概述
图平均距离是指图中所有节点对之间最短距离的平均值,可用来描述图的紧凑性。该概念早期曾用于评估建筑楼层设计和研究化学分子结构等,后来逐渐应用于计算机系统连通、通信网络的分析与设计中。
图平均距离的理论值可通过邻域函数求解。由于邻域函数在大型图上的计算非常耗费资源,于是产生了近似求解算法 ANF(Approximating the Neighbourhood Function)以及比 ANF 速度更快、线性可扩展性更好的算法 HyperANF。后者由意大利米兰大学信息科学系的 Paolo Boldi、Marco Rosa 和 Sebastiano Vigna 于 2011 年提出。
算法的相关资料如下:
- P. Boldi, M. Rosa, S. Vigna, HyperANF: Approximating the Neighbourhood Function of Very Large Graphs on a Budget (2011)
- P. Flajolet, É. Fusy, O. Gandouet, F. Meunier, HyperLogLog: the analysis of a near-optimal cardinality estimation algorithm (2007)
基本概念
图平均距离
根据图平均距离的定义,令 i、j 为同一连通分量中两个不同的点,d(i,j) 为 i、j 之间的距离(最短路径的长度/边数),k 为全图可连通的节点对的数量,则图平均距离可以表示为:
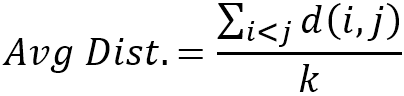
对上式中的 d(i,j) 按值进行统计,用正整数 t 表示 d(i,j) 的值,用 p(t) 表示图中所有距离为 t 的节点对的数量,便得到了图平均距离的另一种表达方式:
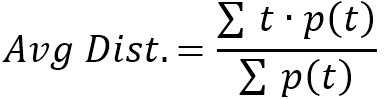
如下图所示,分别用两种方法计算图平均距离:(1+2+1+1)/4=1.25 或 (1*3+2*1)/4=1.25。

邻域函数
邻域函数(Neighbourhood Function)也称全图邻域函数,记作 N(t),表示给定某一距离 t 时,图中所有距离小于等于 t 的节点对数量;前文中提到的 p(t) 可以用邻域函数表示为 p(t) = N(t) - N(t-1)。
考虑与某节点 x 的距离小于等于 t 的节点(不同于 x)数量,并将之定义为节点邻域函数(Independent Neighbourhood Function),记作 Nx(t);节点邻域函数和全图邻域函数的关系为 N(t) = 1/2 · ∑ Nx(t)。

通过 Nx(2) 计算 N(2) = (2+3+4+3+2)/2 = 7 和通过 p(2) 计算 N(2) = p(2) + N(1) = 3 + 4 = 7 得到的结果一致。
至此,可以将图平均距离的求解转化为对 Nx(t) 的计算。
邻域集
如果用集合 B(x,t) 表示节点 x 在 t 步内可达的所有点(包含 x),并称之为 x 的 t 步邻域集,则有 Nx(t) = |B(x,t)| - 1;B(x,t) 可以通过自身迭代计算而得到,即 B(x,t) = ∪ B(y,t-1),其中 y 表示 x 的一步邻居。
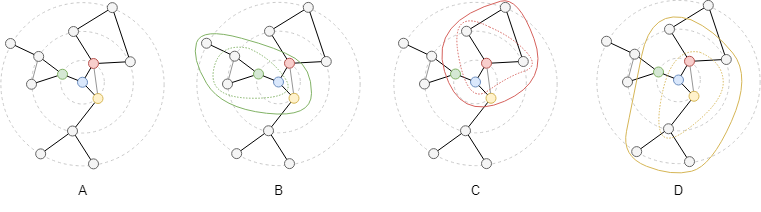
考查蓝色节点 x 的邻域,图 A 即为 B(x,3),蓝色节点的一步邻居为绿、红、黄三个点(分别记作 i、j、k);图 B、C、D 中的绿、红、黄色环内的点分别为 B(i,2)、B(j,2)、B(k,2),三个环取并集后得到的集合为全图,即 B(x,3) = B(i,2) ∪ B(j,2) ∪ B(k,2)。
根据邻域集的概念可知,Nx(t) 的计算在本质上是先求并集再求集合大小的过程,即将多个集合中的元素写成一个序列,再求该序列的基数。基数(Cardinality)是指一个序列中不重复的元素的个数。例如,已知两个集合 {1,3,4}、{4,5,1,7},将它们的元素写成序列 1,3,4,4,5,1,7,该序列的基数为 5,同时也是它们的并集 {1,3,4,5,7} 的元素个数。
以连通图为例,图平均距离可以用节点邻域集的大小 |B(x,t)| 来表示:
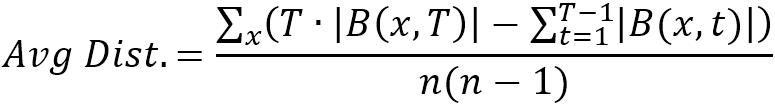
其中 T 为图中节点间最短距离的最大值,即图的直径;n 为图中节点的数量。
HyperLogLog
HyperLogLog 是一种基数估算方法,能在读取元素序列后统计出序列的基数。由于其在计算时所占用内存的大小为近乎线性的双对数 O(n·log(log n)),因此得名。
HyperLogLog 的工作原理如下:
1. 准备一个长度为 2b 的数组 M(初始时每个元素都为 -∞)。
2. 将序列中的每个元素值映射为一个足够长的二进制数列,用数列中的前 b 位所对应的整数值作为与该元素相对应的数组位置下标。
3. 从元素映射的二进制数列的第 b+1 位开始,观察第一个 1 出现在第几位,将这个位数记作 ρ(ρ 必为正整数),如果 ρ 比元素对应的数组位置上的值更大,则用 ρ 更新该数组位置上的值。
4. 所有元素读取完毕后,序列的基数通过数组 M 的值进行计算:
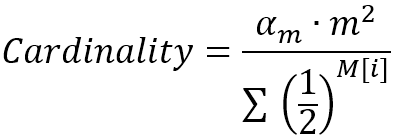
其中 m 为数组 M 的长度 2b,α 为 m 的函数:
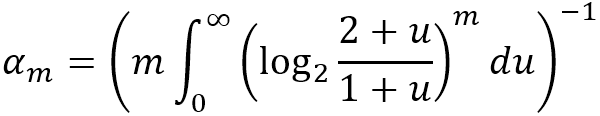
例如,当 b 取值 4 时,m 等于 16,α 等于 0.6731,如果 M 为 [1,3,1,2,3,3,6,4,3,1,3,2,3,2,1,2],基数为 45.0127 ≈ 45。
Ultipa 的图平均距离算法为图中每个节点 x 准备一个数组 M,用于计算该节点邻域集内的节点数 |B(x,t)|,则 n 个节点共需 n 个数组 M;令 C 为这些数组构成的 n × m 维的矩阵:

从 t = 1 开始,迭代计算 C(t);C(t) 中的每个 Mx 可根据 C(t-1) 中的多个 My 取同下标中的最大值而得出(y 为 x 的所有一步邻居)。循环迭代直至 C(t) 不再变化,或迭代轮数达到限制。
特殊处理
孤点、不连通图
孤点不与任何节点连通,不参与图平均距离的计算。
不连通图在其各个连通分量内部构成连通的节点对,所有这些节点对共同计算出图的平均距离。
自环边
节点的自环边不构成节点间的最短路径,因此不影响图平均距离的计算。
有向图
对于有向边,本算法会忽略边的方向,按照无向边进行计算。
结果和统计值
以下面的图为例,运行图平均距离算法,设置算法最大迭代 5 轮,数组 M 长度为 24,即 b = 4:
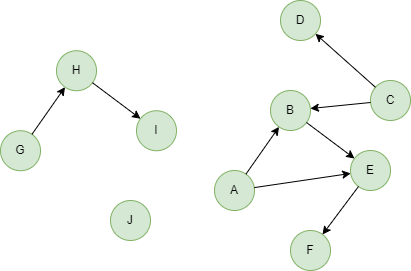
算法结果:无
算法统计值:估算的图平均距离 hyperANF_result
| hyperANF_result |
|---|
| 1.8471822653636683 |
注:本例图平均距离精确值为 33/18 = 1.833333。
命令和参数配置
- 命令:
algo(hyperANF) params()参数配置项如下:
| 名称 | 类型 |
默认值 |
规范 | 描述 |
|---|---|---|---|---|
| loop_num | int | / | >=1,必填 | 算法的最大迭代轮数 |
| register_num | int | / | [4,30],必填 | 用 HyperLogLog 估算基数时,决定数组 M 长度的幂运算指数 b 的值 |
算法执行
任务回写
1. 文件回写
算法不支持文件回写。
2. 属性回写
算法不支持属性回写。
3. 统计回写
算法不支持统计回写。
直接返回
| 别名序号 | 类型 | 描述 | 列名 |
|---|---|---|---|
| 0 | KV | 图平均距离 | hyperANF_result |
示例:计算图平均距离,设置算法最大迭代 5 轮,数组 M 长度为 24,即 b = 4,将算法统计值定义为别名 distance 并返回
algo(hyperANF).params({
loop_num: 5,
register_num: 4
}) as distance
return distance
流式返回
算法不支持流式返回。
实时统计
| 别名序号 | 类型 | 描述 | 列名 |
|---|---|---|---|
| 0 | KV | 图平均距离 | hyperANF_result |
示例:计算图平均距离,设置算法最大迭代 5 轮,数组 M 长度为 24,即 b = 4,将算法统计值定义为别名 distance 并返回
algo(hyperANF).params({
loop_num: 5,
register_num: 4
}).stats() as distance
return distance