概述
使用语句GROUP BY可根据分组键对数据分组。若有多个分组键出现,则分组操作从左到右依次执行:首先根据第一个分组键分组,然后在每个组内按第二个分组键分组,以此类推。
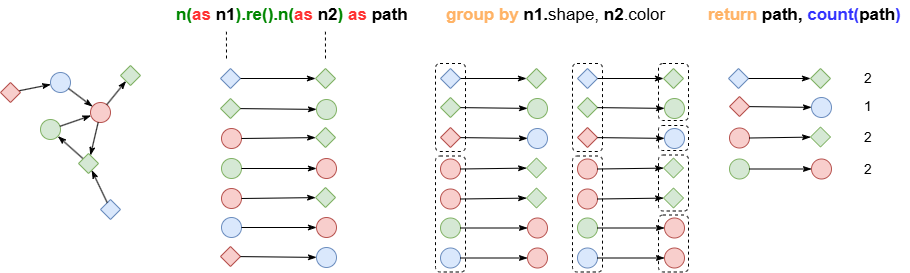
分组完成后,每组仅保留一条记录,其他记录会被舍弃。若在分组后立刻使用聚合函数,如sum()、avg()和count(),则函数会计算各组内的所有记录。
语法
GROUP BY <key1> as <alias1?>, <key2?> as <alias2?>, ...
WITH ...
详情
<key>:分组键,引用了之前语句中声明的别名。<alias?>:为分组键声明的别名;可省略。- 语句
WITH需紧跟在GROUP BY之后,以扩展必要别名的作用域,并在分组内执行聚合操作。
示例图集
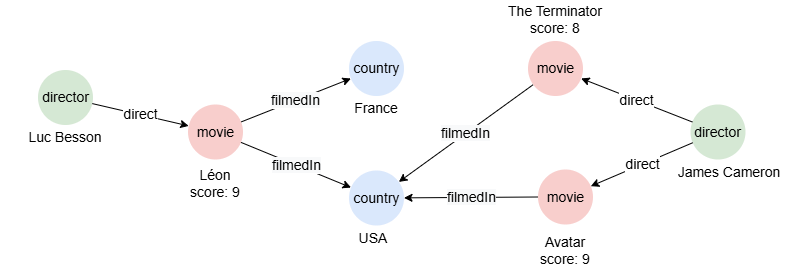
在一个空图集中,逐行运行以下语句,创建示例图集:
create().node_schema("country").node_schema("movie").node_schema("director").edge_schema("filmedIn").edge_schema("direct")
create().node_property(@*, "name").node_property(@movie, "score", float)
insert().into(@country).nodes([{_id:"C1", name:"France"}, {_id:"C2", name:"USA"}])
insert().into(@movie).nodes([{_id:"M1", name:"Léon", score: 9}, {_id:"M2", name:"The Terminator", score: 8}, {_id:"M3", name:"Avatar", score: 9}])
insert().into(@director).nodes([{_id:"D1", name:"Luc Besson"}, {_id:"D2", name:"James Cameron"}])
insert().into(@filmedIn).edges([{_from:"M1", _to:"C1"}, {_from:"M1", _to:"C2"}, {_from:"M2", _to:"C2"}, {_from:"M3", _to:"C2"}])
insert().into(@direct).edges([{_from: "D1", _to: "M1"}, {_from: "D2", _to: "M2"}, {_from: "D2", _to: "M3"}])
分组
查找电影并根据其score分组:
find().nodes({@movie}) as m
group by m.score
with m
return table(m.name, m.score)
分组后,仅为每个score值保留一条记录:
| m.name | m.score |
|---|---|
| The Terminator | 8.000000 |
| Avatar | 8.000000 |
查找连接@movie与@director的路径,再根据导演分组:
n({@movie}).e().n({@director} as d) as p
group by d
with d, p
return p{*}
分组后,仅为每个导演保留一条路径:
结果:p

组内聚合
查找连接@movie与@director的路径,并统计每个导演执导的电影数:
n({@movie}).e().n({@director} as d)
group by d
with d, count(d) as cnt
return table(d.name, cnt)
聚合函数count()作用于每组的所有记录上:
| d.name | cnt |
|---|---|
| James Cameron | 2 |
| Luc Besson | 1 |
多级分组
查找连接@country、@movie和@director的路径,然后根据国家和导演分组,并计算各组内的电影数量:
n({@country} as c).e().n({@movie}).e().n({@director} as d) as p
group by c, d
with c, d, count(p) as cnt
return table(c.name, d.name, cnt)
结果:
| c.name | d.name | cnt |
|---|---|---|
| USA | James Cameron | 2 |
| USA | Luc Besson | 1 |
| France | Luc Besson | 1 |