因此也被称为噪音分布(Noise Distribution)。
在极端情况下,如果语料库只包含两个单词,频率分别为和,使用上式调整后的概率分别为和。这种调整在一定程度上缓解了由频率差异引起的固有选择偏差。
处理大型语料库时,负采样在计算效率方面可能存在挑战。因此,我们进一步采用一个resolution参数来重新缩放噪音分布。较大的resolution值能提供对原始噪音分布的更接近的近似。
优化的模型训练
前向传播过程
我们将以目标词is、正样本词a和负样本词graph、data和at为例进行说明:

在负采样中,Skip-gram模型使用以下变化的Softmax函数,实际上也是 的Sigmoid函数()。这个函数将的所有分量映射到到的范围内:
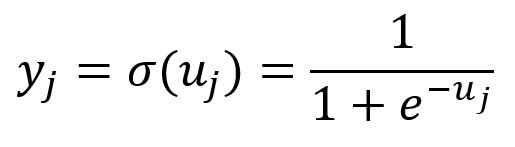
反向传播过程
如前所述,期望正样本单词的输出(表示为)为;而对应的个负样本单词的输出(表示为)为。因此,模型训练的目标是最大化和,这可以等价为最大化它们的乘积:
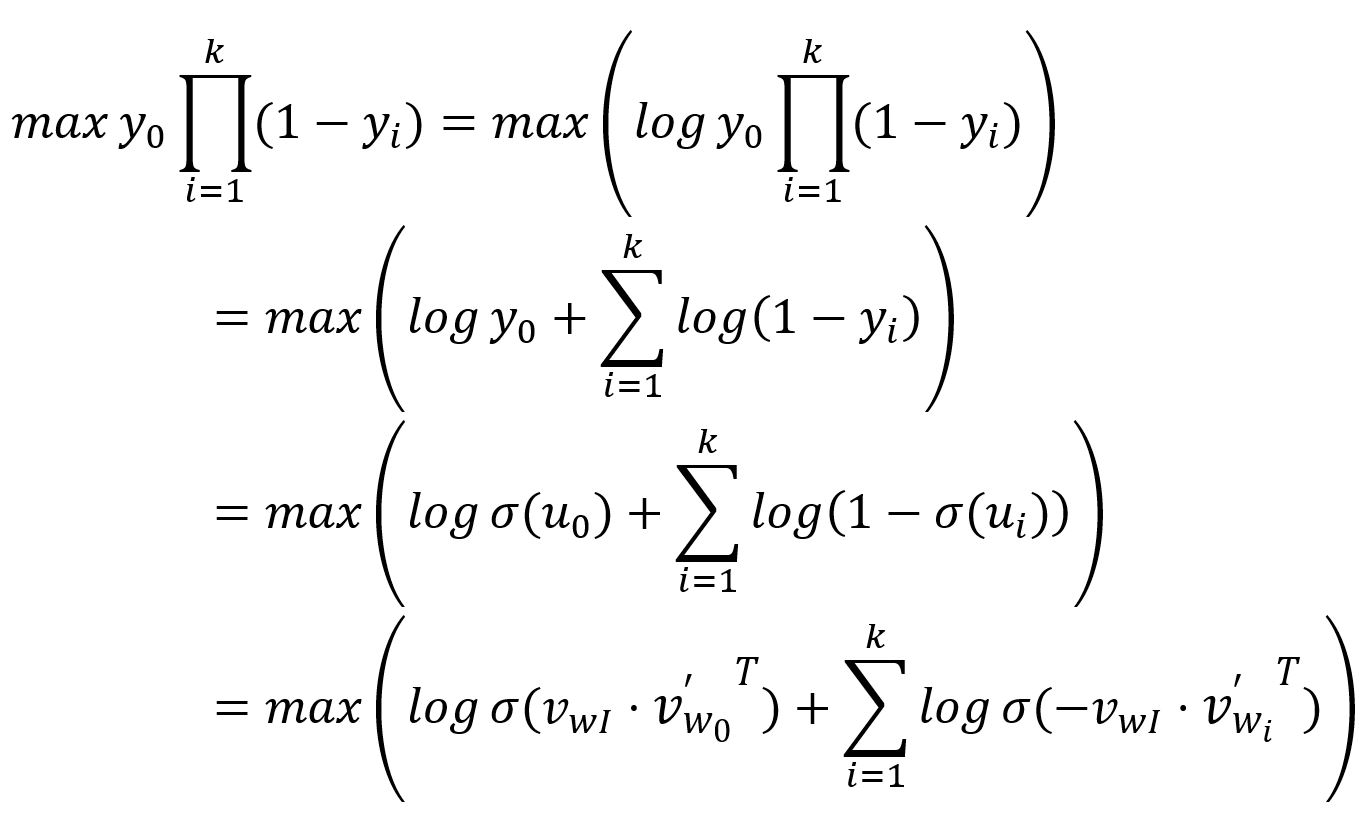
损失函数可以通过将上述问题转化为最小化问题来获得:
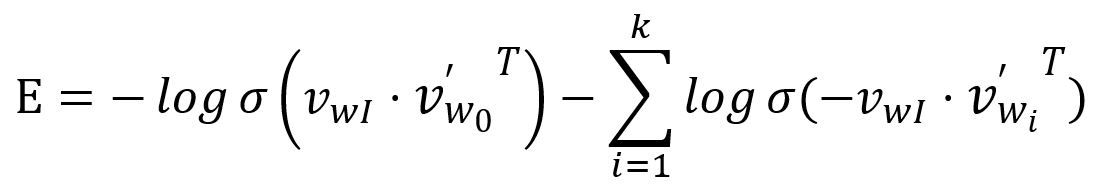
分别求相对于和的偏导数:
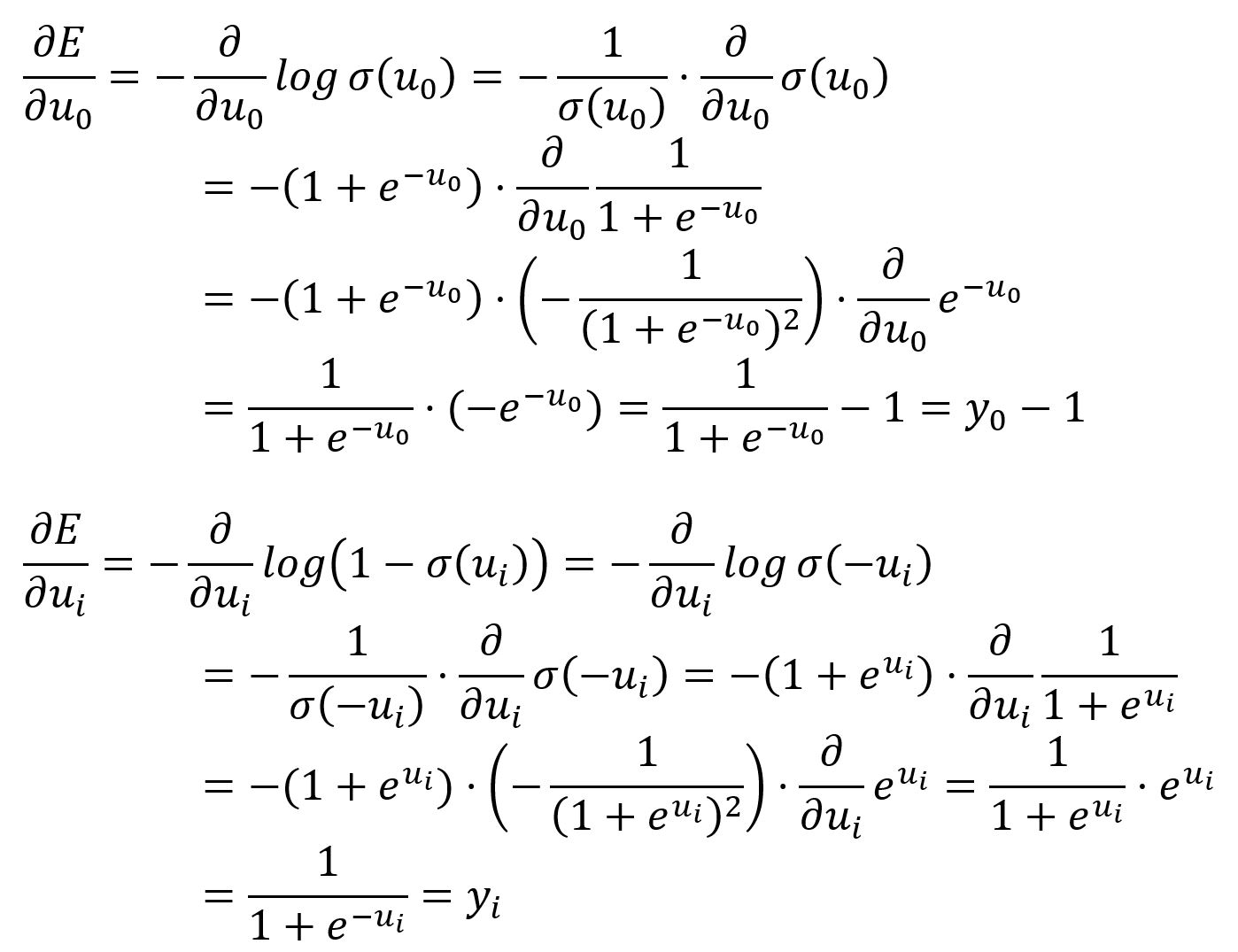
和具有与原始 Skip-gram模型中类似的含义,可以理解为从输出向量中减去期望向量:
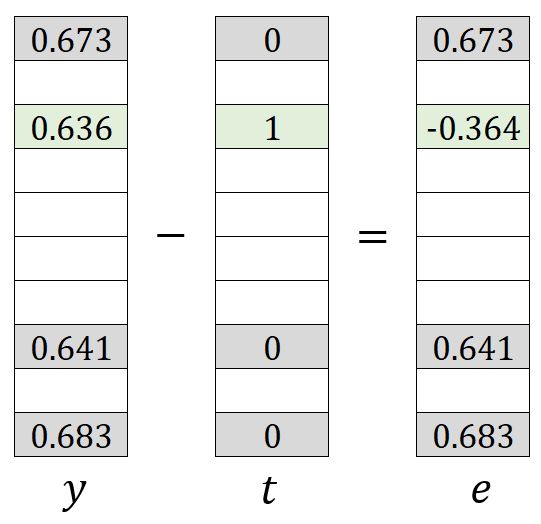
更新矩阵和 权重的过程与Skip-gram的原始形式类似。然而,只有中的 、、、、、、和以及中的和会被更新。