HDC
概述
全图K邻算法能识别图中每个节点的邻域。该算法广泛应用于关系发现、影响力预测、好友推荐等场景中。
全图K邻算法可以看作是K邻查询UQL命令的批量执行。
特殊说明
尽管全图K邻算法针对高并发性能进行了优化,但需要注意,在处理大型图(具有数千万个节点或边的图)或包含许多超级节点的图时,此算法仍会消耗大量计算资源。为了优化性能,要充分考虑图的特定特征和大小,建议避免执行过深的全图K邻计算。
在图G=(V, E)中,如果|E|/|V|=100,理论上查询一个节点的5跳邻居需要105(相当于100亿次计算)的计算复杂度,大约需要100毫秒。由此推断,在具有1千万节点的图中完成此类查询将需要100万秒(相当于约12天)。在处理这种规模的图形时,考虑计算需求和时间要求非常重要。
示例图
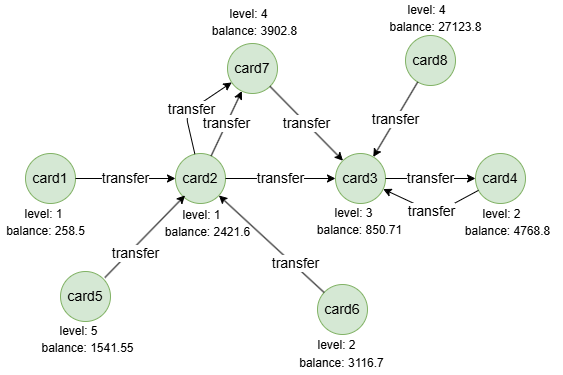
在一个空图中运行以下语句定义图结构并插入数据:
ALTER GRAPH CURRENT_GRAPH ADD NODE {
card ({level int32, balance double})
};
ALTER GRAPH CURRENT_GRAPH ADD EDGE {
transfer ()-[]->()
};
INSERT (card1:card {_id: "card1", level: 1, balance: 258.5}),
(card2:card {_id: "card2", level: 1, balance: 2421.6}),
(card3:card {_id: "card3", level: 3, balance: 850.71}),
(card4:card {_id: "card4", level: 2, balance: 4768.8}),
(card5:card {_id: "card5", level: 5, balance: 1541.55}),
(card6:card {_id: "card6", level: 2, balance: 3116.7}),
(card7:card {_id: "card7", level: 4, balance: 3902.8}),
(card8:card {_id: "card8", level: 4, balance: 27123.8}),
(card1)-[:transfer]->(card2),
(card2)-[:transfer]->(card3),
(card2)-[:transfer]->(card7),
(card2)-[:transfer]->(card7),
(card3)-[:transfer]->(card4),
(card4)-[:transfer]->(card3),
(card5)-[:transfer]->(card2),
(card6)-[:transfer]->(card2),
(card7)-[:transfer]->(card3),
(card8)-[:transfer]->(card3);
create().node_schema("card").edge_schema("transfer");
create().node_property(@card, "level", int32).node_property(@card, "balance", double);
insert().into(@card).nodes([{_id:"card1", level:1, balance:258.5}, {_id:"card2", level:1, balance:2421.6}, {_id:"card3", level:3, balance:850.71}, {_id:"card4", level:2, balance:4768.8}, {_id:"card5", level:5, balance:1541.55}, {_id:"card6", level:2, balance:3116.7}, {_id:"card7", level:4, balance:3902.8}, {_id:"card8", level:4, balance:27123.8}]);
insert().into(@transfer).edges([{_from:"card1", _to:"card2"}, {_from:"card2", _to:"card3"}, {_from:"card2", _to:"card7"}, {_from:"card2", _to:"card7"}, {_from:"card3", _to:"card4"}, {_from:"card4", _to:"card3"}, {_from:"card5", _to:"card2"}, {_from:"card6", _to:"card2"}, {_from:"card7", _to:"card3"}, {_from:"card8", _to:"card3"}]);
创建HDC图
将当前图集全部加载到HDC服务器hdc-server-1上,并命名为 my_hdc_graph:
CREATE HDC GRAPH my_hdc_graph ON "hdc-server-1" OPTIONS {
nodes: {"*": ["*"]},
edges: {"*": ["*"]},
direction: "undirected",
load_id: true,
update: "static"
}
hdc.graph.create("my_hdc_graph", {
nodes: {"*": ["*"]},
edges: {"*": ["*"]},
direction: "undirected",
load_id: true,
update: "static"
}).to("hdc-server-1")
参数
算法名:khop_all
参数名 |
类型 |
规范 |
默认值 |
可选 |
描述 |
|---|---|---|---|---|---|
ids |
[]_id |
/ | / | 是 | 通过_id指定参与计算的第一组点;若未设置则计算所有点 |
uuids |
[]_uuid |
/ | / | 是 | 通过_uuid指定参与计算的第一组点;若未设置则计算所有点 |
k_start |
Integer | ≥1 | 1 |
是 | K邻查询的起始深度,查询深度范围为[k_start, k_end] |
k_end |
Integer | ≥1 | 1 |
是 | K邻查询的终止深度,查询深度范围为[k_start, k_end] |
direction |
String | in, out |
/ | 是 | 最短路径中所有边的方向 |
node_property |
[]"<@schema.?><property>" |
/ | / | 是 | 进行聚合计算的数值类型点属性。 该选项必须与aggregate_opt配合使用 |
aggregate_opt |
[]String | max, min, mean, sum, var, dev |
/ | 是 | 对给定点属性值进行聚合计算的类型。该选项必须与node_property配合使用,其中每个聚合类型对应一种属性。聚合类型包括:
|
src_include |
Integer | 0, 1 |
0 |
是 | 是否在结果中包含目标节点;1表示包含,0表示不包含 |
return_id_uuid |
String | uuid, id, both |
uuid |
是 | 在结果中使用_uuid、_id或同时使用两者来表示 |
limit |
Integer | ≥-1 | -1 |
是 | 限制返回的结果数;-1返回所有结果 |
文件回写
该算法可生成两个文件:
配置项 |
内容 |
|---|---|
filename_ids |
|
filename |
|
CALL algo.khop_all.write("my_hdc_graph", {
return_id_uuid: "id",
ids: ["card1", "card7"],
k_start: 2,
k_end: 3,
direction: "out",
node_property: ["@card.level", "@card.balance"],
aggregate_opt: ["sum", "mean"]
}, {
file: {
filename_ids: "neighbors",
filename: "aggregations"
}
})
algo(khop_all).params({
projection: "my_hdc_graph",
return_id_uuid: "id",
ids: ["card1", "card7"],
k_start: 2,
k_end: 3,
direction: "out",
node_property: ["@card.level", "@card.balance"],
aggregate_opt: ["sum", "mean"]
}).write({
file: {
filename_ids: "neighbors",
filename: "aggregations"
}
})
结果:
_id,_id
card1,card3
card1,card7
card1,card4
card7,card4
_id,sum,mean,count
card1,9,3174.1,3
card7,2,4768.8,1
数据库回写
将聚合结果(如果有)和结果中的count值写入指定点属性。所有属性类型为double。
CALL algo.khop_all.write("my_hdc_graph", {
k_start: 2,
k_end: 2,
node_property: ["@card.level", "@card.level", "@card.balance"],
aggregate_opt: ["sum", "mean", "mean"]
}, {
db: {
property: "khop2"
}
})
algo(khop_all).params({
projection: "my_hdc_graph",
k_start: 2,
k_end: 2,
node_property: ["@card.level", "@card.level", "@card.balance"],
aggregate_opt: ["sum", "mean", "mean"]
}).write({
db: {
property: "khop2"
}
})
各聚合结果被写入新属性sum、mean和mean1,count值被写入新属性khop2。
完整返回
CALL algo.khop_all.run("my_hdc_graph", {
return_id_uuid: "id",
ids: ["card1", "card7"],
k_start: 2,
k_end: 3,
node_property: ["@card.level", "@card.balance"],
aggregate_opt: ["max", "mean"]
}) YIELD r
RETURN r
exec{
algo(khop_all).params({
return_id_uuid: "id",
ids: ["card1", "card7"],
k_start: 2,
k_end: 3,
node_property: ["@card.level", "@card.balance"],
aggregate_opt: ["max", "mean"]
}) as r
return r
} on my_hdc_graph
结果:
| _id | max | mean | count |
|---|---|---|---|
| card1 | 5 | 6884.06 | 6 |
| card7 | 5 | 7361.87 | 5 |
流式返回
CALL algo.khop_all.stream("my_hdc_graph", {
return_id_uuid: "id",
ids: "card2",
k_start: 2,
k_end: 2,
node_property: ["@card.level", "@card.balance"],
aggregate_opt: ["max", "max"]
}) YIELD results
RETURN results
exec{
algo(khop_all).params({
return_id_uuid: "id",
ids: "card2",
k_start: 2,
k_end: 2,
node_property: ["@card.level", "@card.balance"],
aggregate_opt: ["max", "max"]
}).stream() as results
return results
} on my_hdc_graph
结果:
| _id | max | max1 | count |
|---|---|---|---|
| card2 | 4 | 27123.8 | 2 |