概述
使用语句UNCOLLECT可以将列表中的元素展开成独立记录。
语法
UNCOLLECT <listExp> as <alias>
详情
- 表达式
<listExp>用来代表或生成list类型数据。 - 必须使用
<alias>来代表展开的数据。
示例图集
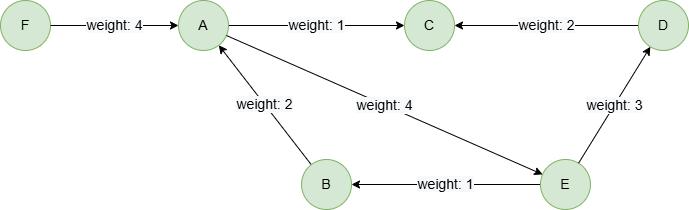
在一个空图集中,逐行运行以下语句,创建示例图集:
create().edge_property(@default, "weight", int32)
insert().into(@default).nodes([{_id:"A"}, {_id:"B"}, {_id:"C"}, {_id:"D"}, {_id:"E"}, {_id:"F"}])
insert().into(@default).edges([{_from:"A", _to:"C", weight:1}, {_from:"E", _to:"B", weight:1}, {_from:"A", _to:"E", weight:4}, {_from:"D", _to:"C", weight:2}, {_from:"E", _to:"D", weight:3}, {_from:"B", _to:"A", weight:2}, {_from:"F", _to:"A", weight:4}])
展开列表
uncollect [1,1,2,3,null] as item
return item
结果:
| item |
|---|
| 1 |
| 1 |
| 2 |
| 3 |
null |
uncollect [[1,2], [2,3,5]] as item
return item
结果:
| item |
|---|
| [1,2] |
| [2,3,5] |
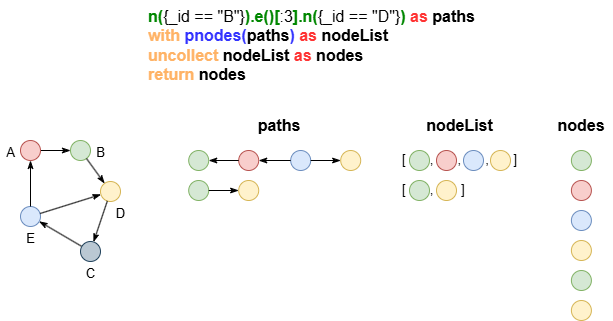
展开点/边列表
函数pnodes()和pedges()能分别将路径中的点或边收集到一个列表中。
n({_id == "A"}).e()[2].n({_id == "D"}) as p
call {
with p
uncollect pedges(p) as edges
return sum(edges.weight) as totalWeights
}
return totalWeights
结果:
| totalWeights |
|---|
| 3 |
| 7 |