本文介绍如何通过 Manager 保存 Ultipa 图数据库的服务器信息、登录 Ultipa 图数据库以及切换服务器连接。
工具介绍
Ultipa Manager 是和 Ultipa 图数据配套的网页端应用,提供了 VS Code 风格的 UQL 编辑工具以及 UQL 结果分窗,用户可以轻松地编写、发送 UQL 到指定的服务器,瞬息间即可感受生动形象的查询结果(2D/3D 样式)。
Ultipa Manager 还提供了算法可视化、图数据文件导入/导出、插件热安装等功能,是一个对图数据库、服务器集群、数据集、模式和用户权限等的一站式解决方案。
Manager 可保存数据库服务器的登录信息,以简化用户每次连接 Utlipa 图数据库的操作。用户可以在自己的 Manager 账号中保存多个服务器信息,使用时根据需要随时切换。
连接服务器后,Manager 会监听集群中各节点的工作状态,如果发现当前连接的节点下线,Manager 会自动切换至集群中其它可用节点。
如何连接数据库
通过 Manager 连接 Utlipa 图数据库,不需要编写任何代码,只需完成以下三步:
1. 登录 Manager
在 Manager 首页用账号和密码登录,或创建新账号。
推荐使用谷歌 Chrome 浏览器。
2. 保存服务器信息
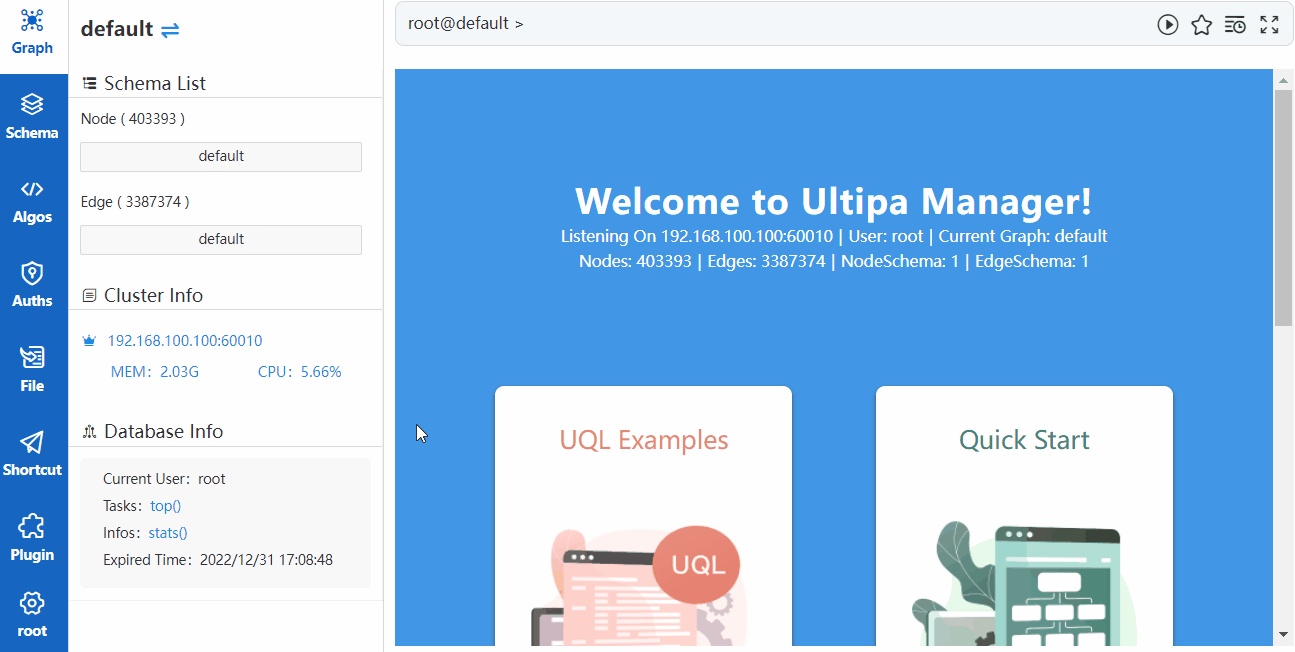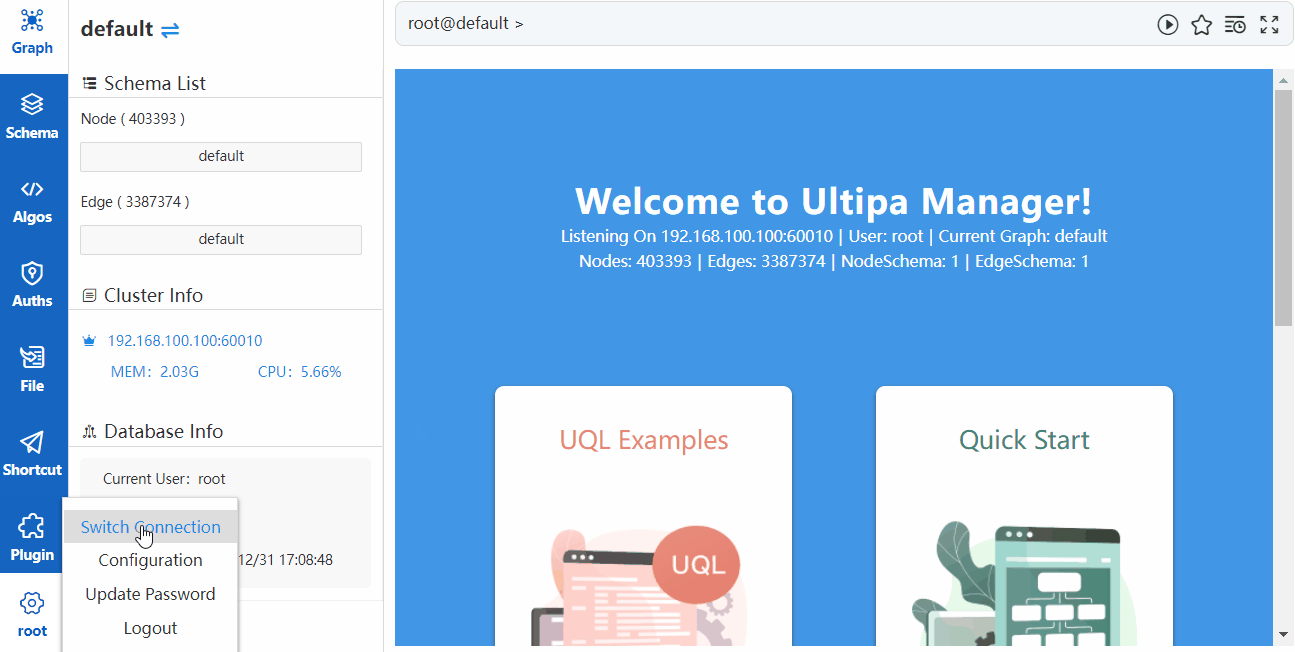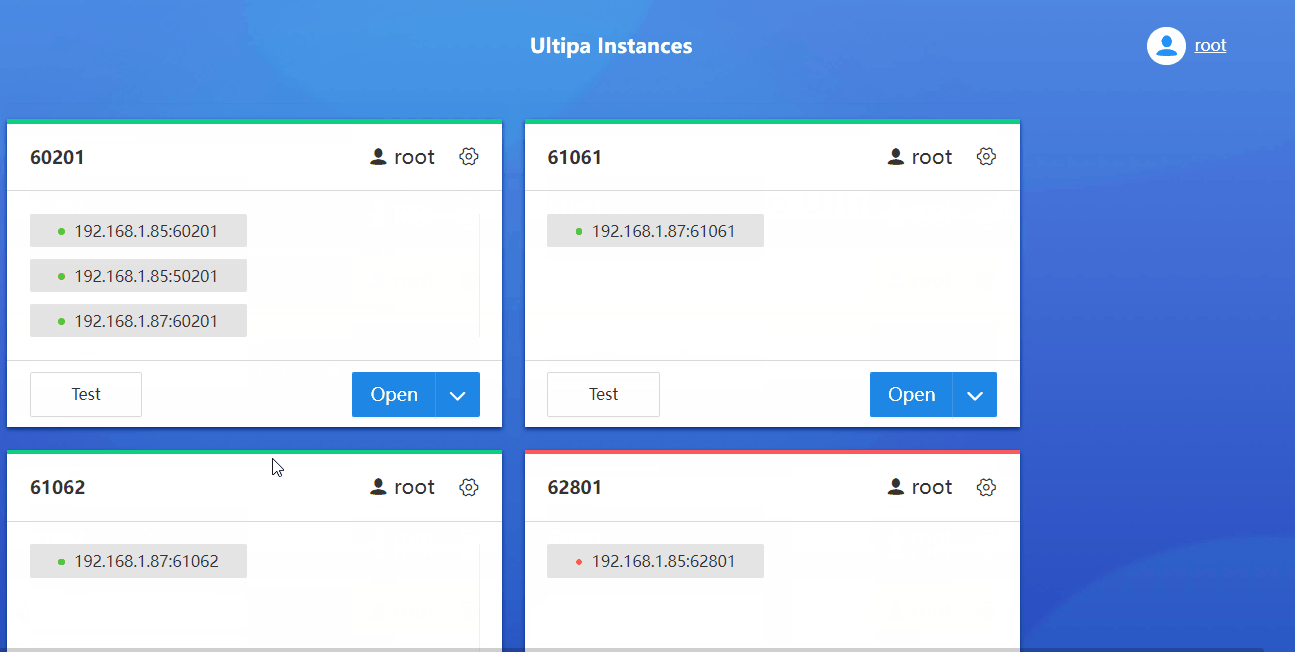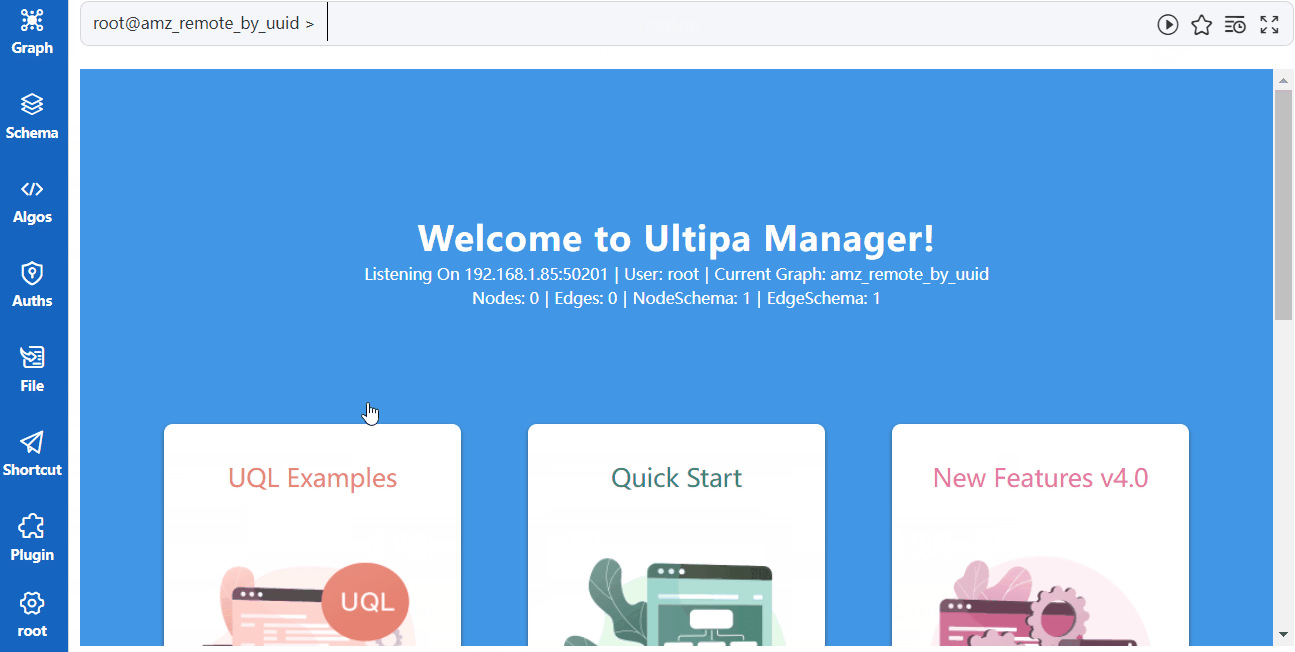
登录 Manager 后,新建一个服务器连接,需填写数据库服务器(单机、集群均可)的地址、用户名和密码,连接的名字用户可自定义。

若要添加的是服务器集群地址,集群的多个节点地址用英文逗号隔开。服务器的用户名和密码由数据库管理员提供。
3. 测试并连接
保存连接后,Manager 会自动测试连接,连接卡片顶部为绿色时表示可以连接。点击“测试”按钮可手动测试连接,点击“打开”按钮即可连接并开始操作该数据库。
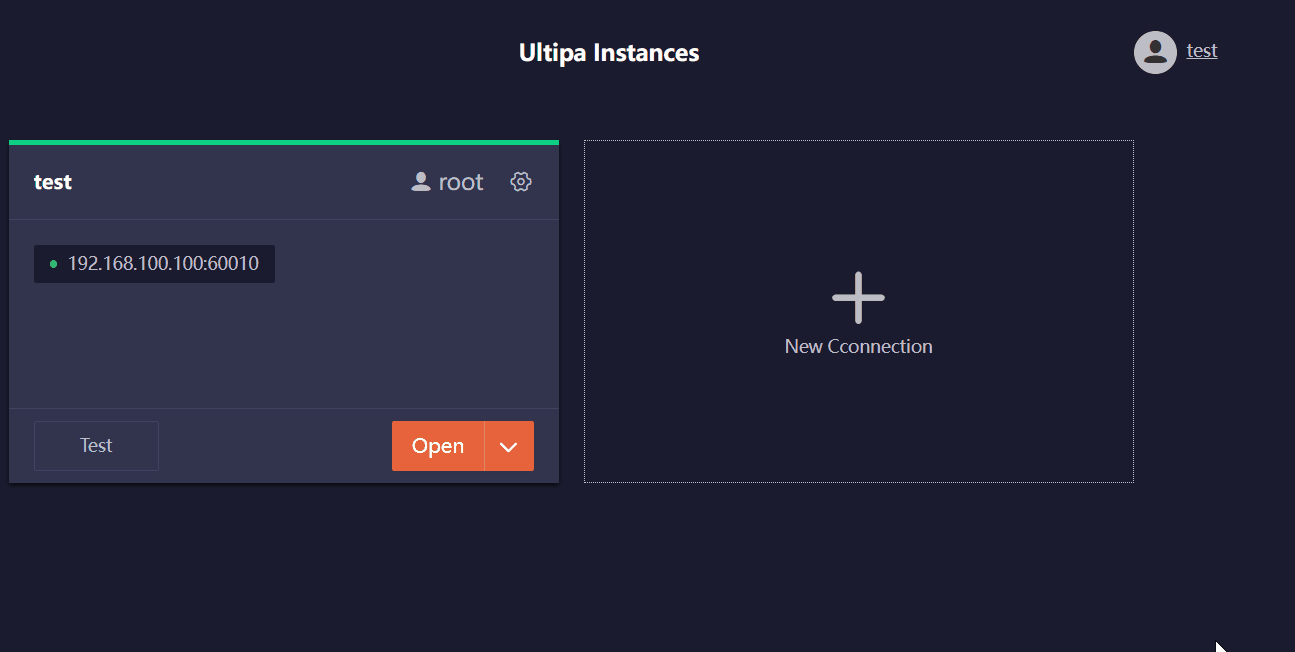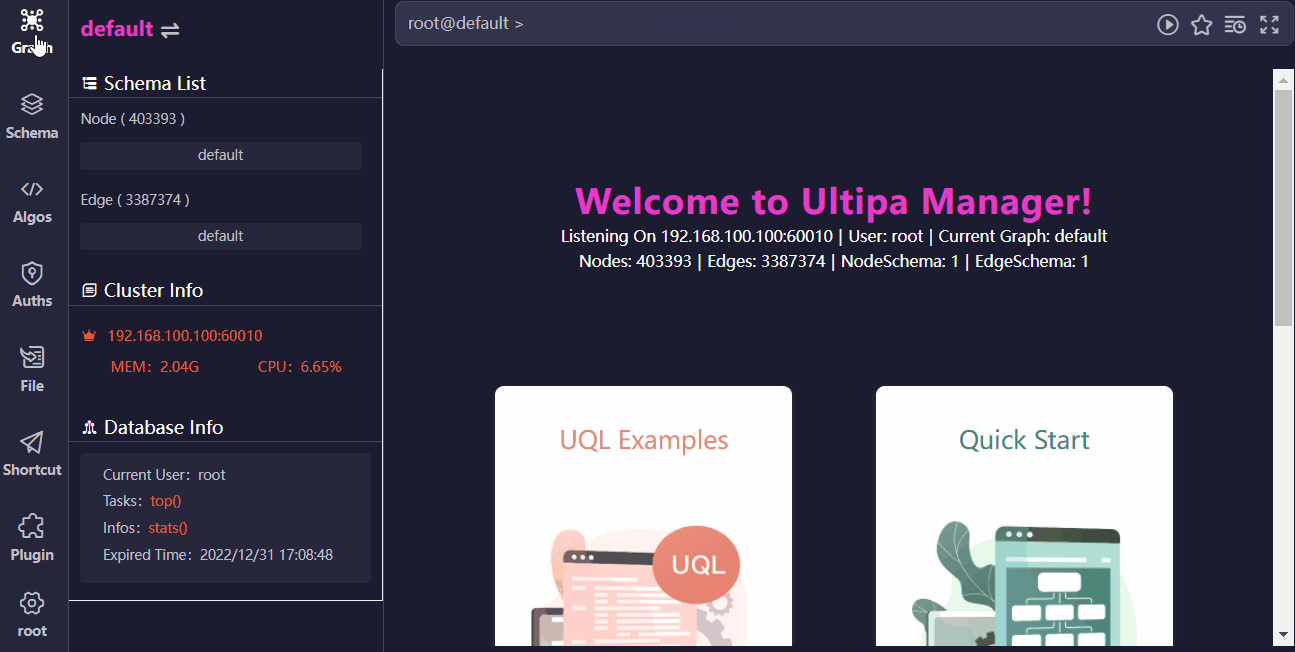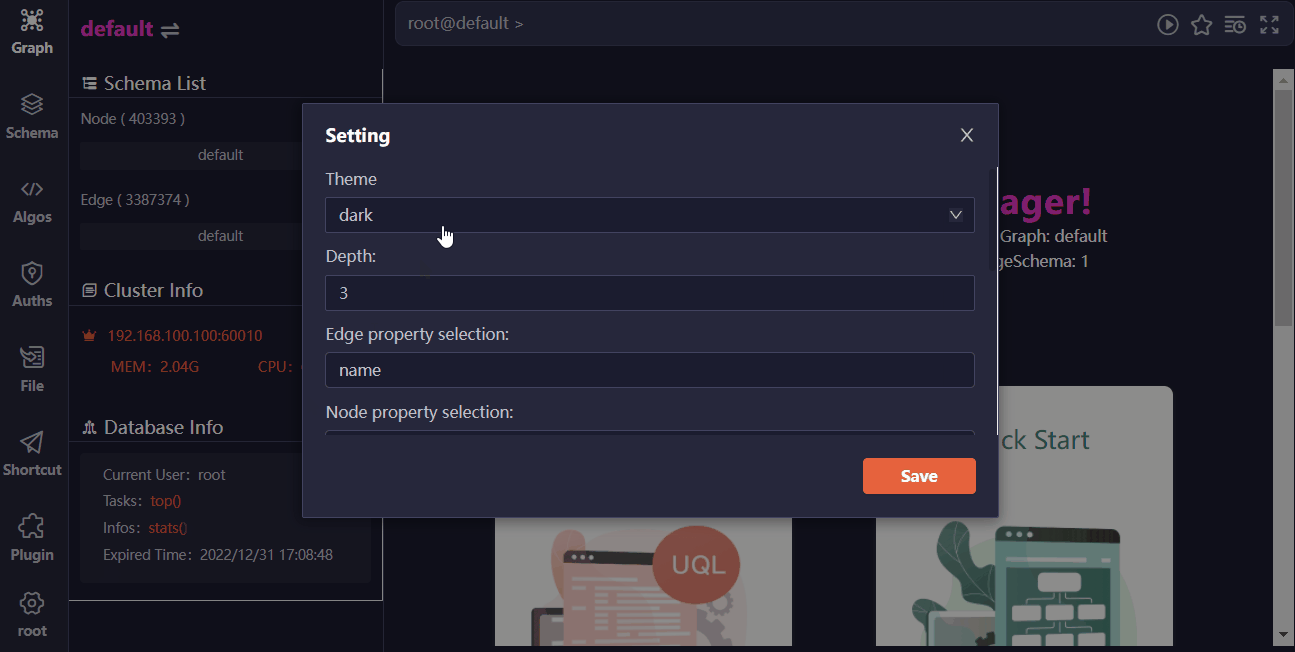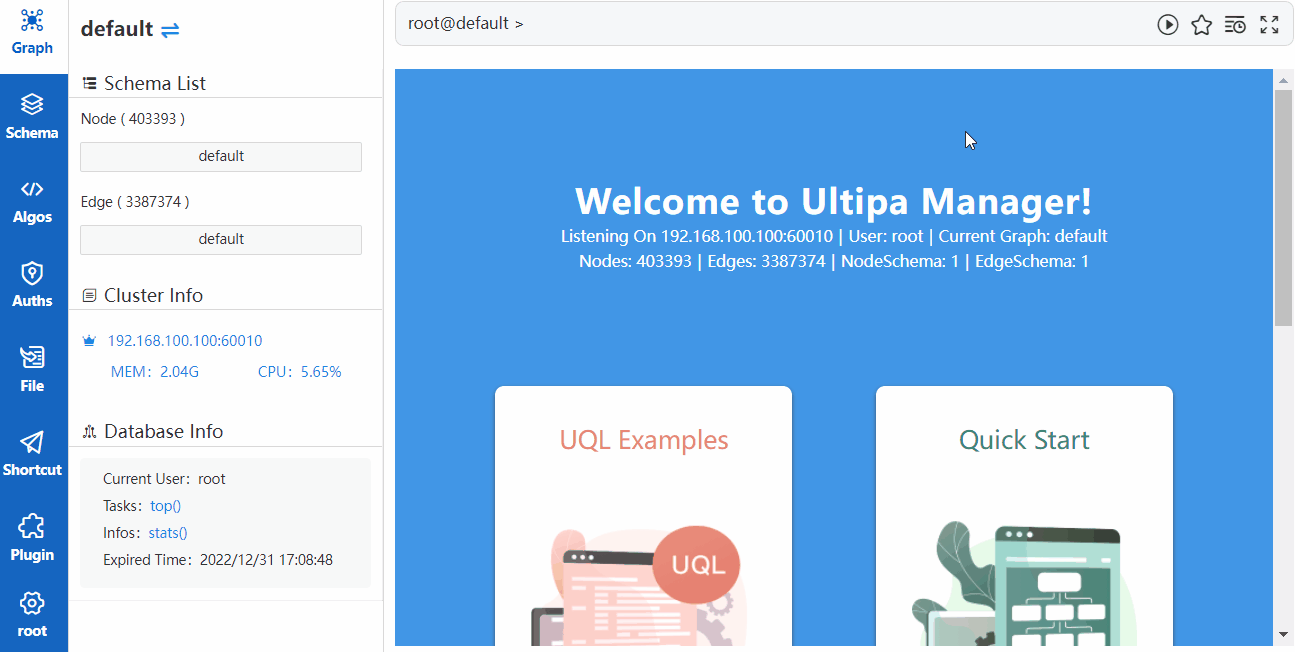
连接一个数据库服务器(集群)后,可以查看当前服务器(集群)信息,也可以在设置中修改 Manager 的显示风格。
如果 Manager 账号中保存了多个数据库的信息,可以随时根据需要进行切换。