先来看一个简单的对比:在一张百万量级点边的图上面,用Python NetworkX来完成鲁汶社区识别需要10个小时;类似的,华为的图计算系统需要近3个小时;而通过嬴图则在1秒钟内以纯实时的方式完成。这种性能差异达到数以万倍计的原因就在于是否实现了高并发、高密度并发原生图计算。
让我们看一个具体的例子——K邻搜索。
K邻(K-Hop)操作通常是通过BFS(广度优先搜索)的方式实现的。BFS相对于DFS(深度优先搜索)或其它图算法(鲁汶社区识别等)而言是比较容易实现并发计算的,在图中实现BFS算法并发的过程如下:
K邻并发算法
K邻并发算法步骤如下:
- 在图中定位起始顶点(上图中心的绿色顶点),计算其直接关联的、去重后的邻居数量。如果K=1,直接返回邻居去重后数量;否则,执行下一步。
- K>=2, 确定参与并发计算的资源量,并根据第一步中返回的邻居数量决定每个并发线程(任务)所需处理的任务量大小,进入第三步。
- 每个任务进一步以分而治之的方式,计算当前(被分配的)顶点的邻居数量,直到满足深度为K或者无新的邻居顶点可以被返回而退出,结束。
以大家所熟知的Twitter-2010数据集中,因为4200万的顶点与14.7亿条边的集合中存在大量超级节点(一般认为1度邻居在10000以上的顶点为超级节点或热点,而Twitter数据集中有很多顶点的1度邻居超过1000000个),因此是否能够实现以并发的方式递归查询至关重要——高并发的嬴图系统可以在6-hop查询中≤2秒钟完成计算,而Tigergraph则需要≥60秒,而其它系统,包含Neo4j、Nebula Graph、HugeGraph、ArangoDB等则完全无法返回。
在基准测试中,我们以Twitter数据集为基础,对标了多家图数据库系统的性能,结果简报如下:
- 数据加载:除了TigerGraph与嬴图性能接近,其它系统要慢2-15倍
- K邻查询:嬴图比所有其它系统快至少10倍以上。事实上,超过6跳的深度查询,只有嬴图可以返回结果
- 图算法:嬴图比任何其它图数据库系统快10倍以上。很多系统根本无法完成算法执行
各家图数据库的图计算性能对比图(以下4张图):
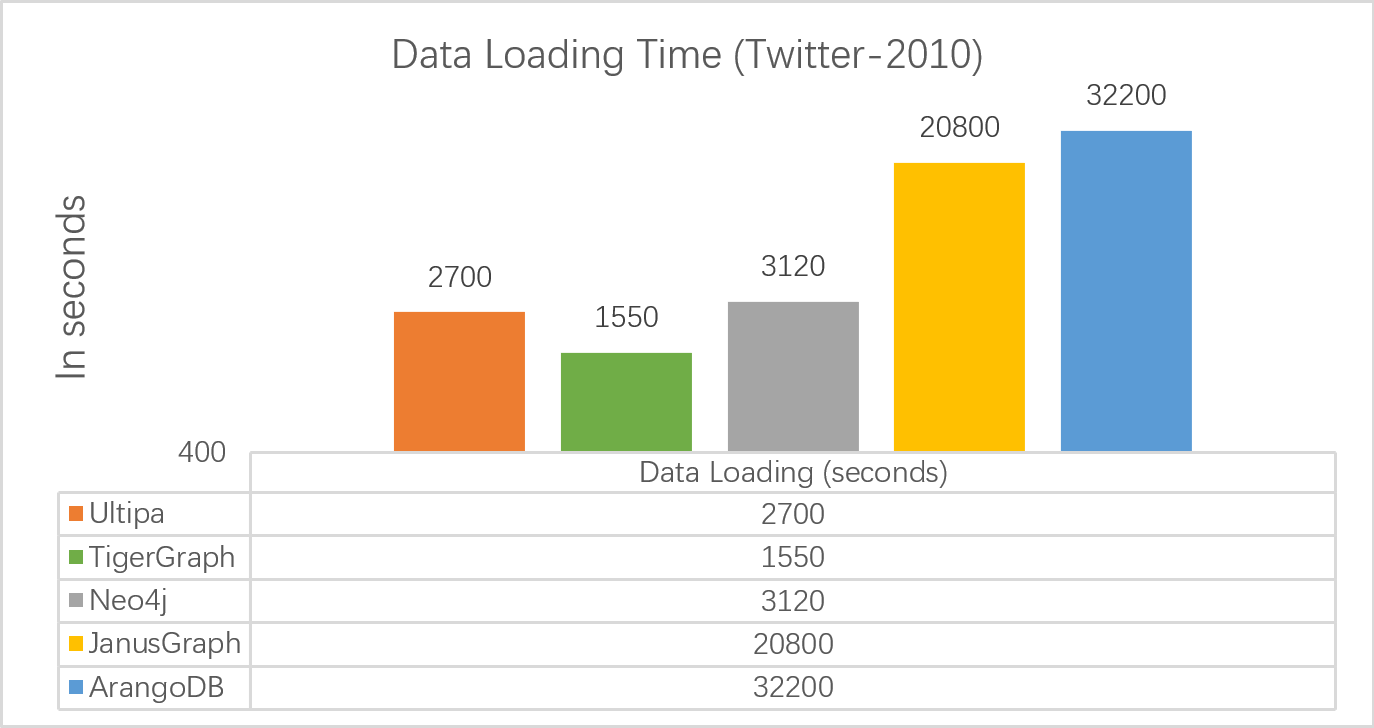
数据加载性能比较
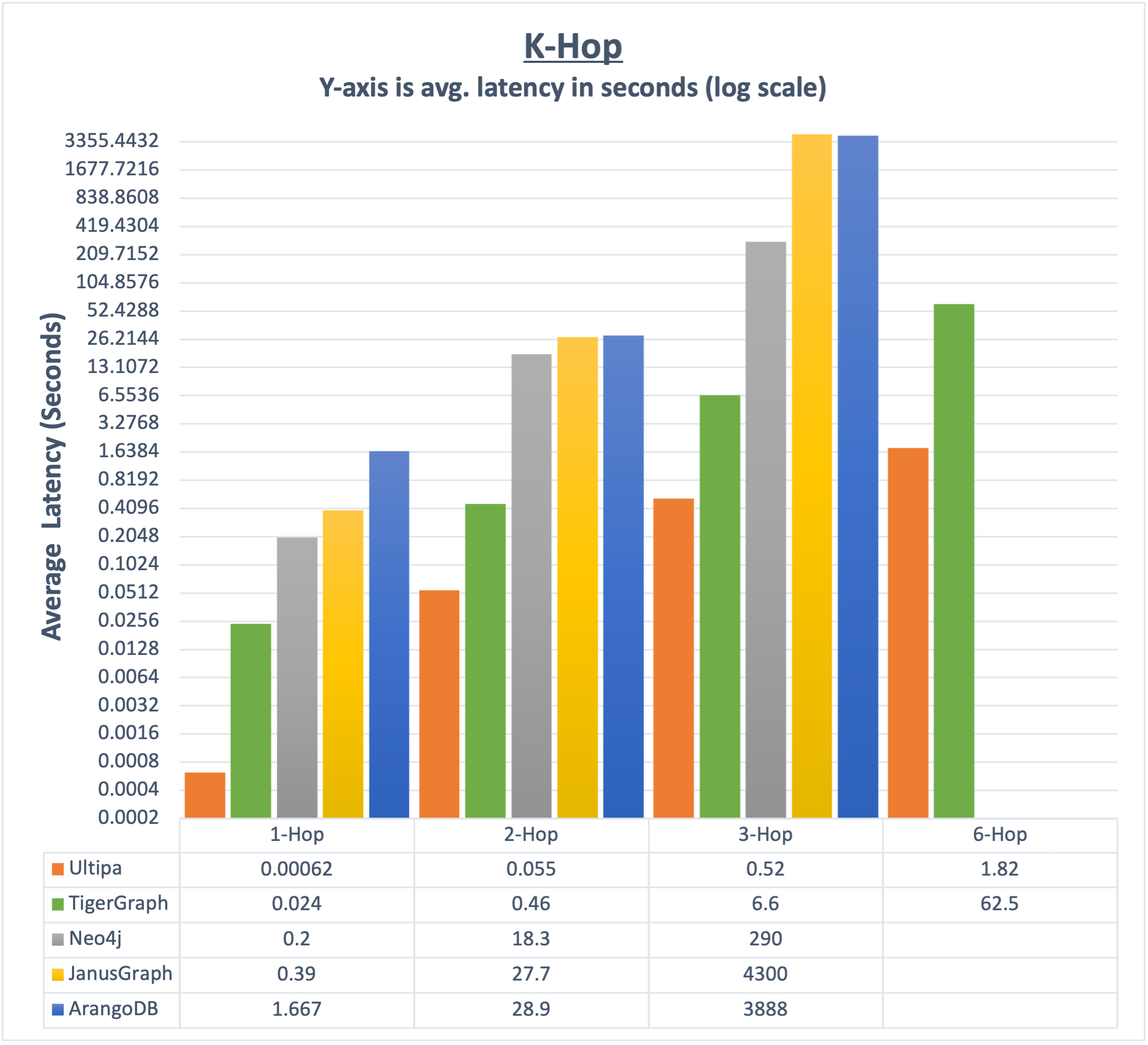
K度邻居查询(深度图遍历
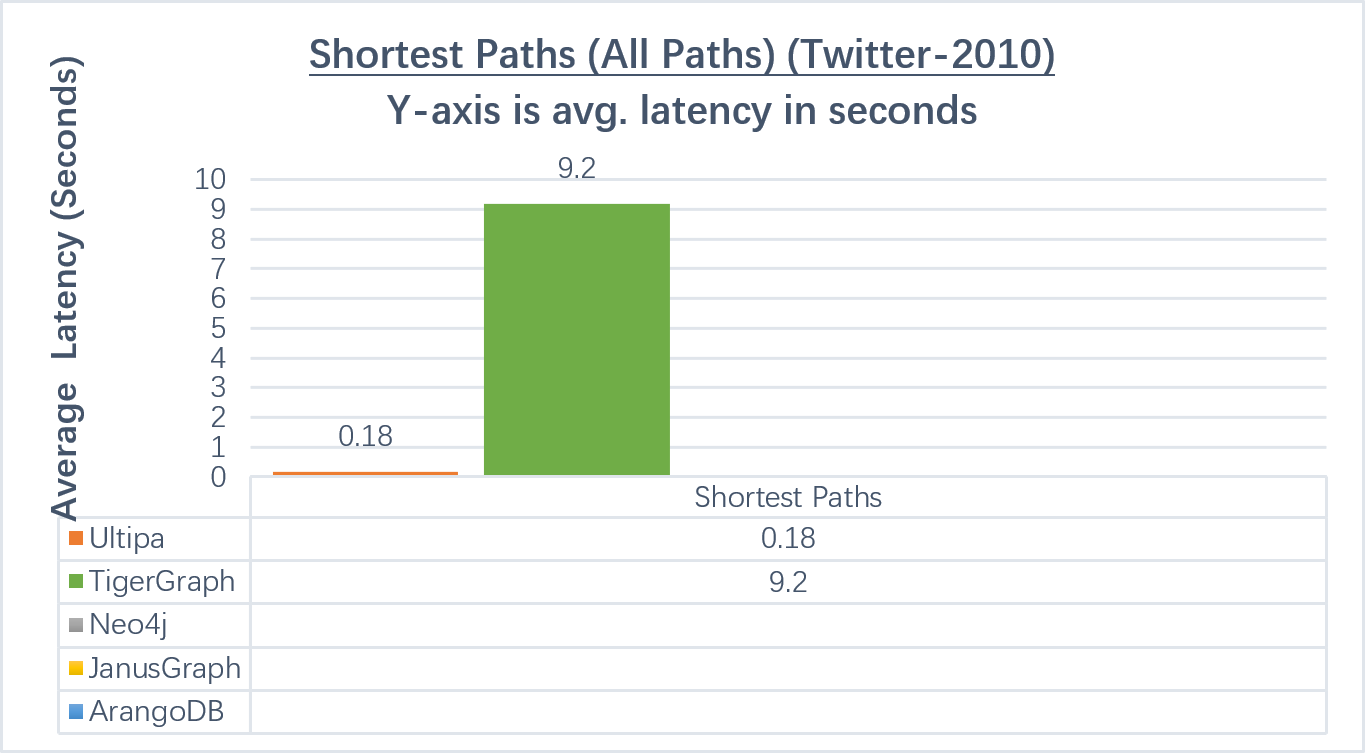
路径查询(全部最短路径)
.png)
图算法运行效率
以上评测指标可以清晰的表明嬴图系统较其它系统存在明显的、指数级的性能优势。在很多情况下这种优势会让原来T+1的批处理操作变为实时化,让原来不可能的工作方式成为可能,进而赋能业务与科技部门加速完成数字化转型。