什么是图嵌入?
图嵌入(Graph Embedding)技术能够生成图的潜在向量表示(Latent Vector Representations)。它可以针对图的不同层次执行,其中主要的两个是:
- 节点嵌入(Node Embedding):将图中的每个节点映射到一个向量。
- 图嵌入(Graph Embedding):将整个图映射到一个向量。
从这个过程中产生的每个向量(Vector)也被称为嵌入(Embedding)或表示(Representation)。
"潜在"一词表明这些向量是从数据中推断或学习得到的。它们是以一种能够保留图结构(节点之间的连接方式)和/或属性(节点和边的属性)的方式创建的,通常不那么显而易见。
以节点嵌入为例,在图中两个节点越相似,它们映射到向量空间中的嵌入就越接近。
下面展示了在Zachary's karate club图(左)上运行节点嵌入算法DeepWalk的结果(右)。在图中,节点的颜色表示基于模块度的社区划分。当所有节点都被转化为二维向量,可以明显地看出,同一个社区中的节点在向量空间中相对靠近。
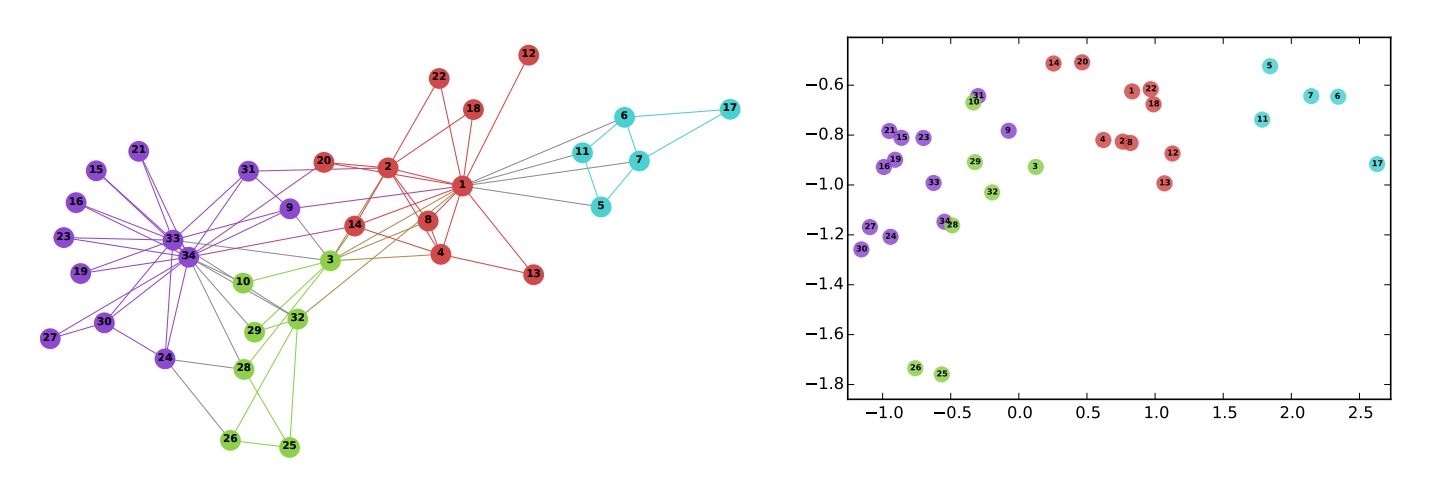 B. Perozzi, et al., DeepWalk: Online Learning of Social Representations (2014)
B. Perozzi, et al., DeepWalk: Online Learning of Social Representations (2014)嵌入的相似度
嵌入的相似度或接近程度通常是指在向量空间中两个嵌入的位置的靠近程度。在向量空间中,如果两个嵌入彼此靠近,这反映它们对应的元素在原始图中具有一定程度的相似性。
在实际应用中,通常使用不同的距离或相似度指标来度量嵌入的相似度,例如欧几里得距离和余弦相似度。
嵌入的维度
嵌入维度(Dimension)的选择,也称为嵌入大小或向量大小,取决于数据复杂性、具体任务和计算资源等诸多因素。虽然没有通用的标准,但实际应用中常见的嵌入维度范围通常在50到300之间。
较小维度的嵌入可以加快计算和比较的速度。因此,推荐从较小的维度开始,根据需要逐渐扩展维度,根据实验和验证来评估与具体应用相关的性能指标。
为什么需要图嵌入?
降维
由于包含复杂的关系(不是因为图占用的物理空间维度),图通常被视为高维数据。
图嵌入作为一种降维方法,旨在从图中捕获重要的信息,同时大幅减少与高维度相关的复杂性和计算挑战。在降维和嵌入领域,相对于原始的高维数据,即使是几百个维度,仍被视为低维。
在数据科学中更具兼容性
与数据科学领域中,向量空间相较于图而言,更能够兼容各种数学和统计学方法。相反,由节点和边构成的图能够使用的分析方法非常有限。
向量是一组数值特征,这种固有优势使它们天生适用于数学运算和统计分析。在向量空间中,如加法和点积等的基本计算操作十分简单且高效,其效率远胜在图上执行类似的操作。
图嵌入的应用
图嵌入作为图的预处理步骤,充当了桥梁的角色。一旦我们为节点、边或图生成了嵌入,就可以在各种下游任务中使用这些嵌入。这些任务包括节点分类、图分类、链接预测、聚类和社区检测、可视化等等。
图分析
我们有许多适用于不同图分析目的的图算法。尽管它们提供许多有价值的信息,但也有局限性。比如,这些算法往往依赖于手工从邻接矩阵中提取的特征,可能无法完全捕捉复杂的数据细微差异。此外,为了在大规模图上高效地执行这些算法,需要大量的计算工作。
而这就是图嵌入能发挥作用的地方。通过创建低维的表示,嵌入为各种分析和任务提供了更丰富和适配的输入。这些学习到的向量能增强图分析的效率和准确性,比直接在高维图上执行表现更为出色。
例如,考虑节点的相似性分析。传统的相似性算法通常分为两类:基于邻域的相似性和基于属性的相似性。前者由杰卡德相似度和重叠相似度代表,它们通过节点的一步邻域计算相似度分数。后者由欧几里德距离和余弦相似度代表,它们使用多个数值类型的节点属性的值计算相似度分数。
虽然这些方法各有优点,但它们只能捕捉表层的节点特征,适用性有限。但如果通过节点嵌入获取图的潜在和深层信息,这些相似性算法就能有更丰富的输入数据。这种融合使得算法能够考虑更复杂的关系,从而产生更有意义的分析结果。
机器学习与深度学习
当代的机器学习(ML, Machine Learning)和深度学习(DL, Deep Learning)技术已经对各个领域进行了革新,然而却很难直接将它们应用于图。与传统的结构化数据(例如表格数据)相比,图的独特特征使它不太适合标准的ML/DL方法。
虽然也有其他方法可以将ML/DL应用于图,图嵌入却是其中最简单有效的。通过将图或图元素转化为连续的向量,嵌入不仅能抽象由任意图大小和动态拓扑带来的复杂性,还能很好地兼容现代ML/DL的工具集和库。
当然,仅仅将数据转化为ML/DL可接受的格式并不够。在将数据输入到ML/DL模型之前,特征学习也是一个重要的挑战。传统的特征工程既耗时又不太准确。嵌入所学习到的特征,包含了图的结构和属性信息,能够加强模型对数据的理解。
想象一个社交网络,其中节点代表个体,边代表社交联系,任务是预测个体的政治倾向。传统方法可能涉及手工提取特征,如每个个体的朋友数量、平均年龄和教育水平等,然后再将这些特征输入到类似决策树或随机森林这样的ML模型中。然而,这种方法的问题是将每个个体的社交联系视为独立的特征,忽视了图中复杂的关系。
相比之下,利用图嵌入可以为每个个体创建更复杂的集成信息,从而产生更准确和综合考虑上下文的预测结果。