概述
使用语句find().nodes()可以从当前图集获取符合过滤条件的点。
语法
find().nodes(<filter?>)
- 语句别名:类型为
NODE;默认名称为nodes - 方法:
方法 |
参数 |
描述 | 可选 |
别名类型 |
|---|---|---|---|---|
nodes() |
<filter?> |
将过滤条件包裹在{}中,或使用别名指定待获取的点。留空时会作用在所有点上 |
否 | N/A |
limit() |
<N> |
限制语句每次执行返回的点数量(N≥-1);-1表示返回所有点 |
是 | N/A |
示例图集
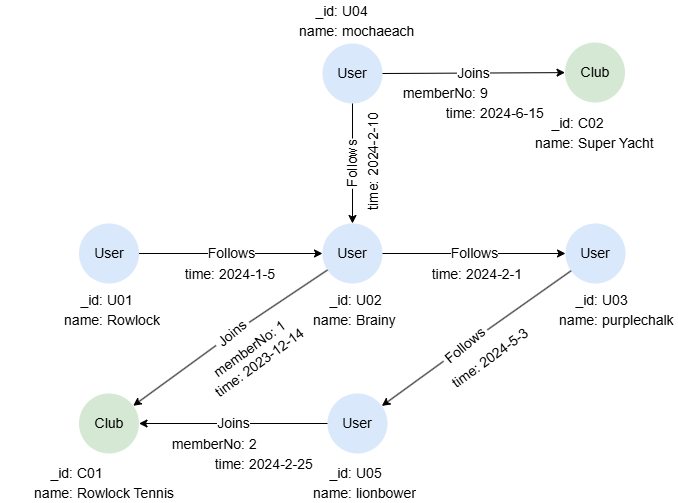
在一个空图集中,逐行运行以下语句,创建示例图集:
create().node_schema("User").node_schema("Club").edge_schema("Follows").edge_schema("Joins")
create().node_property(@User, "name").node_property(@Club, "name").edge_property(@Follows, "time", datetime).edge_property(@Joins, "memberNo", uint32).edge_property(@Joins, "time", datetime)
insert().into(@User).nodes([{_id:"U01", name:"Rowlock"},{_id:"U02", name:"Brainy"},{_id:"U03", name:"purplechalk"},{_id:"U04", name:"mochaeach"},{_id:"U05", name:"lionbower"}])
insert().into(@Club).nodes([{_id:"C01", name:"Rowlock Tennis"},{_id:"C02", name:"Super Yacht"}])
insert().into(@Follows).edges([{_from:"U01", _to:"U02", time:"2024-1-5"},{_from:"U02", _to:"U03", time:"2024-2-1"},{_from:"U04", _to:"U02", time:"2024-2-10"},{_from:"U03", _to:"U05", time:"2024-5-3"}])
insert().into(@Joins).edges([{_from:"U02", _to:"C01", memberNo:1, time:"2023-12-14"},{_from:"U05", _to:"C01", memberNo:2, time:"2024-2-25"},{_from:"U04", _to:"C02", memberNo:9, time:"2024-6-15"}])
找所有点
获取所有点:
find().nodes() as n
return n{*}
结果:n
| _id | _uuid | schema | values |
|---|---|---|---|
| U05 | Sys-gen | User | {name: "lionbower"} |
| U04 | Sys-gen | User | {name: "mochaeach"} |
| U03 | Sys-gen | User | {name: "purplechalk"} |
| U02 | Sys-gen | User | {name: "Brainy"} |
| U01 | Sys-gen | User | {name: "Rowlock"} |
| C02 | Sys-gen | Club | {name: "Super Yacht"} |
| C01 | Sys-gen | Club | {name: "Rowlock Tennis"} |
根据schema找点
获取schema为Club的点:
find().nodes({@Club}) as n
return n{*}
结果:n
| _id | _uuid | schema | values |
|---|---|---|---|
| C02 | Sys-gen | Club | {name: "Super Yacht"} |
| C01 | Sys-gen | Club | {name: "Rowlock Tennis"} |
获取schema为Club或User的点:
find().nodes({@Club || @User}) as n
return n{*}
结果:n
| _id | _uuid | schema | values |
|---|---|---|---|
| U05 | Sys-gen | User | {name: "lionbower"} |
| U04 | Sys-gen | User | {name: "mochaeach"} |
| U03 | Sys-gen | User | {name: "purplechalk"} |
| U02 | Sys-gen | User | {name: "Brainy"} |
| U01 | Sys-gen | User | {name: "Rowlock"} |
| C02 | Sys-gen | Club | {name: "Super Yacht"} |
| C01 | Sys-gen | Club | {name: "Rowlock Tennis"} |
根据属性找点
在过滤条件中,属性可与schema共同使用,也可独立使用。独立使用时,适用于所有具备该属性的点,而不论其schema。特别注意,系统属性_id和_uuid是唯一标识符,所以无法与schema共同使用(如@User._id)。
获取@User下name属性为Rowlock的点:
find().nodes({@User.name == "Rowlock"}) as n
return n._id
结果:
| n._id |
|---|
| U01 |
获取name属性包含Rowlock的点:
find().nodes({name contains "Rowlock"}) as n
return n._id
结果:
| n._id |
|---|
| C01 |
| U01 |
获取_id为U01或U02的点:
find().nodes({_id in ["U01", "U02"]}) as n
return n{*}
结果:n
| _id | _uuid | schema | values |
|---|---|---|---|
| U02 | Sys-gen | User | {name: "Brainy"} |
| U01 | Sys-gen | User | {name: "Rowlock"} |
使用默认别名
在find().nodes()语句中,可使用默认别名nodes,无需显式声明。
获取所有点并返回其name(同时默认返回schema和系统属性):
find().nodes()
return nodes{name}
结果:nodes
| _id | _uuid | schema | name |
|---|---|---|---|
| U05 | Sys-gen | User | lionbower |
| U04 | Sys-gen | User | mochaeach |
| U03 | Sys-gen | User | purplechalk |
| U02 | Sys-gen | User | Brainy |
| U01 | Sys-gen | User | Rowlock |
| C02 | Sys-gen | Club | Super Yacht |
| C01 | Sys-gen | Club | Rowlock Tennis |
限制点数量
紧跟在find().nodes()语句之后使用LIMIT语句,可以限制传递给后续语句的点数。
获取任意3个@User点:
find().nodes({@User}) as user limit 3
return user.name
结果:
| user.name |
|---|
| mochaeach |
| Brainy |
| Rowlock |
使用limit()
在此查询中,find().nodes()语句会执行两次,每次使用id中的一条记录。由于使用了limit()方法,每次只返回一个点:
uncollect ["U02", "U03"] as id
call {
with id
find().nodes({_id > id}).limit(1) as n
return n
}
return n{*}
结果:n
| _id | _uuid | schema | name |
|---|---|---|---|
| U05 | Sys-gen | User | lionbower |
| U05 | Sys-gen | User | lionbower |
使用前缀OPTIONAL
在此查询中,find().nodes()语句会执行三次,每次使用ID中的一条记录。使用前缀OPTIONAL后,如果执行过程中未找到结果,查询将返回null:
uncollect ["U01", "U22", "C01"] as ID
optional find().nodes({_id == ID}) as n
return n.name
结果:
| n.name |
|---|
| Rowlock |
null |
| Rowlock Tennis |
如果不使用前缀OPTIONAL,只会返回两条记录:
uncollect ["U01", "U22", "C01"] as ID
find().nodes({_id == ID}) as n
return n.name
结果:
| n.name |
|---|
| Rowlock |
| Rowlock Tennis |