概述
使用语句UNION ALL可以将两个或多个查询的结果合并成一个结果集,其中包含任一查询的结果。

如需对结果去重,可使用语句UNION。
语法
...
return <item1> as <alias1?>, <item2?> as <alias2?>, ...
union all
...
return <item1> as <alias1?>, <item2?> as <alias2?>, ...
详情
- 使用
UNION ALL合并结果时,所有查询的返回项必须相同。
示例图集
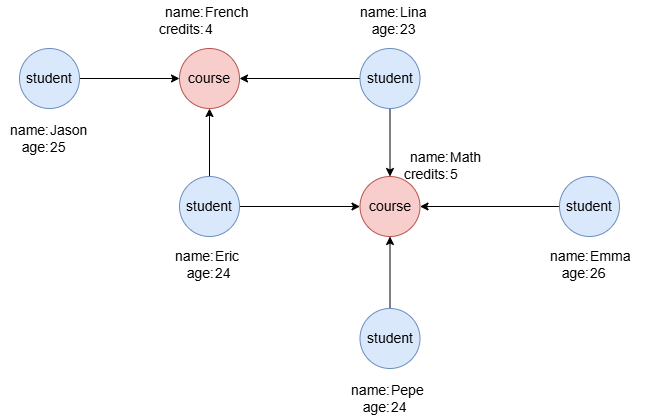
在一个空图集中,逐行运行以下语句,创建示例图集:
create().node_schema("student").node_schema("course").edge_schema("takes")
create().node_property(@*, "name").node_property(@student, "age", int32).node_property(@course, "credits", int32)
insert().into(@student).nodes([{_id:"S1", name:"Jason", age:25}, {_id:"S2", name:"Lina", age:23}, {_id:"S3", name:"Eric", age:24}, {_id:"S4", name:"Emma", age:26}, {_id:"S5", name:"Pepe", age:24}])
insert().into(@course).nodes([{_id:"C1", name:"French", credits:4}, {_id:"C2", name:"Math", credits:5}])
insert().into(@takes).edges([{_from:"S1", _to:"C1"}, {_from:"S2", _to:"C1"}, {_from:"S3", _to:"C1"}, {_from:"S2", _to:"C2"}, {_from:"S3", _to:"C2"}, {_from:"S4", _to:"C2"}, {_from:"S5", _to:"C2"}])
合并查询
n({@course.name == "French"}).e().n({@student} as s) return s.name
union all
n({@course.name == "Math"}).e().n({@student} as s) return s.name
结果:
| s.name |
|---|
| Lina |
| Eric |
| Jason |
| Lina |
| Emma |
| Eric |
| Pepe |
n({@course.name == "French"} as c).e().n({@student} as s) return c.name, s.age
union all
n({@course.name == "Math"} as c).e().n({@student} as s) return c.name, s.age
结果:
| c.name | s.age |
|---|---|
| French | 23 |
| French | 24 |
| French | 25 |
| Math | 23 |
| Math | 26 |
| Math | 24 |
| Math | 24 |