概述
使用语句upsert()可以(1)更新已有点边,或(2)向图集的一个schema插入新的点和边。
// 更新或插入点
upsert().into(@<schema>).nodes([
{<property1?>: <value1?>, <property2?>: <value2?>, ...},
{<property1?>: <value1?>, <property2?>: <value2?>, ...},
...
])
// 插入边
upsert().into(@<schema>).edges([
{<property1?>: <value1?>, <property2?>: <value2?>, ...},
{<property1?>: <value1?>, <property2?>: <value2?>, ...},
...
])
方法 |
参数 |
描述 |
|---|---|---|
into() |
<schema> |
指定点schema或边schema,如@user |
nodes()或edges() |
属性规范列表 | 向指定schema插入或更新一或多个点或边,其中每个属性规范需用{}包裹 |
更新
若属性规范列表提供了已有_id值,则会更新点数据。若指定了已有EDGE KEY约束以及相应的_from和_to,则会更新边数据。
更新点数据或边数据时:
- 提供的自定义属性值会替换当前值。
- 未提供的自定义属性值保持不变。
- 系统属性保持不变。
插入
当提供了新的_id值或_id值缺失时,会插入一个新的点。当没有如上所述更新边时,会插入一条新边,注意必须提供边属性_from和_to以指明起点和终点。
插入点或边时:
- 将给定值分配给提供的属性。
- 未提供的自定义属性,默认赋值为
null。 - 若未提供点的
_id,则由系统自动生成。点或边的_uuid始终由系统自动生成,不允许指定。
示例图集
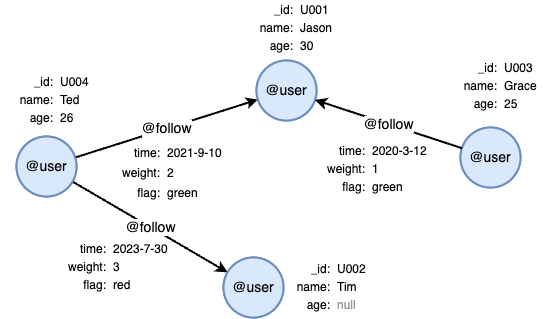
在一个空图集中,逐行运行以下UQL语句,创建示例图集:
create().node_schema("user").edge_schema("follow")
create().node_property(@user, "name").node_property(@user, "age", int32).edge_property(@follow, "time", datetime)
insert().into(@user).nodes([{_id:"U001", name:"Jason", age:30}, {_id:"U002", name:"Tim"}, {_id:"U003", name:"Grace", age:25}, {_id:"U004", name:"Ted", age:26}])
insert().into(@follow).edges([{_from:"U004", _to:"U001", time:"2021-9-10"}, {_from:"U003", _to:"U001", time:"2020-3-12"}, {_from:"U004", _to:"U002", time:"2023-7-30"}])
更新或插入点
更新@user中的点或向其中插入点:
upsert().into(@user).nodes([
{_id: "U001", name: "John"},
{_id: "U005", name: "Alice"},
{age: 12}
]) as n
return n{*}
- 第一个点:提供的
_id值U001在图集中已存在,因此更新对应点的数据。 - 第二个点:提供的
_id值U005为新值,因此插入新点。 - 第三个点:未提供
_id值,因此插入新点。
结果:n
_id |
_uuid |
schema |
values |
|---|---|---|---|
| U001 | Sys-gen | user | {name: "John", age: 30} |
| U005 | Sys-gen | user | {name: "Alice", age: null} |
| Sys-gen | Sys-gen | user | {name: null, age: 12} |
更新或插入边
没有EDGE KEY约束
如果没有定义EDGE KEY约束,则查询会报错:
upsert().into(@follow).edges([
{_from: "U004", _to: "U001", time: "2021-9-10"},
{_from: "U001", _to: "U004", time: "2021-10-3", weight: 2}
])
单属性EDGE KEY约束
为边属性time创建单属性EDGE KEY约束:
CREATE CONSTRAINT key_time
FOR ()-[e]-() REQUIRE e.time IS EDGE KEY
OPTIONS {
type: {time: "datetime"}
}
向@follow插入更新边:
upsert().into(@follow).edges([
{_from: "U004", _to: "U001", time: "2021-9-10"},
{_from: "U001", _to: "U004", time: "2021-10-3", weight: 2}
]) as e
return e{*}
- 第一条边:提供的EDGE KEY约束(
time)和对应值2021-9-10在图集中存在,_from和_to均匹配,因此更新对应边数据。 - 第二条边:提供的EDGE KEY约束(
time)和对应值2021-10-3为新值,因此插入新边。
结果:e
_uuid |
_from |
_to |
_from_uuid |
_to_uuid |
schema |
values |
|---|---|---|---|---|---|---|
| Sys-gen | U004 | U001 | UUID of U004 | UUID of U001 | follow | {time: "2021-09-10 00:00:00", weight: 2, flag: "green"} |
| Sys-gen | U001 | U002 | UUID of U001 | UUID of U002 | follow | {time: "2021-10-03 00:00:00", weight: 2, flag: null} |
复合EDGE KEY约束
为边属性time和weight创建复合EDGE KEY约束:
CREATE CONSTRAINT key_time_weight
FOR ()-[e]-() REQUIRE (e.time, e.weight) IS EDGE KEY
OPTIONS {
type: {time: "datetime", weight: "int32"}
}
向@follow插入更新边:
upsert().into(@follow).edges([
{_from: "U004", _to: "U001", time: "2021-9-10", weight: 2},
{_from: "U003", _to: "U001", time: "2020-3-12", weight: 2},
{_from: "U001", _to: "U004", time: "2021-10-3", weight: 1, flag: "green"}
]) as e
return e{*}
- 第一条边:提供的EDGE KEY约束(
time,weight)和对应值(2021-9-10,2)在图集中已存在,_from和_to均匹配,因此更新对应边数据。 - 第二条边:提供的EDGE KEY约束(
time,weight)和对应值(2020-3-12,2)为新值,因此插入新边。 - 第三条边:提供的EDGE KEY约束(
time,weight)和对应值(2021-10-3,1)为新值,因此插入新边。
结果:e
_uuid |
_from |
_to |
_from_uuid |
_to_uuid |
schema |
values |
|---|---|---|---|---|---|---|
| Sys-gen | U004 | U001 | UUID of U004 | UUID of U001 | follow | {time: "2021-09-10 00:00:00", weight: 2, flag: "green"} |
| Sys-gen | U003 | U001 | UUID of U003 | UUID of U001 | follow | {time: "2020-03-12 00:00:00", weight: 2, flag: null} |
| Sys-gen | U001 | U004 | UUID of U001 | UUID of U004 | follow | {time: "2021-10-03 00:00:00", weight: 1, flag: "green"} |