由于图数据库天然是高维的,图上的操作天然是递归式的,我们会理所当然的认为图数据库的GQL也应该是天然善于查找关联关系(例如广度优先或深度优先等路径搜索)的。而事实上这一目标能否达成取决于很多因素。先对比一下几个基于不同图数据模式的GQL:
-
Neo4j的Cypher语言:标签(label)和属性(property)可以在使用中随时定义。但由于标签只是一个特殊的索引,和属性之间没有对应关系,所以这样的设计虽然灵活但却性能不高,存储空间利用率较低,不适合处理大规模计算。
-
TigerGraph的GSQL语言:模式(schema)作为真正意义上的“类别”可以拥有各自的属性。但该设计要求模式及其所对应的属性必须事先进行定义。此外,TigerGraph的GSQL的学习成本有目共睹的高。
-
UQL语言:半模式(demi-schema)既可以事先定义模式以便于进行大规模处理以及查询过滤时的精确定位,又允许在使用时不指定模式从而进行计算。
下图描述了一条含义为“名叫Areith的厨师”的点边点路径,以及分别为实现了该路径查询的Cypher、Gremlin、UQL、GSQL的具体语句实现。这些语句在书写及阅读上的效率间接反应出了它们背后的图数据库查询效率:
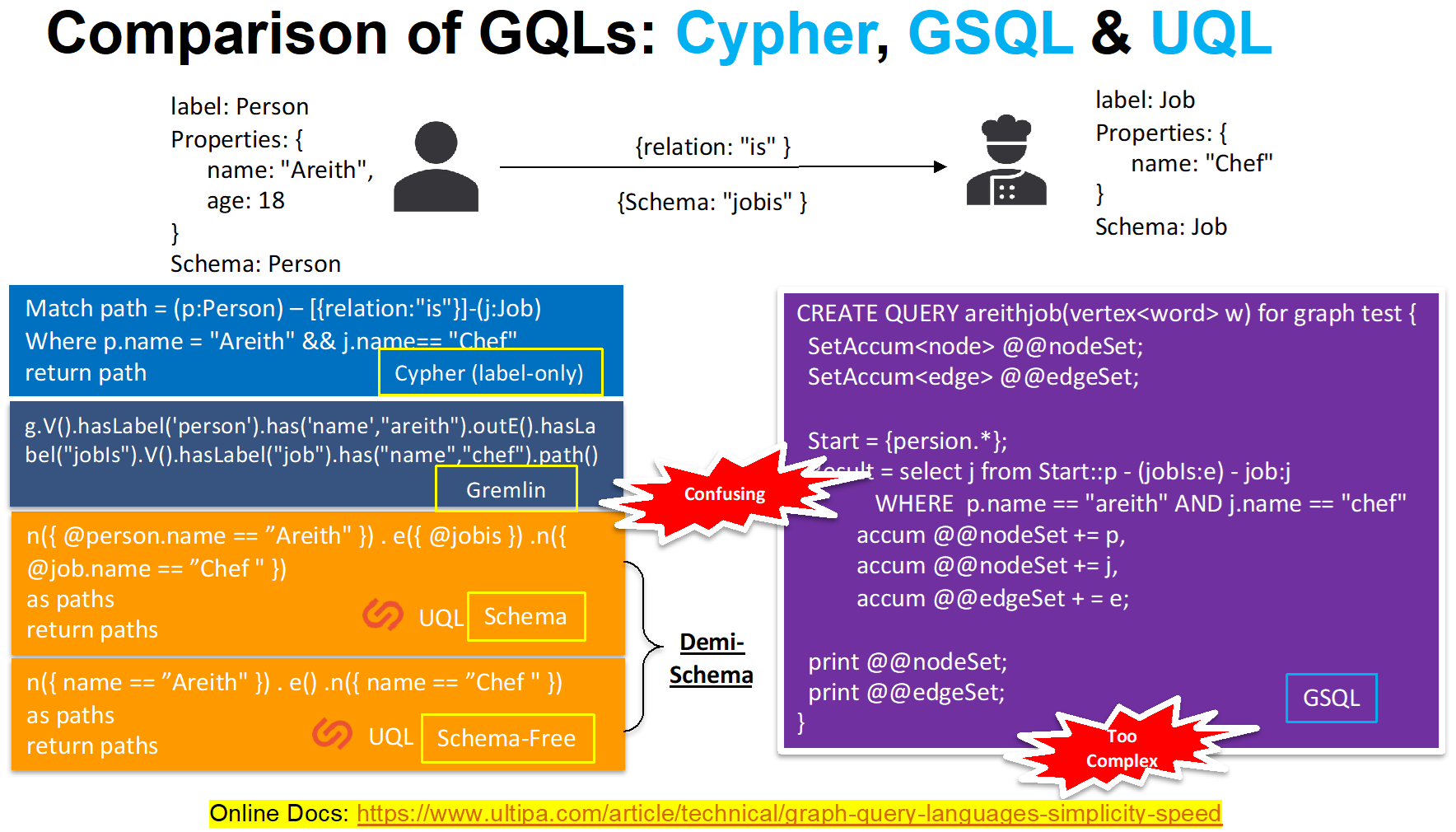
多种图查询语言的对比
让我们从Schema和Schema-free两方面来认识UQL所采用的Demi-schema的好处:
Schema特征:
- 拥有Schema图特性:继承全部Schema图的使用特性
- 数据类型可明确定义:针对不同业务情况创建不同类型点边,并为这些点边设计不同的属性组合,让管理和开发更加轻松
- 更高效的序列化和反序列化:明确的Schema和字段类型定义将大幅提升数据从序列化存储的磁盘转换成对应语言的数据结构的效率,反之亦然
- Schema图建模更加清晰:Manager提供了基于Schema的图模型预览和编排能力,可以将已有Schema用图的方式展现,并设计和调整
- 提升过滤与计算效率:与提升序列化效率相同,确定的数据类型可以保证并提升磁盘索引过滤、计算引擎运行的效率
- 全算法支持:所有算法都支持了对全图不同Schema下的处理操作,包括参数、运行机制、回写与结果返回机制
Schema-free特征:
- 具备Schema Free图特性:由于Schema图的设计会增加使用上的成本,Demi-Schema融合继承了Schema Free图使用方面的主要特性,并进行了优化
- 跨Schema批量字段操作:支持对全部Schema进行字段的批量创建、删除等操作,既可以按照Schema定义字段,也可以忽略Schema对全部的点、边进行修改
- 图过滤Schema缺省操作:在日常的查询当中,即可以使用携带Schema的表达式,也可以使用不携带Schema的表达式
- 支持隐式转换:支持了Schema free图特点的隐式类型转换机制,可以对schema不同的相同字段名称进行统一调用
- 多Schema可视化支持:在日常的数据返回与操作当中,一次查询可能会返回多种Schema数据,为了更好的帮助开发与业务人员使用,对各类返回结果都进行了支持与优化
- 全算法支持:针对图算法,可以按照以往Schema free的方式进行参数使用、运行、回写和结果返回
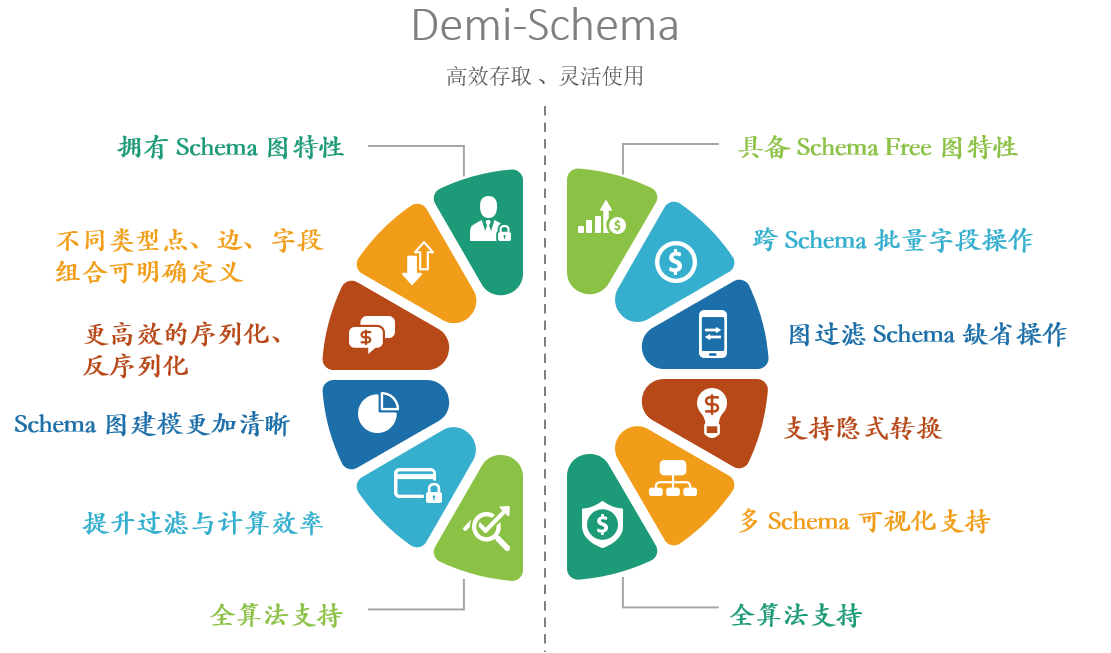
Demi-schema的优势