概述
SybilRank(西比尔排名)是一种通过提前终止的随机游走对网络中节点的可信度进行排名的算法,主要应用于在线社交网络(Online Social Network, OSN)。OSN的普及伴随着越来越多的Sybil攻击,恶意攻击者会创建多个虚假帐户(Sybils),目的是发送垃圾邮件、分发恶意软件、操纵投票或内容浏览量等。
SybilRank算法是由Qiang Cao等人于2012年提出的,它具有良好的计算性价比和大图可扩展性(可并行),能帮助社交平台或相关企业更高效地定位虚假账号。
- Q. Cao, M. Sirivianos, X. Yang, T. Pregueiro, Aiding the Detection of Fake Accounts in Large Scale Social Online Services (2012)
基本概念
威胁模型与可信节点
SybilRank将OSN视为无向图,其中每个节点对应网络中的一个用户,每条边对应双边的社交关系。
在SybilRank的威胁模型(Threat Model)中,所有节点被划入两个不相交的集合:Non-Sybil(真实账号)集合H和 Sybil(虚假账号)集合S;集合H以及所有Non-Sybil节点间的边构成Non-Sybil区域GH,集合S以及所有Sybil节点间的边构成Sybil区域GS。GH和GS之间由攻击边(Attack Edges)相连。
指定若干认为是Non-Sybil的节点作为SybilRank运行的信任种子(Trust Seeds)。选择多个可信节点使得SybilRank对种子选择的错误具有鲁棒性,因为如果错误地将Sybil节点或接近Sybil的节点指定为种子,只会导致仅一小部分的可信度在Sybil区域中初始化和传播。
下面是一个带有信任种子的威胁模型示例:
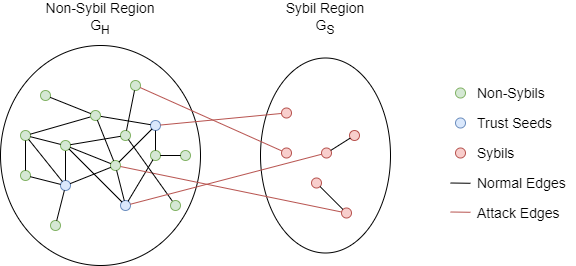
SybilRank的一个重要假设是攻击边数量有限。由于SybilRank是为大规模攻击而设计的,其中虚假帐户大都以低成本制作和维护,因此无法与许多真实用户建立社交联系。这导致GH和GS之间的稀疏切割。
提前终止的随机游走
在无向图中,如果随机游走以相同的概率访问每个邻居节点,当步数足够时,最后着陆到每个节点的概率会收敛到与其度数成正比。随机游走达到平稳分布所需的步数称为图的混合时间(Mixing Time)。
SybilRank依赖于这样的观察,即从非Sybil节点(信任种子)开始的提前终止的随机游走(Early-Terminated Random Walk)会以更高的概率着陆到非Sybil节点,因为游走不太可能经过相对较少的攻击边。也就是说,非Sybil区域GH和整个图的混合时间存在明显差异。
SybilRank将每个节点的着陆概率(Landing Probability)称为该节点的可信度(Trust)。SybilRank根据节点的可信度对节点进行排名,可信度分值越低的节点排名越高,是Sybil的可能性越大。
可信度传播:幂迭代
SybilRank使用幂迭代(Power Iteration)来更有效率地计算大图中随机游走的着陆概率。幂迭代涉及连续矩阵乘法,其中矩阵的每个元素表示从一个节点到邻居节点的随机游走转移概率。每次迭代相当于计算增加一步随机游走后所有节点的着陆概率分布。
在无向图G=(V, E)中,先将设置的总可信度TG均匀分配给所有的信任种子。在每次的幂迭代中,节点首先将自身的可信度均匀分配给所有邻居;然后,它收集所有邻居分发给自己的可信度,并相应地更新自身的可信度。节点v在第i次迭代中的可信度为:
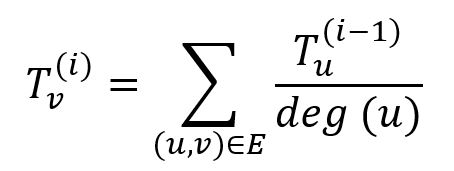
其中节点u属于节点v的邻居集合,deg(u)是节点u的度,全图的总可信度TG始终保持不变。
如果进行足够的幂迭代,所有节点的可信度将收敛到平稳分布:
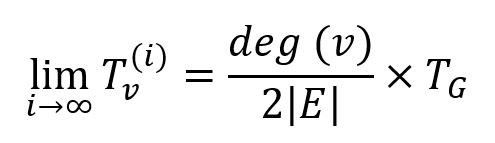
然而,SybilRank在收敛前就会提前终止迭代,建议的迭代次数为log(|V|)。此迭代次数足够混合Non-Sybil区域GH,使其达到近似平稳的可信度分布,但限制可信度传播到Sybil区域GS,因此Non-Sybil的排名将高于Sybil。
在实践中,GH的混合时间受多种因素影响,因此
log(|V|)只是一个参考,但它必须小于整个图的混合时间。
特殊说明
- 每条自环边会被视为节点的两条边。
- SybilRank算法忽略边的方向,按照无向边进行计算。
- SybilRank的计算复杂度是O(n log n),因为每次幂迭代的复杂度为O(n),它迭代O(log n) 次。计算复杂度与信任种子的数量无关。
示例图集
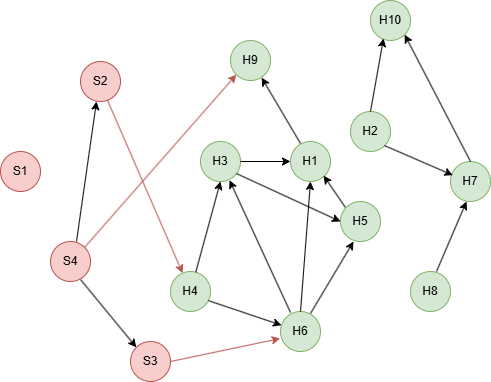
创建示例图集:
// 在空图集中逐行运行以下语句
create().node_schema("user").edge_schema("link")
insert().into(@user).nodes([{_id:"H1"}, {_id:"H2"}, {_id:"H3"}, {_id:"H4"}, {_id:"H5"}, {_id:"H6"}, {_id:"H7"}, {_id:"H8"}, {_id:"H9"}, {_id:"H10"}, {_id:"S1"}, {_id:"S2"}, {_id:"S3"}, {_id:"S4"}])
insert().into(@link).edges([{_from:"S2", _to:"H4"}, {_from:"S3", _to:"H6"}, {_from:"S4", _to:"S2"}, {_from:"S4", _to:"S3"}, {_from:"S4", _to:"H9"}, {_from:"H1", _to:"H9"}, {_from:"H2", _to:"H7"}, {_from:"H2", _to:"H10"}, {_from:"H3", _to:"H1"}, {_from:"H3", _to:"H5"}, {_from:"H4", _to:"H3"}, {_from:"H4", _to:"H6"}, {_from:"H5", _to:"H1"}, {_from:"H6", _to:"H1"}, {_from:"H6", _to:"H3"}, {_from:"H6", _to:"H5"}, {_from:"H7", _to:"H10"}, {_from:"H8", _to:"H7"}])
创建HDC图集
将当前图集全部加载到HDC服务器hdc-server-1上,并命名为 hdc_sybilrank:
CALL hdc.graph.create("hdc-server-1", "hdc_sybilrank", {
nodes: {"*": ["*"]},
edges: {"*": ["*"]},
direction: "undirected",
load_id: true,
update: "static",
query: "query",
default: false
})
hdc.graph.create("hdc_sybilrank", {
nodes: {"*": ["*"]},
edges: {"*": ["*"]},
direction: "undirected",
load_id: true,
update: "static",
query: "query",
default: true
}).to("hdc-server-1")
参数
算法名:sybil_rank
参数名 |
类型 |
规范 |
默认值 |
可选 |
描述 |
|---|---|---|---|---|---|
total_trust |
Float | >0 | / | 否 | 所有信任种子分配的可信度总分 |
trust_seeds |
[]_uuid |
/ | / | 是 | 通过_uuid指定信任种子,建议在各个社区均挑选信任种子。若未设置则指定所有点为信任种子 |
loop_num |
Integer | >0 | 5 |
是 | 最大迭代轮数。算法将在完成所有轮次后停止。建议设置为log2(|V|),其中|V|是总点数 |
return_id_uuid |
String | uuid, id, both |
uuid |
是 | 在结果中使用_uuid、_id或同时使用两者来表示点 |
limit |
Integer | ≥-1 | -1 |
是 | 限制返回的结果数;-1返回所有结果 |
文件回写
CALL algo.sybil_rank.write("hdc_sybilrank", {
params: {
return_id_uuid: "id",
total_trust: 100,
// 指定H2,H3和H5为信任种子
trust_seeds: [8214567919347040258, 16429133639670824963, 15060039352950194181],
loop_num: 4
},
return_params: {
file: {
filename: "sybil_rank"
}
}
})
algo(sybil_rank).params({
projection: "hdc_sybilrank",
return_id_uuid: "id",
total_trust: 100,
// 指定H2,H3和H5为信任种子
trust_seeds: [8214567919347040258, 16429133639670824963, 15060039352950194181],
loop_num: 4
}).write({
file: {
filename: "sybil_rank"
}
})
结果:
_id,sybil_rank
S1,0
S4,3.61111
S2,4.45602
S3,4.71065
H9,5.0434
H8,5.09259
H4,6.66667
H10,7.87037
H5,8.67766
H1,9.59491
H2,9.9537
H7,10.4167
H3,11.305
H6,12.6013
数据库回写
将结果中的sybil_rank值写入指定点属性。该属性类型为float。
CALL algo.sybil_rank.write("hdc_sybilrank", {
params: {
return_id_uuid: "id",
total_trust: 100,
// 指定H2,H3和H5为信任种子
trust_seeds: [8214567919347040258, 16429133639670824963, 15060039352950194181],
loop_num: 4
},
return_params: {
db: {
property: "trust"
}
}
})
algo(sybil_rank).params({
projection: "hdc_sybilrank",
return_id_uuid: "id",
total_trust: 100,
// 指定H2,H3和H5为信任种子
trust_seeds: [8214567919347040258, 16429133639670824963, 15060039352950194181],
loop_num: 4
}).write({
db:{
property: 'trust'
}
})
完整返回
CALL algo.sybil_rank("hdc_sybilrank", {
params: {
return_id_uuid: "id",
total_trust: 100,
// 指定H2,H3和H5为信任种子
trust_seeds: [8214567919347040258, 16429133639670824963, 15060039352950194181],
loop_num: 4
},
return_params: {}
}) YIELD trust
RETURN trust
exec{
algo(sybil_rank).params({
return_id_uuid: "id",
total_trust: 100,
// 指定H2,H3和H5为信任种子
trust_seeds: [8214567919347040258, 16429133639670824963, 15060039352950194181],
loop_num: 4
}) as trust
return trust
} on hdc_sybilrank
结果:
| _id | sybil_rank |
|---|---|
| S1 | 0 |
| S4 | 3.611111 |
| S2 | 4.456018 |
| S3 | 4.710648 |
| H9 | 5.043402 |
| H8 | 5.092593 |
| H4 | 6.666666 |
| H10 | 7.87037 |
| H5 | 8.677661 |
| H1 | 9.594906 |
| H2 | 9.953703 |
| H7 | 10.41667 |
| H3 | 11.30498 |
| H6 | 12.60127 |
流式返回
CALL algo.sybil_rank("hdc_sybilrank", {
params: {
return_id_uuid: "id",
total_trust: 100,
// 指定H2,H3和H5为信任种子
trust_seeds: [8214567919347040258, 16429133639670824963, 15060039352950194181],
loop_num: 4,
limit: 4
},
return_params: {
stream: {}
}
}) YIELD trust
RETURN trust
exec{
algo(sybil_rank).params({
return_id_uuid: "id",
total_trust: 100,
// 指定H2,H3和H5为信任种子
trust_seeds: [8214567919347040258, 16429133639670824963, 15060039352950194181],
loop_num: 4,
limit: 4
}).stream() as trust
return trust
} on hdc_sybilrank
结果:
| _id | sybil_rank |
|---|---|
| S1 | 0 |
| S4 | 3.611111 |
| S2 | 4.456018 |
| S3 | 4.710648 |