概述
带量词路径是变长路径,其中路径整体或部分重复多次出现。带量词路径在以下情况非常有用:
- 点之间的确切步数未知
- 捕捉不同深度的关系
- 通过“压缩”重复的模式来简化查询语句
量词
量词作为后缀写在边模式或带括号路径模式之后,用于指定该模式重复的次数。
量词 |
描述 |
|---|---|
{m,n} |
重复m到n次 |
{m} |
重复m次 |
{m,} |
重复至少m次 |
{,n} |
重复0到n次 |
* |
重复至少0次 |
+ |
重复至少1次 |
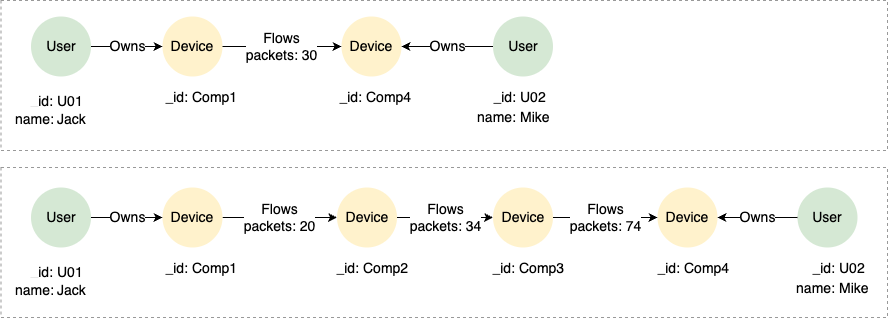
示例图
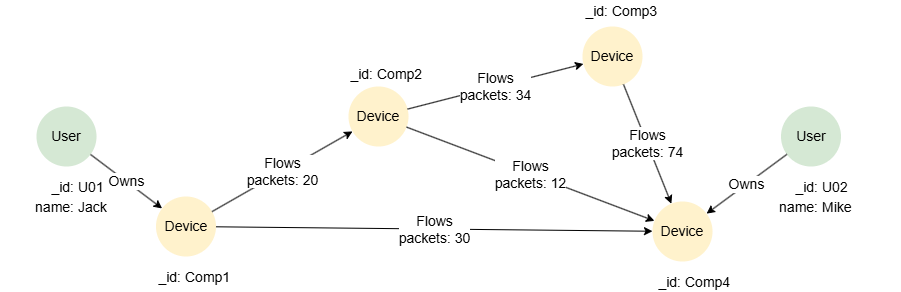
CREATE GRAPH myGraph {
NODE User ({name string}),
NODE Device (),
EDGE Owns ()-[{}]->(),
EDGE Flows ()-[{packets int32}]->()
} PARTITION BY HASH(Crc32) SHARDS [1]
INSERT (jack:User {_id: "U01", name: "Jack"}),
(mike:User {_id: "U02", name: "Mike"}),
(c1:Device {_id: "Comp1"}),
(c2:Device {_id: "Comp2"}),
(c3:Device {_id: "Comp3"}),
(c4:Device {_id: "Comp4"}),
(jack)-[:Owns]->(c1),
(mike)-[:Owns]->(c4),
(c1)-[:Flows {packets: 20}]->(c2),
(c1)-[:Flows {packets: 30}]->(c4),
(c2)-[:Flows {packets: 34}]->(c3),
(c2)-[:Flows {packets: 12}]->(c4),
(c3)-[:Flows {packets: 74}]->(c4)
构建带量词路径
当将一个带量词路径展开为完整形式时:
- 两个连续出现的点模式会合并成一个点模式,它们的过滤条件通过
AND逻辑组合; - 两个连续出现的边模式会通过一个隐式的空点模式连接。
边模式带量词
边模式可以直接跟随一个量词,完整边模式和简写边模式均支持这种写法。
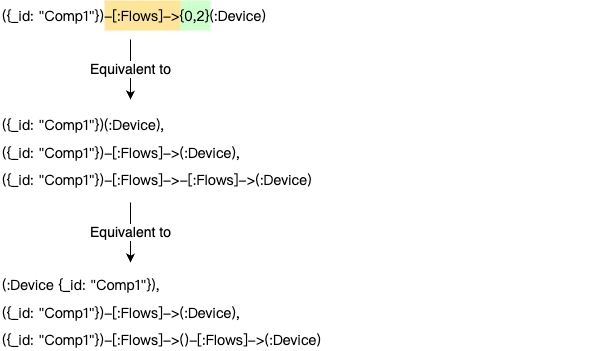
完整路径带量词
可以将整个路径模式用括号()包裹,并在其后添加一个量词。

当量词应用于整个路径时,步数为0时不会产生任何结果。
部分路径带量词
可以将部分路径模式用括号()包裹,并在其后添加一个量词。
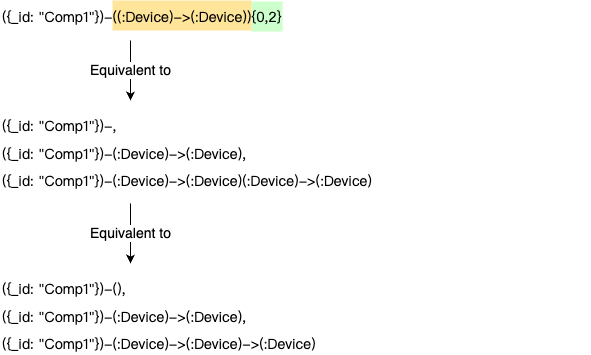
另一个例子:

示例
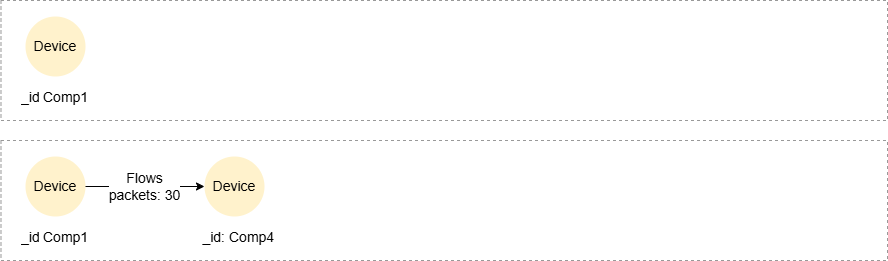
固定下界和上界
MATCH p = ({name: 'Jack'})->()-[f:Flows WHERE f.packets > 15]->{1,3}()<-({name: 'Mike'})
RETURN p
结果:p
固定长度
MATCH p = ((:Device)->(:Device)){2}
RETURN p
结果:p
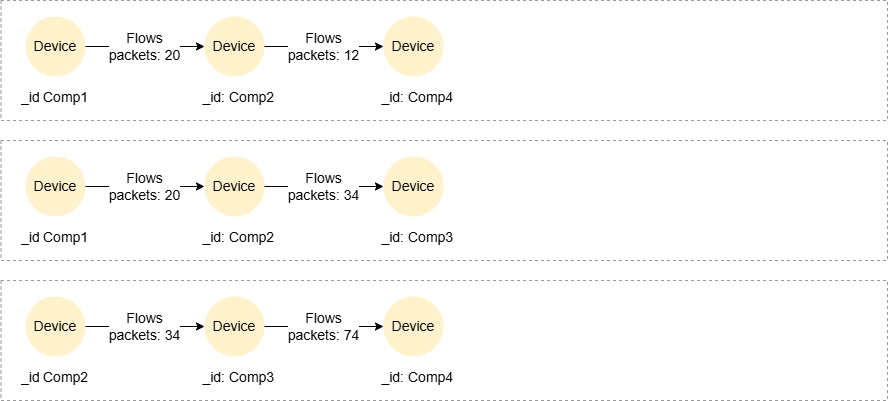
固定下界
MATCH ({_id: 'Comp1'})->{2,}(n)
RETURN COLLECT_LIST(n._id)
结果:
| COLLECT_LIST(n._id) |
|---|
| ["Comp4","Comp3","Comp4"] |
MATCH p = ({_id: 'Comp1'})-[f:Flows WHERE f.packets > 20]->*()
RETURN p
结果:p
MATCH p = ({_id: 'Comp1'})-[f:Flows WHERE f.packets > 20]->+()
RETURN p
结果:p

固定上界
MATCH p = ({name: 'Jack'})->(()-[f:Flows WHERE f.packets > 15]->()){,2}<-({name: 'Mike'})
RETURN p
结果:p

组变量
在带量词路径的重复部分中声明的元素变量会绑定到一组点或边,这些变量被称为组变量(Group Variables)或组列表(Group List)。
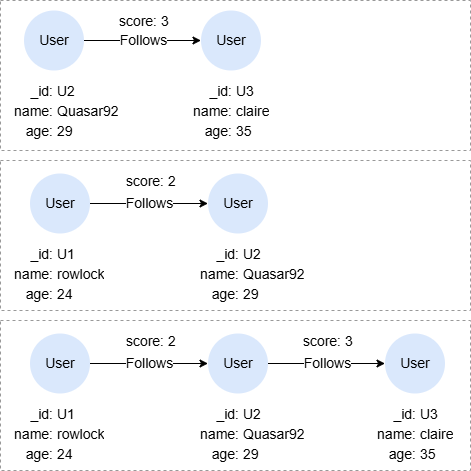
示例图
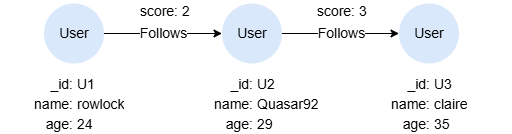
CREATE GRAPH myGraph {
NODE User ({name string, age uint32}),
EDGE Follows ()-[{score uint32}]->()
} PARTITION BY HASH(Crc32) SHARDS [1]
INSERT (rowlock:User {_id: "U1", name: "rowlock", age: 24}),
(quasar92:User {_id: "U2", name: "Quasar92", age: 29}),
(claire:User {_id: "U3", name: "claire", age: 35}),
(rowlock)-[:Follows {score: 2}]->(quasar92),
(quasar92)-[:Follows {score: 3}]->(claire)
在带量词部分之外引用
当组变量在其声明的带量词路径的可重复部分之外被引用时,它表示一个点或边的列表。
以下查询中,变量a和b分别代表匹配路径中的点列表,而非单个点:
MATCH p = ((a)-[]->(b)){1,2}
RETURN p, a, b
结果:
| p | a | b |
|---|---|---|
 |
[(:User {_id:"U2", name:"Quasar92", age:29})] | [(:User {_id:"U3", name:"claire", age:35})] |
 |
[(:User {_id:"U1", name:"rowlock", age:24})] | [(:User {_id:"U2", name:"Quasar92", age:29})] |
 |
[(:User {_id:"U1", name:"rowlock", age:24}), (:User {_id:"U2", name:"Quasar92", age:29})] | [(:User {_id:"U2", name:"Quasar92", age:29}), (:User {_id:"U3", name:"claire", age:35})] |
要聚合组变量,可使用FOR语句将其展开为单独的记录:
MATCH path = ()-[edges]->{1,2}()
CALL (path, edges) {
FOR edge IN edges
RETURN sum(edge.score) AS scores
}
FILTER scores > 2
RETURN path, scores
结果:
| p | scores |
|---|---|
 |
3 |
 |
5 |
以下查询有语法错误,因为a和b是列表:
MATCH p = ((a)-[]->(b)){1,2}
WHERE a.age < b.age
RETURN p
在带量词部分内部引用
只有当组变量在其声明的带量词路径的可重复部分内部被引用时,才具有单引用度。
以下查询中,a和b引用单个点,在路径匹配过程中,会对每对点a和b评估条件 a.age < b.age:
MATCH p = ((a)-[]->(b) WHERE a.age < b.age){1,2}
RETURN p
结果:p