概述
使用语句ORDER BY可根据排序键对数据排序。若有多个排序键出现,则排序操作从左到右依次执行:首先根据第一个键排序;对于第一个键值相同的记录,再按第二个键排序,以此类推。
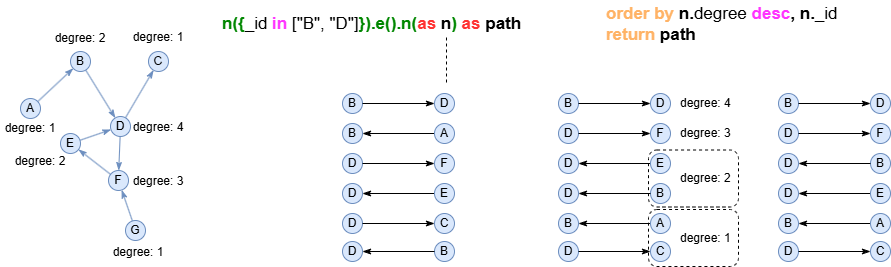
语法
ORDER BY <key1> <desc_asc?>, <key2?> <desc_asc?>, ...
详情
<key>:排序键,引用了之前语句中声明的别名。<desc_asc?>:排序规范,支持ASC(升序)或DESC(降序)。忽略时默认使用ASC。- 排序过程自动剔除
null值,其对应记录会列在排序结果的末尾。
示例图集
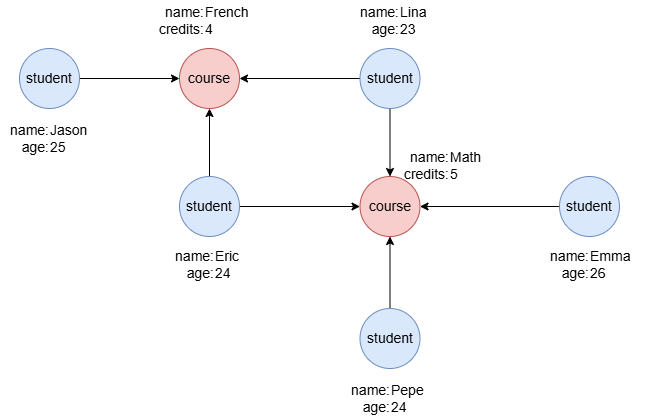
在一个空图集中,逐行运行以下语句,创建示例图集:
create().node_schema("student").node_schema("course").edge_schema("takes")
create().node_property(@*, "name").node_property(@student, "age", int32).node_property(@course, "credits", int32)
insert().into(@student).nodes([{_id:"S1", name:"Jason", age:25}, {_id:"S2", name:"Lina", age:23}, {_id:"S3", name:"Eric", age:24}, {_id:"S4", name:"Emma", age:26}, {_id:"S5", name:"Pepe", age:24}])
insert().into(@course).nodes([{_id:"C1", name:"French", credits:4}, {_id:"C2", name:"Math", credits:5}])
insert().into(@takes).edges([{_from:"S1", _to:"C1"}, {_from:"S2", _to:"C1"}, {_from:"S3", _to:"C1"}, {_from:"S2", _to:"C2"}, {_from:"S3", _to:"C2"}, {_from:"S4", _to:"C2"}, {_from:"S5", _to:"C2"}])
根据属性排序
find().nodes({@student}) as stu
order by stu.age desc
return table(stu.name, stu.age)
结果:
| stu.name | stu.age |
|---|---|
| Emma | 26 |
| Jason | 25 |
| Pepe | 24 |
| Eric | 24 |
| Lina | 23 |
根据点/边别名排序
指定点别名或边别名为分组键时,查询结果将根据点或边的_uuid排序。
find().nodes({@student}) as stu
order by stu
return table(stu.name, stu._uuid)
结果:
| stu.name | stu._uuid |
|---|---|
| Pepe | 5404321751867850754 |
| Jason | 5908724910133346305 |
| Eric | 9079259047802175489 |
| Emma | 15924730481405329410 |
| Lina | 16717364015822536705 |
根据表达式排序
n({name == "Jason"}).e()[:3].n() as p
order by length(p)
return p{*}
Jason -> French
Jason -> French <- Lina
Jason -> French <- Eric
Jason -> French <- Lina -> Math
Jason -> French <- Eric -> Math
多级排序
n({@course} as crs).e().n({@student} as stu) as p
order by crs.credits, stu.age desc
return table(crs.name, crs.credits, stu.name, stu.age)
结果:
| crs.name | crs.credits | stu.name | stu.age |
|---|---|---|---|
| French | 4 | Jason | 25 |
| French | 4 | Eric | 24 |
| French | 4 | Lina | 23 |
| Math | 5 | Emma | 26 |
| Math | 5 | Eric | 24 |
| Math | 5 | Pepe | 24 |
| Math | 5 | Lina | 23 |
分组和排序
统计每门课程的注册学生数,并根据统计结果排序:
n({@course} as crs).e().n({@student})
group by crs
with crs, count(crs) as stuCnt
order by stuCnt desc
return table(crs.name, stuCnt)
结果:
| crs.name | stuCnt |
|---|---|
| Math | 4 |
| French | 3 |