HDC
概述
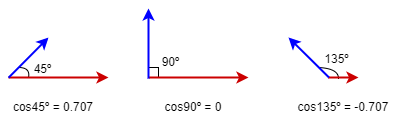
在余弦相似度(Cosine Similarity)中,数据对象被视为矢量,它使用两个矢量之间夹角的余弦值来表示它们之间的相似性。在图中,指定节点的N个数值属性(特征)构成N维矢量,如果两个节点的矢量相似,则认为它们相似。
余弦相似度的取值范围-1到1;1意味着两个向量的方向完全一致,-1意味着两个向量的方向正好相反。
在二维空间中,两个向量A(a1, a2)和 B(b1, b2)的余弦相似度计算公式为:
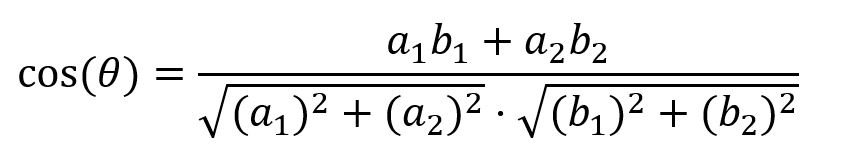
在三维空间中,两个向量A(a1, a2, a3)和B(b1, b2, b3)的余弦相似度计算公式为:
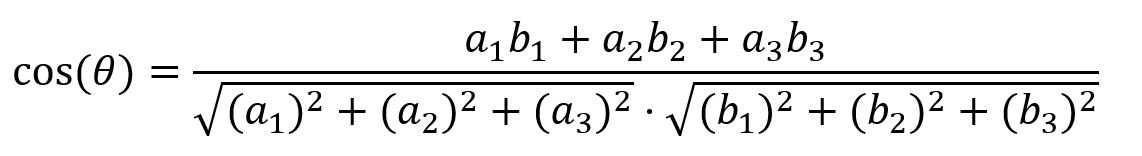
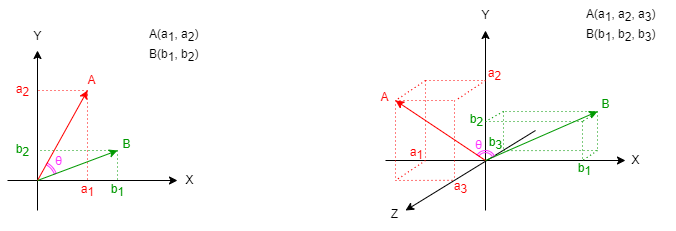
下图展示了2D和3D空间中矢量A和B之间的关系,以及它们之间夹角θ:
推广到N维空间,余弦相似度的计算公式如下:
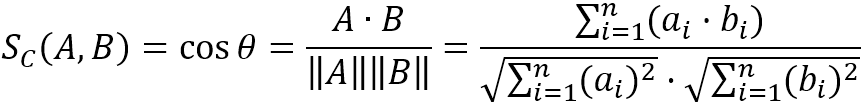
特殊说明
- 两个节点的余弦相似度理论上不依赖它们之间的连通性。
- 余弦相似度的值与向量长度无关,仅与向量方向相关。
示例图

在一个空图中运行以下语句定义图结构并插入数据:
ALTER GRAPH CURRENT_GRAPH ADD NODE {
product ({price int32, weight int32, width int32, height int32})
};
INSERT (:product {_id:"product1", price:50, weight:160, width:20, height:152}),
(:product {_id:"product2", price:42, weight:90, width:30, height:90}),
(:product {_id:"product3", price:24, weight:50, width:55, height:70}),
(:product {_id:"product4", price:38, weight:20, width:32, height:66});
create().node_schema("product");
create().node_property(@product, "price", int32).node_property(@product, "weight", int32).node_property(@product, "width", int32).node_property(@product, "height", int32);
insert().into(@product).nodes([{_id:"product1", price:50, weight:160, width:20, height:152}, {_id:"product2", price:42, weight:90, width:30, height:90}, {_id:"product3", price:24, weight:50, width:55, height:70}, {_id:"product4", price:38, weight:20, width:32, height:66}]);
创建HDC图
将当前图集全部加载到HDC服务器hdc-server-1上,并命名为 my_hdc_graph:
CREATE HDC GRAPH my_hdc_graph ON "hdc-server-1" OPTIONS {
nodes: {"*": ["*"]},
edges: {"*": ["*"]},
direction: "undirected",
load_id: true,
update: "static"
}
hdc.graph.create("my_hdc_graph", {
nodes: {"*": ["*"]},
edges: {"*": ["*"]},
direction: "undirected",
load_id: true,
update: "static"
}).to("hdc-server-1")
参数
算法名:similarity
| 参数名 | 类型 | 规范 | 默认值 | 可选 | 描述 | |
|---|---|---|---|---|---|---|
ids/uuids |
_id/_uuid |
是 | 通过_id或_uuid指定参与计算的第一组点;若未设置,则图中所有点均参与计算 |
算法支持两种计算模式:
|
||
ids2/uuids2 |
_id/_uuid |
是 | 通过_id或_uuid指定参与计算的第二组点。如果仅设置ids2/uuids2(并未设置ids/uuids2),算法不返回结果 |
|||
type |
String | cosine |
cosine |
否 | 指定待计算的相似度类型;计算余弦相似度时,设置为cosine |
|
node_schema_property |
[]"<@schema.?><property>" |
否 | 指定构成向量的数值类型点属性;所有指定的属性必须属于同一个标签(Schema) | |||
return_id_uuid |
String | uuid,id,both |
uuid |
是 | 在结果中使用_uuid、_id或同时使用两者来表示点 |
|
order |
String | asc,desc |
是 | 根据similarity分值对结果排序 |
||
limit |
Integer | ≥-1 | -1 |
是 | 限制返回的结果数。-1表示返回所有结果 |
|
top_limit |
Integer | ≥-1 | -1 |
是 | 在选拔模式下,限制ids/uuids中每个节点返回的结果数。-1表示返回所有相似度大于0的结果。配对模式下,该参数不生效 |
|
文件回写
CALL algo.similarity.write("my_hdc_graph", {
return_id_uuid: "id",
ids: "product1",
ids2: ["product2", "product3", "product4"],
node_schema_property: ["price", "weight", "width", "height"],
type: "cosine"
}, {
file: {
filename: "cosine"
}
})
algo(similarity).params({
projection: "my_hdc_graph",
return_id_uuid: "id",
ids: "product1",
ids2: ["product2", "product3", "product4"],
node_schema_property: ["price", "weight", "width", "height"],
type: "cosine"
}).write({
file: {
filename: "cosine"
}
})
结果:
_id1,_id2,similarity
product1,product2,0.986529
product1,product3,0.878858
product1,product4,0.816876
完整返回
CALL algo.similarity.run("my_hdc_graph", {
return_id_uuid: "id",
ids: ["product1","product2"],
ids2: ["product2","product3","product4"],
node_schema_property: ["price", "weight", "width", "height"],
type: "cosine"
}) YIELD cs
RETURN cs
exec{
algo(similarity).params({
return_id_uuid: "id",
ids: ["product1","product2"],
ids2: ["product2","product3","product4"],
node_schema_property: ["price", "weight", "width", "height"],
type: "cosine"
}) as cs
return cs
} on my_hdc_graph
结果:
| _id1 | _id2 | similarity |
|---|---|---|
| product1 | product2 | 0.986529 |
| product1 | product3 | 0.878858 |
| product1 | product4 | 0.816876 |
| product2 | product3 | 0.934217 |
| product2 | product4 | 0.881988 |
流式返回
CALL algo.similarity.stream("my_hdc_graph", {
return_id_uuid: "id",
ids: ["product1", "product3"],
node_schema_property: ["price", "weight", "width", "height"],
type: "cosine",
top_limit: 1
}) YIELD top
RETURN top
exec{
algo(similarity).params({
return_id_uuid: "id",
ids: ["product1", "product3"],
node_schema_property: ["price", "weight", "width", "height"],
type: "cosine",
top_limit: 1
}).stream() as cs
return cs
} on my_hdc_graph
结果:
| _id1 | _id2 | similarity |
|---|---|---|
| product1 | product2 | 0.986529 |
| product3 | product2 | 0.934217 |